
Linux 4 6核心對TCP REUSEPORT的優化
阿新 • • 發佈:2018-12-27
繁忙了一整天,下班回家總會有些許輕鬆,這是肯定的。時間不等人,只要有剩餘的時間,就想來點自己喜歡的東西。下班的班車上,用手機那令人遺憾的螢幕目睹了Linux 4.6的一些新特性,讓我感興趣的有兩點,第一是關於reuseport的,這也是本文要闡釋的,另外一個是關於KCM(Kernel Connection Multiplexor)的,而這個是我本週末計劃要寫的內容,這些都是回憶,且都是我本身經歷過的,正巧天氣預報說今晚有暴雨,激起了一些興趣,於是信手拈來,不足之處或者寫的不明之處,還望有人可以指出。我想從Q&A說起,這也符合大眾的預期,如果你真的能理解我的Q&A想說什麼,那麼Q&A之後接下來的內容,不看也罷。
Q1:什麼是reuseport?
A1:reuseport是一種套接字複用機制,它允許你將多個套接字bind在同一個IP地址/埠對上,這樣一來,就可以建立多個服務來接受到同一個埠的連線。
Q2:當來了一個連線時,系統怎麼決定到底是哪個套接字來處理它?
A2:對於不同的核心,處理機制是不一樣的,總的說來,reuseport分為兩種模式,即熱備份模式和負載均衡模式,在早期的核心版本中,即便是加入對reuseport選項的支援,也僅僅為熱備份模式,而在3.9核心之後,則全部改為了負載均衡模式,兩種模式沒有共存,雖然我一直都希望它們可以共存。
【我並沒有進一步說什麼是熱備份模式和負載均衡模式,這意味著我在等待提問者進一步發問】
Q3:什麼是熱備份模式和負載均衡模式呢?
A3:這個我來分別解釋一下。
熱備份模式:即你建立了N個reuseport的套接字,然而工作的只有一個,其它的作為備份,只有當前一個套接字不再可用的時候,才會由後一個來取代,其投入工作的順序取決於實現。
負載均衡模式:即你建立的所有N個reuseport的套接字均可以同時工作,當連線到來的時候,系統會取一個套接字來處理它。這樣就可以達到負載均衡的目的,降低某一個服務的壓力。
Q4:到底怎麼取套接字呢?
A4:這個對於熱備份模式和負載均衡模式是不同的。
熱備份模式:一般而言,會將所有的reuseport同一個IP地址/埠的套接字掛在一個連結串列上,取第一個即可,如果該套接字掛了,它會被從連結串列刪除,然後第二個便會成為第一個。
負載均衡模式:和熱備份模式一樣,所有reuseport同一個IP地址/埠的套接字會掛在一個連結串列上,你也可以認為是一個數組,這樣會更加方便,當有連線到來時,用資料包的源IP/源埠作為一個HASH函式的輸入,將結果對reuseport套接字數量取模,得到一個索引,該索引指示的陣列位置對應的套接字便是工作套接字。
Q5:那麼會不會第一個資料包由套接字m處理,後續來的資料包由套接字n處理呢?
A5:這個問題其實很容易,仔細看一下演算法就會發現,只要這些資料包屬於同一個流(同一個五元組),那麼它每次HASH的結果將會得到同一個索引,因此處理它的套接字始終是同一個!
Q6:我怎麼覺得有點玄呢?【這最後一個問題是我在一個同事的啟發下自問自答的...】
A6:確實玄!TCP自己會保持連線,我們暫且不談。對於UDP而言,比如一個事務中需要互動4個數據包,第一個資料包的元組HASH結果索引到了執行緒1的套接字的問題,它理所當然被執行緒1處理,在第二個資料包到達之前,執行緒1掛了,那麼該執行緒的套接字的位置將會被別的執行緒,比如執行緒2的套接字取代!在第二個資料包到達的時候,將會由執行緒2的套接字來處理之,然而執行緒2並不知道執行緒1儲存的關於此連線的事務狀態...
我們來看下Q6/A6,這個問題確實存在,但是卻不是什麼大問題,這個是和實現相關的,所以並不是reuseport機制本身的問題。我們完全可以用陣列代替連結串列,並且維持陣列的大小,即使執行緒n掛了,它的套接字所在的位置並不被已經存在的套接字佔據,而必須是被新建的替補執行緒(畢竟執行緒n已經掛了,要新建一個補充)的套接字佔據,這樣就能解決問題,所需的僅僅是任何執行緒在掛之前把狀態資訊序列化,然後在新執行緒啟動的時候重新反序列化資訊即可。
到此為止,我沒有提及任何關於Linux 4.6核心對TCP reuseport優化的任何資訊,典型的標題黨!
