python進行文字分類,基於word2vec,sklearn-svm對微博垃圾評論分類
阿新 • • 發佈:2018-12-27
差不多一年前的第一個分類任務,記錄一下
語料庫是關於微博的垃圾使用者評論,分為兩類,分別在normal,和spam資料夾下。裡面是很多個txt檔案,一個txt是一條使用者評論。

一、進行分詞
利用Jieba分詞和去除停用詞(這裡我用的是全模式分詞),每一篇文件為一行 用換行拼接,得到result.txt。其中用到的停用詞是在網上隨便下載的。
# 對句子進行分詞 def seg_sentence(sentence): sentence_seged = jieba.cut(sentence.strip()) stopwords = stopwordslist('stopword.txt') # 這裡載入停用詞的路徑 outstr = '' for word in sentence_seged: if word not in stopwords: if word != '\t': outstr += word outstr += " " return outstr
去停用詞後的結果如圖

二.用gensim.word2vec得到詞向量模型
這裡要用到word2vec來訓練詞向量,python要安裝對應的庫。
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) sentences = word2vec.Text8Corpus(u"./data111") # 載入語料 if os.path.exists("./model"): model = gensim.models.Word2Vec.load('./model') else: model = word2vec.Word2Vec(sentences, min_count=1, size=50) # 訓練skip-gram模型 model.save("./model")
三.每個文件的句子向量求平均求得文件向量
這裡主要是要求得能代表文件的向量,這裡就簡單的將文件中的句子相加求平均,得到一個50維的文件向量。
def get_word_vector(path): ip = open(path, 'r', encoding='utf-8') content = ip.readlines() vecs = [] for words in content: # vec = np.zeros(2).reshape((1, 2)) vec = np.zeros(50).reshape((1, 50)) count = 0 words = remove_some(words) for word in words[1:]: try: count += 1 # vec += model[word].reshape((1, 2)) vec += model[word].reshape((1, 50)) # print(vec) except KeyError: continue vec /= count vecs.append(vec) return vecs
四.sklearn-svm進行分類
這裡人工建立兩個分別對應垃圾評論和非垃圾評論的標籤,分別用0,1來表示兩類。然後把對應的標籤和語料隨機劃分成訓練集和測試集,放到分類器中訓練和測試。
這裡的標籤是建立了兩個列表:
normal_tag = np.ones((len(normal)))
spam_tag = np.zeros((len(spam)))用3:7的比例劃分測試和訓練集
X_train, X_test, y_train, y_test = train_test_split(np.array(train, dtype='float64'),
np.array(train_tag, dtype='float64'), test_size=0.30,
random_state=0) # 隨機選擇30%作為測試集,剩餘作為訓練集訓練並得到測試結果
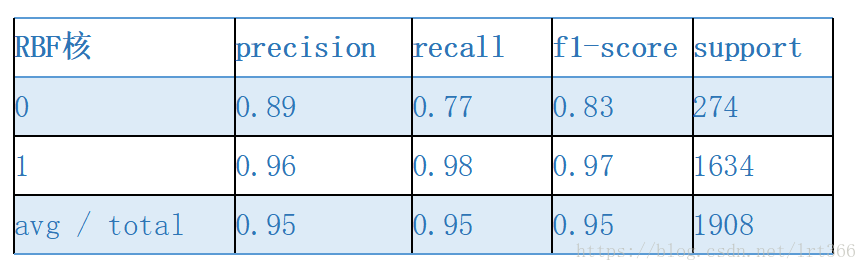
clf = svm.SVC() # 使用RBF核
clf_res = clf.fit(X_train, y_train)
# train_pred = clf_res.predict(X_train)
test_pred = clf_res.predict(X_test)
print(classification_report(y_test, test_pred))其中rbf核的結果比較好,如下所示