
基於知識圖譜的問答系統(KBQA)
最近因為工作原因暫時停止機器學習方面知識的學習,研究了一段KBQA。,下面是一個簡單的關於中小學生需要掌握的詩詞的demo,各位看官有興趣的可以瞅瞅,歡迎來信一起交流。

1. 原理
KBQA簡單講就是將問題帶入提前準備好的知識庫尋求答案的一種基於知識庫的問答系統。該問答系統可以解析輸入的自然語言問句,主要運用REFO庫的物件正則表示式匹配得到結果,然後利用對應的SPARQL查詢語句,請求後臺基於TDB知識譜圖資料庫的服務,最終得到我們想要的結果。
2. 流程
1.實體檢測,獲取問題的關鍵詞,比如問題“李白寫了哪些詩?”,那麼首先必須找到李白,才可以進行下一步。
2.目的獲取,一個問題,我們只獲取了實體還不夠,比如上面,只有李白,還要有目的,不然可能我是想問李白是哪個朝代的人,哪裡的人等等,所以需要找到問題的真實目的。
3.關係預測,有了實體和目的,那麼我們就需要在知識庫裡面尋找著方面的關係,想辦法聯想起來。
4.查詢構建,將處理好的三元組帶入知識庫搜尋答案。
3. 知識圖譜
1.介紹
知識圖譜由google於2012年率先提出,其初衷是用以增強自家的搜尋引擎的功能和提高搜尋結果質量,使得使用者無需通過點選多個連線就可以獲取結構化的搜尋結果,並且提供一定的推理功能。這裡我還是用《將進酒》這首詩舉個例子,很多人看到《將進酒》,估計第一時間想不到這是哪個年代的人寫的,但是不妨看看作者,李白,很多人對李白就比較耳熟能詳了,那麼就來了,很多人都知道李白是唐朝人(這裡假設沒人不知道哈),那麼自然而然就知道《將進酒》這首詩寫在唐朝了。說了這些,我們發現,如果知識庫裡面有這些資訊,我們就很容易找到《將進酒》是哪個朝代的詩歌。如果我們再多加一些相關屬性,就可以構成一張簡單的知識圖了,如下圖,具體的我就不描述了,大家可以看看