然而,以上幾乎就是全部資訊,如果說還有別的,那就只能貼程式碼了。事實上,在Linux 4.6(針對TCP)以及Linux 4.5(針對UDP)的優化之前,我上述的Answer是不準確的,在4.5之前,Linux核心中關於reuseport的實現並非我想象的那樣,然而為了解釋概念和機制,我不得不用上述更加容易理解的方式去闡述,原理是一回事,實現又是一回事,請原諒我一直以來針對原理的闡述與Linux實現並不相符。
可想而知,4.5/4.6的所謂reuseport的優化,它僅僅是一種更加自然的實現方式罷了,相反,之前的實現反而並不自然!回憶三年來,有多少人問過我關於reuseport的事情,其中也不乏幾位面試官,如果被進一步追問“Q:你確定Linux就是這麼實現的嗎?”那麼我一定回答:“不!不是這麼實現的,Linux的實現方法很垃圾!”,然後就會聽到我滔滔不絕的闡釋大量的形而上的東西,最終在一種不那麼緩和的氣氛中終止掉對話。
總結一下吧,事實上Linux 4.5/4.6所謂的對reuseport的優化主要體現在查詢速度上,在優化前,不得不在HASH衝突連結串列上遍歷所有的套接字之後才能知道到底取哪個(基於一種冒泡的score打分機制,不完成一輪冒泡遍歷,不能確定誰的score最高),之所以如此低效是因為核心將reuseport的所有套接字和其它套接字混合在了一起,查詢是平坦的,正常的做法應該是將它們分為一個組,進行分層查詢,先找到這個組(這個很容易),然後再在組中找具體的套接字。Linux 4.5針對UDP做了上述優化,而Linux 4.6則將這個優化引入到了TCP。
設想系統中一共有10000個套接字被HASH到同一個衝突連結串列,其中9950個是reuseport的同一組套接字,如果按照老的演算法,需要遍歷10000個套接字,如果使用基於分組的演算法,最多隻需要遍歷51個套接字即可,找到那個組之後,一步HASH就可以找到目標套接字的索引!
之所以要遍歷是因為所有的reuseport套接字和其它的套接字都被平坦地插入到同一個表中,事先並不知道有多少組reuseport套接字以及每一組中有多少個套接字,比如下列例子:
reuseport group1-0.0.0.0:1234(sk1,sk2,sk3,sk4)
reuseport group2-1.1.1.1:1234(sk5,sk6,sk7)
other socket(sk8,sk9,sk10,sk11)
假設它們均被HASH到同一個位置,那麼可能的順序如下:
sk10-sk2-sk3-sk8-sk5-sk7-...
雖然sk2就已經匹配了,然而後面還有更精確的sk5,這就意味著必須把11個套接字全部遍歷完後才知道誰會冒泡到最上面。
我們著重看一下reuseport_select_sock,這個函式是第二層組內查詢的關鍵,其實不應該叫做查詢,而應該叫做定位更加合適:
也不是那麼神奇,不是嗎?基本上在Q&A中都已經涵蓋了。
因為我可以確定系統中不會有任何其它的reuseport套接字,且我可以確定裝置的CPU個數是16個,因此定義陣列如下:
Q7:有沒有什麼統一的方法可以應對reuseport套接字的新增和刪除呢?比如新建一個工作負載執行緒,一個工作執行緒掛掉這種動態行為。
A7:有的。那就是“一致性HASH”演算法。
理解了原理之後,我們看一下怎麼實現這個mini一致性HASH。真正的一致性HASH實現起來太重了,網上也有很多的資料可查,我這裡只是給出一個思路,談不上最優。根據上圖,我們可以看到,歸根結底需要一個“區間查詢”,也就是說最終需要做的就是“判定第二類HASH結果落在了由第一類HASH結果分割的哪個區間內”,因此在直觀上,可以採用的就是二叉樹區間匹配,在此,我把上述的區間分割整理成一顆二叉樹:
日耳曼向左,羅馬向右!接下來就可以在這個二叉樹上進行二分查找了。
Q8:在reuseport的查詢處理上,TCP和UDP的區別是什麼?
