zabbix實現對磁碟效能動態監控
前言
zabbix一直是小規模網際網路公司伺服器效能監控首選,首先是免費,其次,有專門的公司和社群開發維護,使其穩定性和功能都在不斷地增強和完善。zabbix擁有詳細的UI介面和分組策略,在被監控的伺服器上安裝好agent後,無需新增任何監控選項,因為zabbix自帶一些必要的監控,如agent.ping之類,zabbix支援畫圖,這個是專門給boss們看的,極其重要。另外還支援使用者自定義監控選項,這一點非常方便,今天我要說的就是磁碟監控,標題中為動態的監控,意指智慧的識別磁碟個數,並生成相應的監控選項,因為每臺伺服器的磁碟可能不一樣,所以我是使用zabbix的discovery方式。
個人認為其UI介面是比較複雜的,但是畢竟越複雜越顯得高階。我常用的不算configure和administration標籤下所有的選項(這是必不可少的),也就graphs和screen,這兩個選項是在monitor標籤下的,也是BOSS們最關注的。
自動尋找磁碟
說到底,所有的自動判斷都是人為的設定好所有的可能性,然後根據實際情況從中選擇,方法有很多,看大傢俱體要求。在這裡,我要對磁碟監控,首先要找出有哪些磁碟,這裡使用shell指令碼實現。由於zabbix的discovery需要固定的格式,具體可以參考這裡,最下面部分。
指令碼如下:
1 #!/bin/bash 2 #written by Yiffy 3 #mail:[email protected] 4 diskarray=(`cat /proc/diskstats |grep -E "\bsd[abcdefg]\b|\bxvd[abcdefg]\b"|grep-i "\b$1\b"|awk '{print $3}'|sort|uniq 2>/dev/null`) 5 length=${#diskarray[@]} 6 printf "{\n" 7 printf '\t'"\"data\":[" 8 for ((i=0;i<$length;i++)) 9 do 10 printf '\n\t\t{' 11 printf "\"{#DISK_NAME}\":\"${diskarray[$i]}\"}" 12 if [ $i -lt $[$length-1] ];then13 printf ',' 14 fi 15 done 16 printf "\n\t]\n" 17 printf "}\n"
如上,這裡通過讀取/proc/diskstats,選擇其中的磁碟,根據實際情況,我這裡就找出類似sda或者xvda的,因為我們用的是sata介面的硬碟以及部分阿里雲的伺服器。
指令碼執行出來的結果類似如下
1 { 2 "data":[ 3 {"{#DISK_NAME}":"sda"} 4 {"{#DISK_NAME}":"sdb"} 5 ] 6 }
然後使用zabbix執行這個指令碼,那麼就要將其寫到zabbix_agentd.conf中去,如下
UserParameter=io.scandisk[*],/infra/zabbix/os/disk_scan.sh $1
iostat命令
對於磁碟的監控我採用iostat命令,因為它能給出磁碟的詳細資訊,如扇區讀寫情況,io佇列長度,iowait,svctime等等。
命令如下:
1 nohup iostat -m -x -d 30 >/tmp/iostat_output &
通過tail -f /tmp/iostat_output,可獲得iostat命令收集的磁碟資訊,結果類似下面
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await svctm %util hda 0.00 0.20 0.00 7.43 0.00 0.16 43.28 0.23 30.80 2.43 1.81 hda1 0.00 0.20 0.00 7.43 0.00 0.16 43.28 0.23 30.80 2.43 1.81 hda2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 xvdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 xvdb1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 hdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
其中部分引數的詳細解釋如下