2. 資料格式
在知識圖譜中,資料一般以RDF形式的三元組表示。
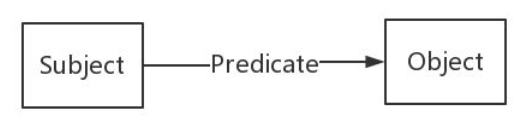
RDF(Resource Description Framework)即資源描述框架,其本質是一個數據模型。它提供了一個統一的標準,用於描述實體/資源。簡單來說,就是表示事物的一種方法和手段。RDF形式上表示為SPO三元組,知識圖譜中我們也稱其為一條知識。RDF由節點和邊組成,節點表示實體/資源、屬性,邊則表示了實體和實體之間的關係以及實體和屬性的關係。如下圖所示:
RDF資料集方式主要有以下幾種,主要使用Turtle。
1、RDF/XML,用XML的格式來表示RDF資料。之所以提出這個方法,是因為XML的技術比較成熟,有許多現成的工具來儲存和解析XML。然而,對於RDF來說,XML的格式太冗長,也不便於閱讀,通常我們不會使用這種方式來處理RDF資料。
2、N-Triples,即用多個三元組來表示RDF資料集,是最直觀的表示方法。在檔案中,每一行表示一個三元組,方便機器解析和處理。開放領域知識圖譜DBpedia通常是用這種格式來發布資料的。
3、Turtle, 應該是使用得最多的一種RDF序列化方式了。它比RDF/XML緊湊,且可讀性比N-Triples好。
4、RDFa, 是HTML5的一個擴充套件,在不改變任何顯示效果的情況下,讓網站構建者能夠在頁面中標記實體,像人物、地點、時間、評論等等。也就是說,將RDF資料嵌入到網頁中,搜尋引擎能夠更好的解析非結構化頁面,獲取一些有用的結構化資訊。
5、JSON-LD,即“JSON for Linking Data”,用鍵值對的方式來儲存RDF資料。
但是RDF的表達能力有限,無法區分類和物件,也無法定義和描述類的關係/屬性,這個時候就有人提出RDFS和OWL這兩種技術或者說模式語言/本體語言來解決了RDF表達能力有限的困境,詳細介紹參考
4. 例項分析
知識圖譜這個專欄講的非常詳細,我也是參考這位前輩的專欄實現的小demo,所以我就不在這裡花過多的時間描述相關方面的知識了,避免理解錯誤,誤導大家。下面就直接開始我自己的例項。本demo實現是為了展示知識圖譜,所以將資料分開,其實也可以直接將詩詞名、作者、朝代、詩詞內容放在一起,全部作為屬性,不需要在SQL中建立多個數據表,所以希望大家不要覺得麻煩,感興趣的可以使用一張表試著做一下。
-
資料準備
資料是中小學必背詩詞,其中資訊有詩詞名、作者、朝代、詩詞內容。
作者資訊:姓名、朝代
詩詞資訊:詩詞名、詩詞內容
詩句使用scrapy在百度上爬取,如果想自己動手的,可以參考一下前面的部落格scrapy學習(一):scrapy框架(爬古詩詞)。 -
資料建模
這步是非必須的,但是為了後面資料對映更容易理解,我還是在這裡簡述一下。構建資料結構一般使用工具protégé,構建過程參考本體建模,根據我們自己的功能需要,建立三個類Poem(詩詞)、Poet(詩人)、Verse(詩句):
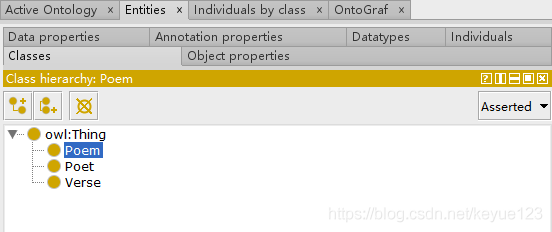

上面的類和推理都建立好了,接下來就需要定義每個類裡面的屬性:poemContent(詩詞內容)、poemName(詩詞名)、poetDynasty(詩人朝代)、poetName(詩人名)、sentenceId(詩句ID)、verseId(詩詞ID)、sentenceContent(詩句內容)、verseLen(詩詞長度)。同樣右下角也需要定義屬性,Domain為屬於哪個類,Range與前面關係的Domain有區別,這裡表示的是資料型別。

類、關係、屬性都定義好之後,就組成了一個簡單的資料模型,點選"Window–>Tabs–>OntoGraf",就可以在protégé中很明瞭的看出相互之間的關係。

將我們構建好的關係匯出備用,匯出格式如下,檔名隨意,我這裡取為poem_kbqa.owl

- 資料對映
現在資料有了,關係也有了,如何將兩者聯絡起來呢,我們以mysql中的詩詞名為例,將poem這個表對映到我們在protege中定義的Peom類上,poem title對映到poemName上。
map:poem a d2rq:ClassMap;
d2rq:dataStorage map:database;
d2rq:uriPattern "poem/@@[email protected]@";
d2rq:class :Poem; # 類名
d2rq:classDefinitionLabel "poem"; # sql資料表
.
map:poem_title a d2rq:PropertyBridge;
d2rq:belongsToClassMap map:poem;
d2rq:property :poemName;
d2rq:propertyDefinitionLabel "poem title";
d2rq:column "poem.title";
.
很多人看到上面的語句就懵逼了,但是別急,這可以直接通過D2RQ來實現,D2RQ是以RDF圖的方式訪問關係資料庫把,對RDF的查詢等操作翻譯成SQL語句,最終在RDB上實現對應操作。使用者可以在資料庫自動生成預定義的mapping檔案上修改,從而把資料對映到自己的本體上。
進入D2RQ目錄,執行下列語句生成mapping檔案,我這裡取名poem_demo_mapping.ttl,大家自己隨意就好。
$ ./generate-mapping -u root -p 123456 -o poem_demo_mapping.ttl jdbc:mysql://127.0.0.1:3306/poem_kbqa_demo?serverTimezone=UTC