A8:TCP的每一條連線均可以由完全的五元組資訊自行維護一個唯一的標識,只需要按照唯一的五元組資訊就可以找出一個TCP連線,但是對於Listen狀態的TCP套接字就不同了,一個來自客戶端的SYN到達時,五元組資訊尚未確立,此時正是需要找出是reuseport套接字組中到底哪個套接字來處理這個SYN的時候。待這個套接字確定以後,就可以和傳送SYN的客戶端建立唯一的五元組標識了,因此對於TCP而言,只有Listen狀態的套接字需要reuseport機制的支援。對於UDP而言,則所有的套接字均需要reuseport機制的支援,因為UDP不會維護任何連線資訊,也就是說,協議棧不會記錄哪個客戶端曾經來過或者正在與之通訊,沒有這些資訊,因此對於每一個數據包,均需要reuseport的查詢邏輯來為其對應一個處理它的套接字。
你知道每天最令人悲哀的事情是什麼嗎?那就是重複著一遍又一遍每天都在重複的話。
Q&A
當有人問起我關於reuseport的一些事的時候,我們的對話基本如下:Q1:什麼是reuseport?
A1:reuseport是一種套接字複用機制,它允許你將多個套接字bind在同一個IP地址/埠對上,這樣一來,就可以建立多個服務來接受到同一個埠的連線。
Q2:當來了一個連線時,系統怎麼決定到底是哪個套接字來處理它?
A2:對於不同的核心,處理機制是不一樣的,總的說來,reuseport分為兩種模式,即熱備份模式和負載均衡模式,在早期的核心版本中,即便是加入對reuseport選項的支援,也僅僅為熱備份模式,而在3.9核心之後,則全部改為了負載均衡模式,兩種模式沒有共存,雖然我一直都希望它們可以共存。
【我並沒有進一步說什麼是熱備份模式和負載均衡模式,這意味著我在等待提問者進一步發問】
Q3:什麼是熱備份模式和負載均衡模式呢?
A3:這個我來分別解釋一下。
熱備份模式:即你建立了N個reuseport的套接字,然而工作的只有一個,其它的作為備份,只有當前一個套接字不再可用的時候,才會由後一個來取代,其投入工作的順序取決於實現。
負載均衡模式:即你建立的所有N個reuseport的套接字均可以同時工作,當連線到來的時候,系統會取一個套接字來處理它。這樣就可以達到負載均衡的目的,降低某一個服務的壓力。
Q4:到底怎麼取套接字呢?
A4:這個對於熱備份模式和負載均衡模式是不同的。
熱備份模式:一般而言,會將所有的reuseport同一個IP地址/埠的套接字掛在一個連結串列上,取第一個即可,如果該套接字掛了,它會被從連結串列刪除,然後第二個便會成為第一個。
負載均衡模式:和熱備份模式一樣,所有reuseport同一個IP地址/埠的套接字會掛在一個連結串列上,你也可以認為是一個數組,這樣會更加方便,當有連線到來時,用資料包的源IP/源埠作為一個HASH函式的輸入,將結果對reuseport套接字數量取模,得到一個索引,該索引指示的陣列位置對應的套接字便是工作套接字。
Q5:那麼會不會第一個資料包由套接字m處理,後續來的資料包由套接字n處理呢?
A5:這個問題其實很容易,仔細看一下演算法就會發現,只要這些資料包屬於同一個流(同一個五元組),那麼它每次HASH的結果將會得到同一個索引,因此處理它的套接字始終是同一個!
Q6:我怎麼覺得有點玄呢?【這最後一個問題是我在一個同事的啟發下自問自答的...】
A6:確實玄!TCP自己會保持連線,我們暫且不談。對於UDP而言,比如一個事務中需要互動4個數據包,第一個資料包的元組HASH結果索引到了執行緒1的套接字的問題,它理所當然被執行緒1處理,在第二個資料包到達之前,執行緒1掛了,那麼該執行緒的套接字的位置將會被別的執行緒,比如執行緒2的套接字取代!在第二個資料包到達的時候,將會由執行緒2的套接字來處理之,然而執行緒2並不知道執行緒1儲存的關於此連線的事務狀態...
關於REUSEPORT的實現
我們來看下Q6/A6,這個問題確實存在,但是卻不是什麼大問題,這個是和實現相關的,所以並不是reuseport機制本身的問題。我們完全可以用陣列代替連結串列,並且維持陣列的大小,即使執行緒n掛了,它的套接字所在的位置並不被已經存在的套接字佔據,而必須是被新建的替補執行緒(畢竟執行緒n已經掛了,要新建一個補充)的套接字佔據,這樣就能解決問題,所需的僅僅是任何執行緒在掛之前把狀態資訊序列化,然後在新執行緒啟動的時候重新反序列化資訊即可。
到此為止,我沒有提及任何關於Linux 4.6核心對TCP reuseport優化的任何資訊,典型的標題黨!
