
在Kubernetes叢集中部署Heapster_Kubernetes中文社群
背景
公司的容器雲平臺需要新增應用的自動擴縮容的功能,以便能夠更加智慧化的對應用進行管理。
Kubernetes官方提供了HPA(Horizontal Pod Autoscaling)資源物件。要讓我們部署的應用做到自動的水平的(水平指的是增減Pod副本數量)進行擴縮容,我們只需要在Kubernetes叢集中建立HPA資源物件,然後讓該資源物件關聯某一需要進行自動擴縮容的應用即可。
HPA預設的是以Pod平均CPU利用率作為度量指標,也就是說,當應用Pod的平均CPU利用率高於設定的閾值時,應用就會增加Pod的數量。CPU利用率的計算公式是:Pod當前CPU的使用量除以它的Pod Request(這個值是在部署
Pod平均CPU利用率的計算需要知道每個Pod的CPU使用量,目前是通過查詢Heapster擴充套件元件來得到這個值,所以需要安裝部署Heapster。
接下來我就將我們在Kubernetes叢集中部署Heapster的過程記錄下來,也會描述我們在部署過程中遇到的問題以及解決的方法,希望能夠幫助到也準備在Kubernetes叢集中部署Heapster的朋友。
Heapster成功部署之後,我們使用了效能測試工具對http應用做了壓力測試,以觀察HPA進行自動擴縮容時的實際效果。
部署過程
1
首先,我們在github中搜索Heapster,會找到Kubernetes中的Heapster庫:
將這個庫clone到叢集的master節點中。
在Heapster目錄下執行命令kubectl create -f deploy/kube-config/standalone/Heapster-controller.yaml
理論上建立完成後會啟動三個資源物件,deployment、service、serviceaccount,此時Heapster應該就能夠為HPA提供CPU的使用量了。
此時為驗證Heapster是否可用,在叢集中部署一個HPA資源物件,關聯某個應用,並設定閾值為90:


檢視這個HPA時我們可以看到,CURRENT的CPU利用率為,也就是說,HPA沒能從Heapster中取得CPU的使用量。
於是,我們用kubectl get pod –namespace=kube-system命令檢視Heapster的pod的執行情況,發現是拉取映象失敗的緣故。
開啟部署Heapster的yaml檔案如下:
apiVersion: v1 kind: ServiceAccount metadata: name: Heapster namespace: kube-system --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: Heapster namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: Heapster spec: serviceAccountName: Heapster containers: - name: Heapster image: gcr.io/google_containers/Heapster-amd64:v1.4.0 imagePullPolicy: IfNotPresent command: - /Heapster - --source=kubernetes:https://kubernetes.default --- apiVersion: v1 kind: Service metadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: Heapster name: Heapster namespace: kube-system spec: ports: - port: 80 targetPort: 8082 selector: k8s-app: Heapster
可以看到23行,映象是要從谷歌的gcr.io映象倉庫中拉取的,由於我們的叢集伺服器不能連通外網,所以映象當然就拉取失敗了。
2
此時,我們使用之前使用過的自己倉庫中的Heapster映象來替代此yaml檔案中使用的映象。
清除剛才部署失敗的資源物件後再次在Heapster目錄下使用命令:kubectl create -f deploy/kube-config/standalone/Heapster-controller.yaml
這個時候發現對應的資源物件都建立成功了,而且pod也成功運行了。
此時看HPA的情況如下:

此時問題沒有得到解決,雖然Heapster的pod執行起來了,但是HPA還是沒能取到CPU使用量的值。
現在的情況來看,此時還不能確定問題是在於Heapster安裝沒成功還是HPA沒能從Heapster中取得值。
所以,接下來就是要確定一下Heapster是否安裝成功了。
這個時候,我們想到去Heapster中的docs目錄下看看有沒有什麼debug的方法,也就是進入Heapster目錄下的docs中的debugging。
用curl命令對URL/api/v1/model/debug/allkeys 做取值,得到的結果如下:
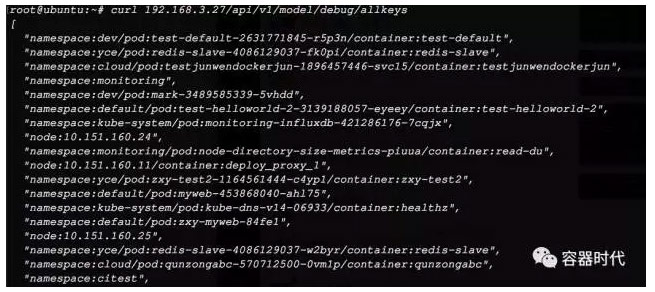
然後再用kubectl describe hpa yce –namespace=yce命令來檢視HPA資源物件的詳情

Message中顯示,從Heapster獲取指標失敗。
此時結論就得出了,Heapster已經成功安裝,不過叢集無法從Heapster中獲取到監控資料。
好了,接下來我們決定再給Heapster換一個映象試試,有可能是我們的映象版本問題導致與Kubernetes叢集不能協同工作。
在docker hub中搜索到了版本為v1.2.0的Heapster映象,替換為此映象後再次建立資源物件。
3
建立成功後,驚喜出現了

可以看到,HPA已經可以從Heapster中取到值了。然後用kubectl top node命令檢視節點的指標,發現也可以取到值了。
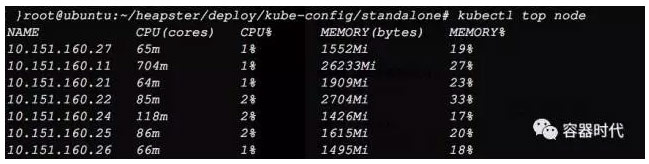
對HPA關聯的應用做壓力測試
理論上Heapster已經安裝成功。為了驗證HPA是否可用,我們寫了一個簡單的http程式,名為helloworldhey。該程式就是做了一個自增整型變數1000次的迴圈。
將該程式打包成映象,部署對應的deployment和service資源物件,然後在叢集外部通過暴露的節點埠用效能測試工具ab對其進行壓力測試。可以看到結果如下:

可以看到,我這裡設定的閾值為50%,也就是說,在平均CPU使用率超過50%時,HPA會對pod進行自動的擴容,也即是增加pod的數量,使增加後的pod總數量可以讓平均CPU使用率低於50%。可以看到此時的CPU使用率已經為110%,所以,理論上HPA應該自動的拉起2個pod來分擔CPU的使用量。看看pod的目前情況,結果如下:
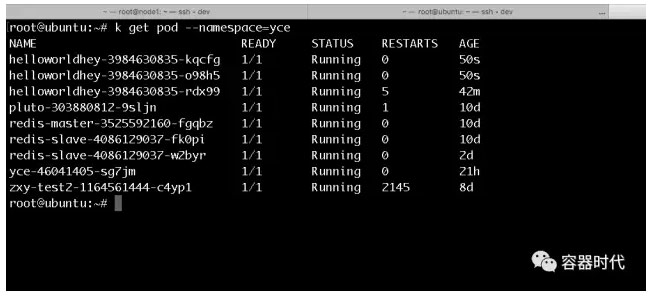
可以看到此時共有三個pod,與預期的結果相同。
不過,可能有人會有疑問,為什麼最初建立的pod會重啟多次?原因就在於Kubernetes在部署deployment時,每個pod都設定有requests與limits值,當該pod的CPU(或記憶體)使用量超過該limits值時,kubelet就會重啟這個pod,由於在壓力測試的開始時刻只有此一個pod,所以CPU使用量肯定是超過了這個limit值於是pod就被重啟了。
至此,heapter就被部署成功且可以正常使用了。

歡迎關注譯者微信公眾號