# Table poem
map:poem a d2rq:ClassMap;
d2rq:dataStorage map:database;
d2rq:uriPattern "poem/@@[email protected]@";
d2rq:class :Poem;
d2rq:classDefinitionLabel "poem";
.
map:poem_title a d2rq:PropertyBridge;
d2rq:belongsToClassMap map:poem;
d2rq:property :poemName;
d2rq:propertyDefinitionLabel "poem title";
d2rq:column "poem.title";
.
map:poem_content a d2rq:PropertyBridge;
d2rq:belongsToClassMap map:poem;
d2rq:property :poemContent;
d2rq:propertyDefinitionLabel "poem content";
d2rq:column "poem.content";
.
- 資料查詢
資料對映完成後,我們可以類似使用SQL查詢關係資料庫一樣使用SPARQL查詢RDF格式的資料。
SPARQL查詢是基於圖匹配的思想。比如我想查詢《將進酒》的內容,那麼需要將查詢語句與RDF圖進行匹配,找到符合該匹配模式的所有子圖,最後得到變數的值。SPARQL查詢分為三個步驟:
1. 構建查詢圖模式,表現形式就是帶有變數的RDF。
2. 匹配,匹配到符合指定圖模式的子圖。
3. 繫結,將結果繫結到查詢圖模式對應的變數上。
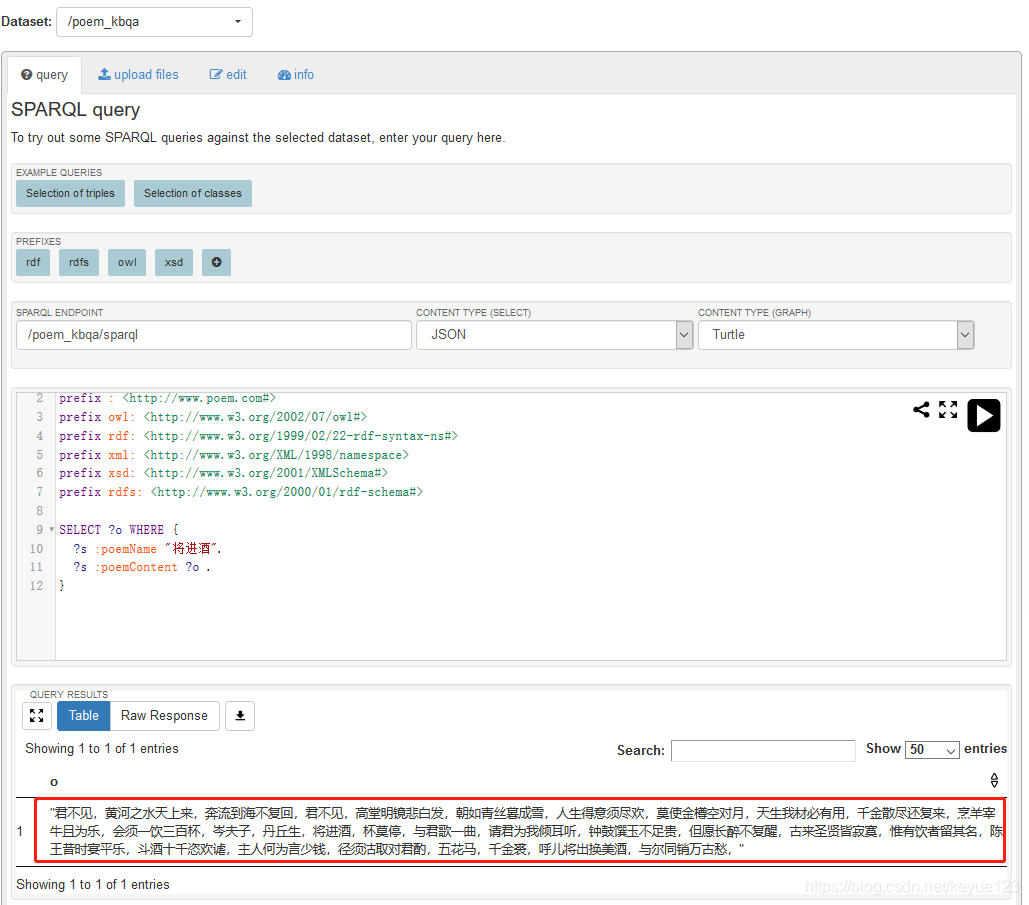
由上面分析,查詢《將進酒》的內容對應的SPARQL查詢語言為:
PREFIX : <http://www.poem.com#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX vocab: <http://localhost:2020/resource/vocab/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX map: <http://localhost:2020/resource/#>
PREFIX db: <http://localhost:2020/resource/>
SELECT ?o WHERE {
?s :poemName '將進酒'.
?s :poemContent ?o.
}
SELECT指定我們要查詢的變數。這裡需要查詢內容,用?o代替。
WHERE指定我們要查詢的圖模式。意思上和SQL的WHERE沒有區別。
?s、?o為三元組的實體表示。
:poemContent、:poemName為關係
最終查詢出來的結果為:
"君不見,黃河之水天上來,奔流到海不復回,君不見,高堂明鏡悲白髮,朝如青絲暮成雪,人生得意須盡歡,莫使金樽空對月,天生我材必有用,千金散盡還復來,烹羊宰牛且為樂,會須一飲三百杯,岑夫子,丹丘生,將進酒,杯莫停,與君歌一曲,請君為我傾耳聽,鐘鼓饌玉不足貴,但願長醉不復醒,古來聖賢皆寂寞,惟有飲者留其名,陳王昔時宴平樂,斗酒十千恣歡謔,主人何為言少錢,徑須沽取對君酌,五花馬,千金裘,呼兒將出換美酒,與爾同銷萬古愁,"
- 查詢實踐
上一章簡單講了一下SPARQL查詢的語句,下面我們就來實際操作一下,這裡講解兩種方式:
1.利用D2RQ開啟SPARQL endpoint服務
2.利用Apache jena開啟SPARQL endpoint服務 - D2RQ
進入d2rq目錄,使用下面的命令啟動D2R Server:
$ ./d2r-server.bat poem_demo_mapping.ttl