然而,以上幾乎就是全部資訊,如果說還有別的,那就只能貼程式碼了。事實上,在Linux 4.6(針對TCP)以及Linux 4.5(針對UDP)的優化之前,我上述的Answer是不準確的,在4.5之前,Linux核心中關於reuseport的實現並非我想象的那樣,然而為了解釋概念和機制,我不得不用上述更加容易理解的方式去闡述,原理是一回事,實現又是一回事,請原諒我一直以來針對原理的闡述與Linux實現並不相符。
可想而知,4.5/4.6的所謂reuseport的優化,它僅僅是一種更加自然的實現方式罷了,相反,之前的實現反而並不自然!回憶三年來,有多少人問過我關於reuseport的事情,其中也不乏幾位面試官,如果被進一步追問“Q:你確定Linux就是這麼實現的嗎?”那麼我一定回答:“不!不是這麼實現的,Linux的實現方法很垃圾!”,然後就會聽到我滔滔不絕的闡釋大量的形而上的東西,最終在一種不那麼緩和的氣氛中終止掉對話。
總結一下吧,事實上Linux 4.5/4.6所謂的對reuseport的優化主要體現在查詢速度上,在優化前,不得不在HASH衝突連結串列上遍歷所有的套接字之後才能知道到底取哪個(基於一種冒泡的score打分機制,不完成一輪冒泡遍歷,不能確定誰的score最高),之所以如此低效是因為核心將reuseport的所有套接字和其它套接字混合在了一起,查詢是平坦的,正常的做法應該是將它們分為一個組,進行分層查詢,先找到這個組(這個很容易),然後再在組中找具體的套接字。Linux 4.5針對UDP做了上述優化,而Linux 4.6則將這個優化引入到了TCP。
設想系統中一共有10000個套接字被HASH到同一個衝突連結串列,其中9950個是reuseport的同一組套接字,如果按照老的演算法,需要遍歷10000個套接字,如果使用基於分組的演算法,最多隻需要遍歷51個套接字即可,找到那個組之後,一步HASH就可以找到目標套接字的索引!
Linux 4.5之前的reuseport查詢實現(4.3核心)
以下是未優化前的Linux 4.3核心的實現,可見是多麼地不直觀。它採用了遍歷HASH衝突連結串列的方式進行reuseport套接字的精確定位: result = NULL;
badness = 0;
udp_portaddr_for_each_entry_rcu(sk, node, &hslot2->head) {
score = compute_score2(sk, net, saddr, sport,
daddr, hnum, dif);
if (score > badness) { // 氣泡排序
// 找到了更加合適的socket,需要重新hash
result = sk;
badness = score;
reuseport = sk->sk_reuseport;
if (reuseport) {
hash = udp_ehashfn(net, daddr, hnum,
saddr, sport);
matches = 1;
}
} else if (score == badness && reuseport) { // reuseport套接字雜湊定位
// 找到了同樣reuseport的socket,進行定位
matches++;
if (reciprocal_scale(hash, matches) == 0)
result = sk;
hash = next_pseudo_random32(hash);
}
}之所以要遍歷是因為所有的reuseport套接字和其它的套接字都被平坦地插入到同一個表中,事先並不知道有多少組reuseport套接字以及每一組中有多少個套接字,比如下列例子:
reuseport group1-0.0.0.0:1234(sk1,sk2,sk3,sk4)
reuseport group2-1.1.1.1:1234(sk5,sk6,sk7)
other socket(sk8,sk9,sk10,sk11)
假設它們均被HASH到同一個位置,那麼可能的順序如下:
sk10-sk2-sk3-sk8-sk5-sk7-...
