
opencv學習筆記——自己訓練人臉識別分類器
在使用opencv自帶的分類器haarcascade_frontalface_alt.xml進行人臉識別的基礎認識後,決定自己訓練一個分類器看一下效果。該過程大致可分為三個階段:樣本採集、分類器訓練和運用訓練好的分類器進行人臉檢測。
1、樣本的採集
在訓練前,我們需要進行正樣本及負樣本的採集。
正樣本採用的是ORL人臉資料庫中的部分影象,本次共選用63張影象,初始影象大小為92*112,但在訓練時出現了記憶體不足的問題,因此將其尺寸歸一化為20*20。部分截圖如下:

負樣本採用的是weizmann團隊http://www.wisdom.weizmann.ac.il/~vision/Seg_Evaluation_DB/dl.html 網站上的影象分割資料庫裡面的灰色影象,總共200幅圖片,大小大約在300*200畫素,截圖如下所示:

影象採集完畢後,將其分別放在兩個資料夾pos_img(正樣本)和neg_img(負樣本)下。再新建一個xml資料夾,xml資料夾存放後面訓練過程中產生的資料模型,最後opencv會將其轉換生成一個xml檔案,也就是最終的分類器。
然後,從OpenCv安裝目錄中查找出如下兩個exe可執行檔案:

opencv_createsamples.exe:用於建立樣本描述檔案,字尾名是.vec。專門為OpenCV訓練準備,只有正樣本需要,負樣本不需要。
opencv_haartraining.exe:是OpenCV自帶的一個工具,封裝了haar特徵提取以及adaboost分類器訓練過程。
一般來說,正負樣本數目比例為1:3時訓練結果較好,但是不是絕對。由於每個樣本的差異性不同等因素,所以沒有絕對的比例關係。但是負樣本需要比正樣本多,因為原則上說負樣本的多樣性越大越好,我們才能有效降低誤檢率,而不僅僅是通過正樣本的訓練讓其能識別物體。在本次訓練中,我選擇了63個正樣本和200個負樣本,均為灰度影象。
樣本準備完畢後,開啟Windows下的命令列視窗cmd,進入指定目錄下。
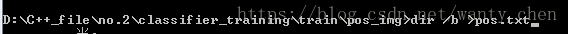
在當前pos_img目錄下生成一個pos.txt記錄所有圖片的名稱。

開啟該txt檔案,將pos.txt去掉,並將pgm 改為pgm 1 0 0 20 20。

這裡1表示當前圖片重複出現的次數是1, 0 0 20 20表示目標圖片大小是矩形框從(0,0)到(20,20)。
同理,進入neg_img目錄,生成neg.txt,然後開啟檔案去掉neg.txt,其餘不做改動。
結束後將pos.txt和neg.txt拷出,與opencv_createsamples.exe檔案放在一個目錄下:

2、使用opencv_createsamples.exe建立訓練需要的引數列表
Windows控制檯進入指定目錄下,我們之前已經在目錄下放了opencv_createsamples.exe檔案,在控制檯下輸入opencv_createsamples.exe可以得到各引數資訊:

在命令列視窗輸入:

則在當前目錄下,產生一個pos.vec檔案。

指令介紹:
-vec pos.vec:指定生成的檔案,最終生成的就是pos.vec;
-info pos_img\pos.txt:目標圖片描述檔案,在pos\pos.txt;
-bg neg_img\neg.txt:背景圖片描述檔案,在neg\neg.txt;
-w 20:輸出樣本的寬度,20;
-h 20:輸出樣本的高度,20;
-num 63:要產生的正樣本數量,63;
3、訓練模型
Windows控制檯進入指定目錄下,我們之前已經在目錄下放了opencv_haartraining.exe檔案,在控制檯下輸入opencv_haartraining.exe可以得到各引數資訊:
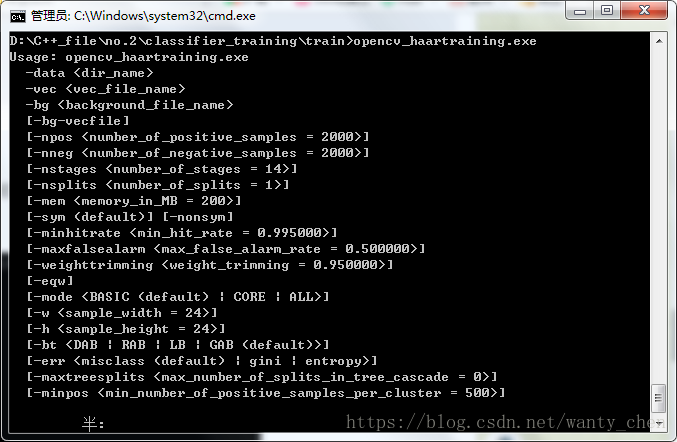
然後輸入指令進行訓練:

指令介紹:
-vec pos.vec:正樣本檔名;
-bg neg_img\neg.txt:背景描述檔案;
-data xml:指定存放訓練好的分類器的路徑名,也就是前面建立的xml資料夾;
-w 20:樣本圖片寬度,20;
-h 20:樣本圖片高度,20;
-mem 1024:提供的以MB為單位的記憶體,很明顯,這個值越大,提供的記憶體越多,運算也越快;
-npos 45:取45個正樣本,小於總正樣本數;
-neg 180:取180個負樣本,小於總負樣本數;
-nstages 5:指定訓練層數,層數越高耗時越長;
-nsplits 5:分裂子節點數目, 預設值 為2;(本來設定為5 ,但訓練時一直出差錯,改為預設值後可正常訓練)。
在這裡-npos -neg 兩個引數若直接與正負樣本總數相同,則在訓練過程中會出現錯誤:訓練中途,程式突然終止,提示"OpenCV Error: Assertion failed (elements_read == 1) in icvGetHaarTraininDataFromVecCallback, file ..\..\..\..\opencv\apps\haartraining\cvhaartraining.cpp, line 1861"。-npos的意思是每次訓練從.vec檔案中隨機選取npos個正樣本。由於存在虛警,在每一次訓練一個強分類器之後,會把那些分類錯誤的從整個樣本庫中剔除掉,總的樣本就剩下 CountVec = CountVec - (1 - minhitrate)* npos,在第二個強分類器的訓練過程中就是從剩下的Countvec抽樣,一直這樣進行nstage次,所以就有CountVec >= (npos + (nstages - 1)*(1 -minhitrate) * npos ) + nneg 。當把npos設定與vec中總樣本數相同時,第二個強分類器訓練時,必然就會報錯,提示樣本數不足。只要將取值改小即可。
接下來要做的就是等待訓練結束:


訓練過程引數解釋:

N:層數 %
SMP:樣本的使用率
F : +表示通過翻轉,否則是-
ST.THR : 分類器的閾值
HR:當前分類器 對正樣本識別正確的概率
FA:當前分類器 對負樣本識別錯誤的概率
EXP.ERR : 分類器的期望錯誤率
訓練結束後會在根目錄下生成xml.xml檔案,在xml資料夾下生成最終的分類器:

4、測試
用自己訓練的分類器替換opencv自帶的分類器進行人臉識別:
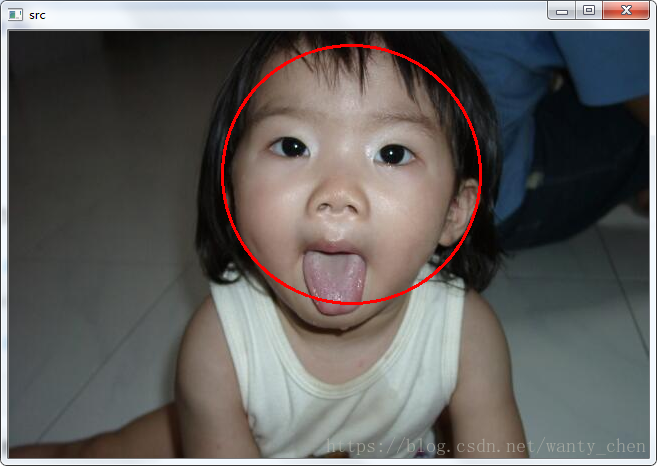

因為訓練的樣本過少,分類器的層數也不多,分類效果並不好,還有待提高。