from SPARQLWrapper import SPARQLWrapper, JSON
sparql = SPARQLWrapper("http://localhost:2020/sparql")
sparql.setQuery("""
PREFIX : <http://www.poem.com#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX vocab: <http://localhost:2020/resource/vocab/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX map: <http://localhost:2020/resource/#>
PREFIX db: <http://localhost:2020/resource/>
SELECT ?o WHERE {
?s :poemName '將進酒'.
?s :poemContent ?o.
}
""")
sparql.setReturnFormat(JSON)
results = sparql.query().convert()
for result in results["results"]["bindings"]:
for x in results["head"]["vars"]:
print(result[x]["value"])
最終查詢出來的結果為:
"君不見,黃河之水天上來,奔流到海不復回,君不見,高堂明鏡悲白髮,朝如青絲暮成雪,人生得意須盡歡,莫使金樽空對月,天生我材必有用,千金散盡還復來,烹羊宰牛且為樂,會須一飲三百杯,岑夫子,丹丘生,將進酒,杯莫停,與君歌一曲,請君為我傾耳聽,鐘鼓饌玉不足貴,但願長醉不復醒,古來聖賢皆寂寞,惟有飲者留其名,陳王昔時宴平樂,斗酒十千恣歡謔,主人何為言少錢,徑須沽取對君酌,五花馬,千金裘,呼兒將出換美酒,與爾同銷萬古愁,"
- Apache jena
Apache Jena是一個開源的Java語義網框架,用於構建語義網和連結資料應用,是使用最廣泛、文件最全、社群最活躍的一個開源語義網框架。我們會用到的元件有:TDB、Fuseki。- TDB是Apache Jena用於儲存RDF的元件,是屬於儲存層面的技術。在單機情況下,它能夠提供非常高的RDF儲存效能。
- Apache Jena提供了RDFS、OWL和通用規則推理機。其實Apache Jena的RDFS和OWL推理機也是通過Apache Jena自身的通用規則推理機實現的。
- Fuseki是Apache Jena提供的SPARQL伺服器,也就是SPARQL endpoint。其提供了四種執行模式:單機執行、作為系統的一個服務執行、作為web應用執行或者作為一個嵌入式伺服器執行。
tdb支援RDF資料,所以需要講我們的對映檔案轉為RDF檔案。進入D2RQ目錄:
$./dump-rdf.bat -o poem_kbqa.nt poem_demo_mapping.ttl
poem_demo_mapping.ttl是建模後的對映檔案。其支援匯出的RDF格式有“TURTLE”, “RDF/XML”, “RDF/XML-ABBREV”, “N3”, 和“N-TRIPLE”。“N-TRIPLE”是預設的輸出格式。poem_kbqa.nt就是我們生成的RDF檔案。
tdb資料存放,進入apache-jena\bat目錄下:
$.\tdbloader.bat --loc="C:\KBQA\apache-jena\tdb" "C:\d2rq-0.8.1\poem_kbqa.nt"
--loc為資料存放路徑,poem_kbqa.nt為RDF檔案。
進入入Fuseki資料夾,執行fuseki-server.bat,然後退出。程式會為我們在當前目錄自動建立run資料夾。將我們前面在資料建模時產生的檔案poem_kbqa.owl移動到run資料夾下的databases資料夾中,並將owl字尾名改為ttl。在run資料夾下的configuration中,我們建立名為fuseki_conf.ttl的文字檔案(取名隨意),加入如下內容:
@prefix : <http://base/#> .
@prefix tdb: <http://jena.hpl.hp.com/2008/tdb#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix ja: <http://jena.hpl.hp.com/2005/11/Assembler#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix fuseki: <http://jena.apache.org/fuseki#> .
<#service3> rdf:type fuseki:Service ;
fuseki:name "poem_kbqa" ; # RDF檔案表
fuseki:serviceQuery "sparql" ; # SPARQL query service
fuseki:dataset <#dataset> ;
.
<#dataset> rdf:type tdb:DatasetTDB ;
tdb:location "C:/KBQA/apache-jena/tdb" ; # tdb資料路徑
# Query timeout on this dataset (1s, 1000 milliseconds)
ja:context [ ja:cxtName "arq:queryTimeout" ; ja:cxtValue "1000" ] ;
# Make the default graph be the union of all named graphs.
## tdb:unionDefaultGraph true ;
.
再次執行命令:
$ ./fuseki-server.bat