雖然sk2就已經匹配了,然而後面還有更精確的sk5,這就意味著必須把11個套接字全部遍歷完後才知道誰會冒泡到最上面。
Linux 4.5(針對UDP)/4.6(針對TCP)的reuseport查詢實現
我們來看看在4.5和4.6核心中對於reuseport的查詢增加了一些什麼神奇的新東西: result = NULL;
badness = 0;
udp_portaddr_for_each_entry_rcu(sk, node, &hslot2->head) {
score = compute_score2(sk, net, saddr, sport,
daddr, hnum, dif);
if (score > badness) {
// 在reuseport情形下,意味著找到了更加合適的socket組,需要重新hash
result = sk;
badness = score;
reuseport = sk->sk_reuseport;
if (reuseport) {
hash = udp_ehashfn(net, daddr, hnum,
saddr, sport);
if (select_ok) {
struct sock *sk2;
// 找到了一個組,接著進行組內hash。
sk2 = reuseport_select_sock(sk, hash, skb,
sizeof(struct udphdr));
if (sk2) {
result = sk2;
select_ok = false;
goto found;
}
}
matches = 1;
}
} else if (score == badness && reuseport) {
// 這個else if分支的期待是,在分層查詢不適用的時候,尋找更加匹配的reuseport組,注意4.5/4.6以後直接尋找的是一個reuseport組。
// 在某種意義上,這回退到了4.5之前的演算法。
matches++;
if (reciprocal_scale(hash, matches) == 0)
result = sk;
hash = next_pseudo_random32(hash);
}
}我們著重看一下reuseport_select_sock,這個函式是第二層組內查詢的關鍵,其實不應該叫做查詢,而應該叫做定位更加合適:
struct sock *reuseport_select_sock(struct sock *sk,
u32 hash,
struct sk_buff *skb,
int hdr_len)
{
...
prog = rcu_dereference(reuse->prog);
socks = READ_ONCE(reuse->num_socks);
if (likely(socks)) {
/* paired with smp_wmb() in reuseport_add_sock() */
smp_rmb();
if (prog && skb) // 可以用BPF來從使用者態注入自己的定位邏輯,更好實現基於策略的負載均衡
sk2 = run_bpf(reuse, socks, prog, skb, hdr_len);
else
// reciprocal_scale簡單地將結果限制在了[0,socks)這個區間內
sk2 = reuse->socks[reciprocal_scale(hash, socks)];
}
...
}也不是那麼神奇,不是嗎?基本上在Q&A中都已經涵蓋了。
我自己的reuseport查詢實現
當年看到了google的這個idea之後,Linux核心還沒有內建這個實現,我當時正在基於2.6.32核心搞一個關於OpenVPN的多處理優化,而且使用的是UDP,在親歷了折騰UDP多程序令人絕望的失敗後,我移植了google的reuseport補丁,然而它的實現更加令人絕望,多麼奇妙且簡單(奇妙的東西一定要簡單!)的一個idea,怎麼可能實現成了這個樣子(事實上這個樣子一直持續到了4.5版本的核心)??因為我可以確定系統中不會有任何其它的reuseport套接字,且我可以確定裝置的CPU個數是16個,因此定義陣列如下:
#define MAX 18
struct sock *reusesk[MAX]; result = NULL;
badness = 0;
udp_portaddr_for_each_entry_rcu(sk, node, &hslot2->head) {
score = compute_score2(sk, net, saddr, sport,
