
如何解決高併發下快取被擊穿的問題
背景:
在某些電商促消活動中需要搞活動,對某些頁面的訪問量(QPS)往往會非常高。如果直接讀資料庫,肯定DB會承受不住。那比較常見的方案就是讓大部分相同資訊的請求都儘可能壓在cache上來緩解DB的壓力,從而儘可能去滿足高併發訪問的需求
在一次具體的促銷過程中,當運營同學給廣大的消費者推了一條訊息:10點準時搶購一批遠低於市場價而且數量有限制促銷商品。(比如3K塊搶一臺蘋果手機之類的)。那使用者一收到這條簡訊就會在10點集中進入搶購頁面,結果持續幾分鐘內很多使用者就會進入會場,發現頁面異常並且伺服器瘋狂報警。
報警內容:cache異常。
由於cache有問題,直接走DB,結果導致DB壓力難以支撐,整個業務叢集處於雪崩
現在問題來了,什麼我們的cache會出問題?我們應該要如何避免cache出問題呢?
來看看cache出問題的原因
原因可能有這麼幾個:
1、快取伺服器自身有限流保持
快取伺服器數量 * 單機能夠承受的qps > 使用者最大的QPS 就會觸發限流保護
針對這個原因:可以做橫向擴容。加機器即可
2、使用者訪問過來cache伺服器集中打到一臺上面了。大流量並沒有按預期的那樣分攤到不同的cache機器上
導致出現單機熱點。(熱點資料)
針對這個原因:只要計算cache-hash演算法不出問題,那基本上可以做到快取的隨機分佈均勻的
3、快取裡面的value過大,導致雖然QPS不高,但網路流量(qps * 單個value的大小)還是過大,觸發了cache機器單臺機器的網路流量限流;
這裡面有一個問題需要引點關注
1、如何避免熱點資料的問題
其實我們在做分庫分表設計的時候也要考慮這個問題,比如某些大的商家可能會佔到80%的資料量,如果用商家ID進行分庫分表,必然會出現熱點資料問題。這跟上面提到的原因2其實是一樣的。有些熱點key都跑到一臺機器上面了。所以簡單的對key進行hash還不行。
我們在做設計之前,要先考慮一下
a. 是否存在熱點key ?
b. 如果存在熱點key ,那如何避免這些熱點key落在同一機器上面
2、要考慮快取的包大小
如果快取的包過大,會導致堵塞網路的風險。
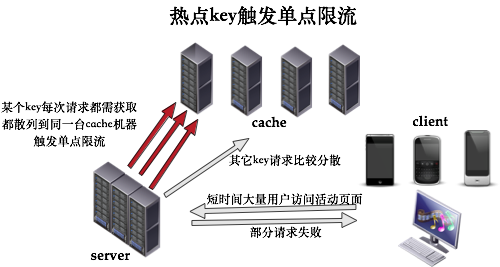

解決這兩個問題的一個比較好的辦法:
1、針對cache中元素key的訪問監控。一旦發現cache有qps限流或網路大小限流時,能夠通過監控看到到底是哪個key併發訪問量過大導致,或者哪些key返回的value大小較大,再結合cache雜湊演算法,通過一定的規則動態修改key值去平攤到各個cache機器上去。