關於jena-fuseki SPARQL query版本問題的解決方案
預設埠是2020,在瀏覽器輸入“http://127.0.0.1:3030/”, 可以看到如下介面。
實踐篇(四):Apache jena SPARQL endpoint及推理這裡講述了規則推理,個人意見,可以不使用,直接利用語句推理即可,看個人想法,不喜勿噴。
- KBQA實踐
前面講了這麼多理論知識,現在就真是開始我們文章開頭的demo。此demo是利用正則表示式來做語義解析。我們需要第三方庫來完成初步的自然語言處理(分詞、實體識別),然後利用支援詞級別正則匹配的庫來完成後續的語義匹配。
分詞和實體識別我們用jieba來完成。為了防止分詞錯誤,我這裡將所有的詩人、詩名、詩句提出來作為擴充套件詞並標註詞性。分詞結束後,可以使用REfO來完成語義匹配。匹配成功後,將其其對應的我們預先編寫的SPARQL模板,再向Fuseki伺服器傳送查詢,得到最終結果。
基於知識圖譜的問答系統,感興趣的朋友可以去GitHub上獲取原始碼,自己試試效果,在跑demo之前,根據程式碼中是使用D2RQ還是Fuseki啟動對應服務。
5. 總結
使用知識圖譜,優缺點同樣明顯,在推理和關係上非常方便,但是如果在實際專案中使用,如果資料有更新,那麼久需要重新修改資料庫和對映,就需要全部重新走一遍流程,反而麻煩,所以下篇部落格我會換種方式再次實現一次相同效果的demo。
本部落格是根據知識圖譜-給AI裝個大腦模擬寫出來的,在這裡非常感謝該博主的無私分享。如果各位看官發現部落格中有什麼不對的,或者跟自己想法不一樣的,可以留信探討一下,純屬個人觀點,不喜勿噴。