daddr, hnum, dif);
if (score > badness) {
result = sk;
badness = score;
reuseport = sk->sk_reuseport;
if (reuseport) {
hash = inet_ehashfn(net, daddr, hnum,
saddr, htons(sport));
#ifdef EXTENSION
// 直接取索引指示的套接字
result = reusesk[hash%MAX];
// 如果只有一組reuseport的套接字,則直接返回,否則回退到原始邏輯
if (num_reuse == 1)
break;
#endif
matches = 1;
}
} else if (score == badness && reuseport) {
matches++;
if (((u64)hash * matches) >> 32 == 0)
result = sk;
hash = next_pseudo_random32(hash);
}
}Q7&A7,Q8&A8
最後一個問題Q7:有沒有什麼統一的方法可以應對reuseport套接字的新增和刪除呢?比如新建一個工作負載執行緒,一個工作執行緒掛掉這種動態行為。
A7:有的。那就是“一致性HASH”演算法。
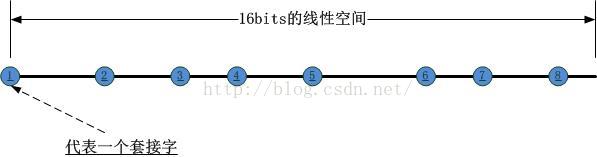
首先,我們可以將一個reuseport套接字組中所有的套接字按照其對應的PID以及記憶體地址之類的唯一標識,HASH到以下16bits的線性空間中(其中第一個套接字佔據端點位置),如下圖所示:
這樣N個socket就將該線性空間分割成了N個區間,我們把這個HASH的過程稱為第一類HASH!接下來,當一個數據包到達時,如何將其對應到某一個套接字呢?此時要進行第二類hash運算,這個運算的物件是資料包攜帶的源IP/源埠對,HASH的結果對應到前述16bits的線性空間中,如下圖所示:
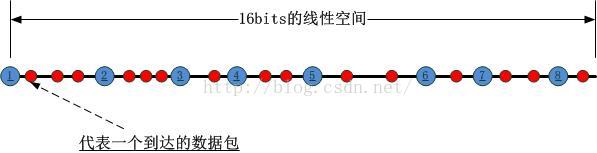
我們將第二類HASH值左邊的第一個第一類HASH值對應的套接字作為被選定的套接字,如下圖所示:
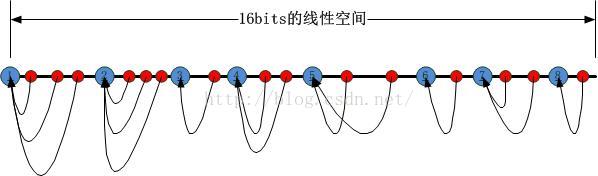
可以很容易看出來,如果第一類HASH值的節點被刪除或者新新增(意味著套接字的銷燬和新建),受到影響的僅僅是該節點與其右邊的第一個第一類HASH節點之間的第二類HASH節點,如下圖所示:
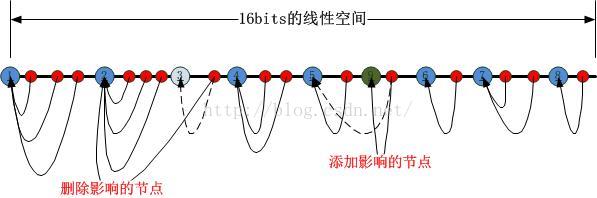
這就是簡化版的“一致性HASH”的原理。如果想在新建,銷燬的時候,一點都不受影響,那就別折騰這些演算法了,還是老老實實搞陣列吧。
理解了原理之後,我們看一下怎麼實現這個mini一致性HASH。真正的一致性HASH實現起來太重了,網上也有很多的資料可查,我這裡只是給出一個思路,談不上最優。根據上圖,我們可以看到,歸根結底需要一個“區間查詢”,也就是說最終需要做的就是“判定第二類HASH結果落在了由第一類HASH結果分割的哪個區間內”,因此在直觀上,可以採用的就是二叉樹區間匹配,在此,我把上述的區間分割整理成一顆二叉樹:
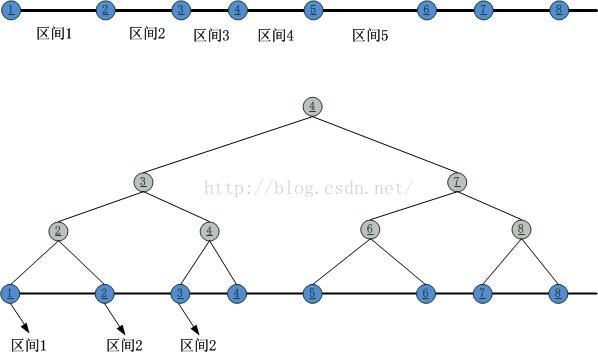
日耳曼向左,羅馬向右!接下來就可以在這個二叉樹上進行二分查找了。
Q8:在reuseport的查詢處理上,TCP和UDP的區別是什麼?
A8:TCP的每一條連線均可以由完全的五元組資訊自行維護一個唯一的標識,只需要按照唯一的五元組資訊就可以找出一個TCP連線,但是對於Listen狀態的TCP套接字就不同了,一個來自客戶端的SYN到達時,五元組資訊尚未確立,此時正是需要找出是reuseport套接字組中到底哪個套接字來處理這個SYN的時候。待這個套接字確定以後,就可以和傳送SYN的客戶端建立唯一的五元組標識了,因此對於TCP而言,只有Listen狀態的套接字需要reuseport機制的支援。對於UDP而言,則所有的套接字均需要reuseport機制的支援,因為UDP不會維護任何連線資訊,也就是說,協議棧不會記錄哪個客戶端曾經來過或者正在與之通訊,沒有這些資訊,因此對於每一個數據包,均需要reuseport的查詢邏輯來為其對應一個處理它的套接字。
你知道每天最令人悲哀的事情是什麼嗎?那就是重複著一遍又一遍每天都在重複的話。
再分享一下我老師大神的人工智慧教程吧。零基礎!通俗易懂!風趣幽默!還帶黃段子!希望你也加入到我們人工智慧的隊伍中來!https://www.cnblogs.com/captainbed