rrqm/s: 每秒進行 merge 的讀運算元目。即 delta(rmerge)/s wrqm/s: 每秒進行 merge 的寫運算元目。即 delta(wmerge)/s r/s: 每秒完成的讀 I/O 裝置次數。即 delta(rio)/s w/s: 每秒完成的寫 I/O 裝置次數。即 delta(wio)/s rsec/s: 每秒讀扇區數。即 delta(rsect)/s wsec/s: 每秒寫扇區數。即 delta(wsect)/s rkB/s: 每秒讀K位元組數。是 rsect/s 的一半,因為每扇區大小為512位元組。(需要計算) wkB/s: 每秒寫K位元組數。是 wsect/s 的一半。(需要計算) avgrq-sz: 平均每次裝置I/O操作的資料大小 (扇區)。delta(rsect+wsect)/delta(rio+wio) avgqu-sz: 平均I/O佇列長度。即 delta(aveq)/s/1000 (因為aveq的單位為毫秒)。 await: 平均每次裝置I/O操作的等待時間 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio) svctm: 平均每次裝置I/O操作的服務時間 (毫秒)。即 delta(use)/delta(rio+wio) %util: 一秒中有百分之多少的時間用於 I/O 操作,或者說一秒中有多少時間 I/O 佇列是非空的。即 delta(use)/s/1000 (因為use的單位為毫秒)
結合zabbix
最開始已經說了,是結合zabbix的discovery功能,所以要對zabbix做出如下設定。
(1)新建discovery規則
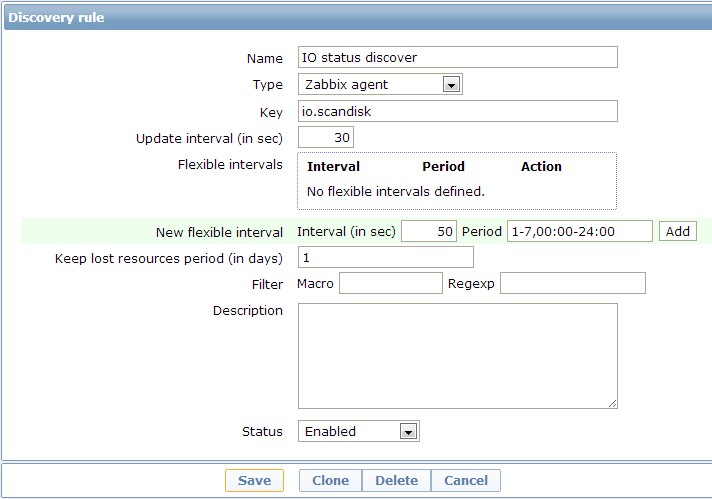
(2)新建好discovery rule之後,就可以開始寫item prototypes了,下面是一個例子avgqu-sz(平均I/O佇列長度)。
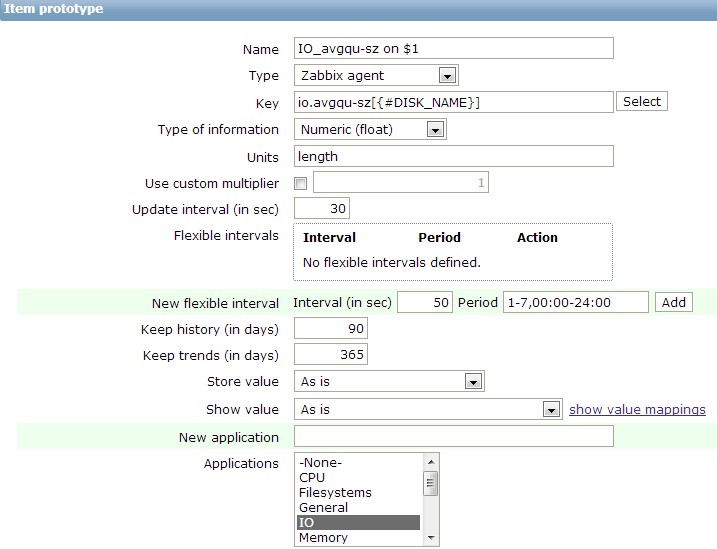
在建立好item之後,zabbix_agentd.conf中也要寫上相應的UserParameters,如下。
1 UserParameter=io.scandisk[*],/infra/zabbix/os/disk_scan.sh $1 2 UserParameter=io.rps[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b"|tail -1|awk '{print $$4}' 3 UserParameter=io.wps[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b" |tail -1|awk '{print $$5}' 4 UserParameter=io.rMBps[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b" |tail -1|awk '{print $$6}' 5 UserParameter=io.wMBps[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b" |tail -1|awk '{print $$7}' 6 UserParameter=io.avgrq-sz[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b" |tail -1|awk '{print $$8}' 7 UserParameter=io.avgqu-sz[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b" |tail -1|awk '{print $$9}' 8 UserParameter=io.await[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b" |tail -1|awk '{print $$10}' 9 UserParameter=io.svctm[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b" |tail -1|awk '{print $$11}' 10 UserParameter=io.util[*],/usr/bin/tail /tmp/iostat_output |grep "\b$1\b" |tail -1|awk '{print $$12}'
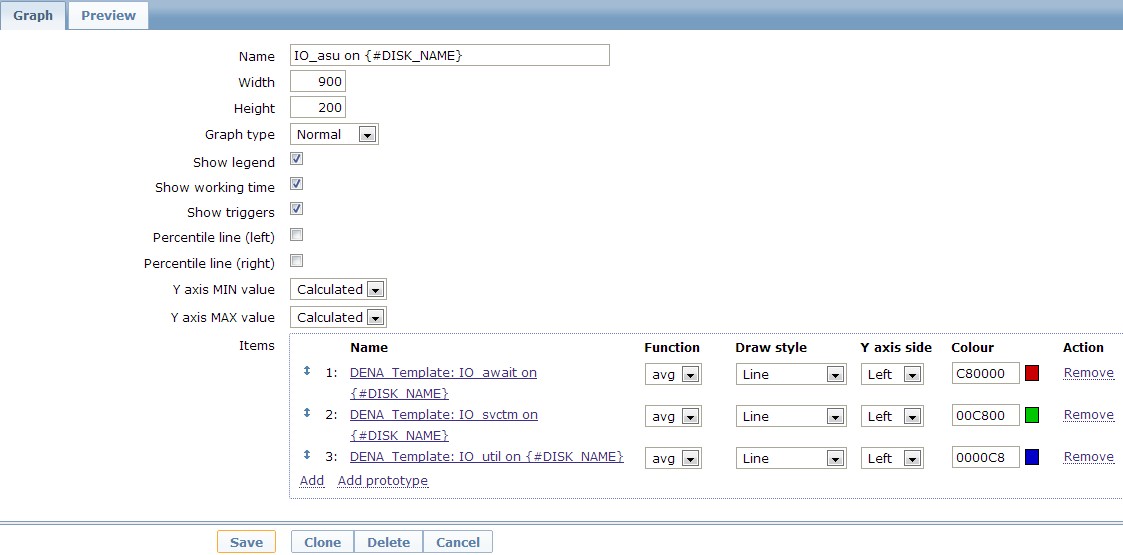
以上,監控的部分實際就已經完成。不過還要畫圖,也就是新建graph prototype了,如下圖。
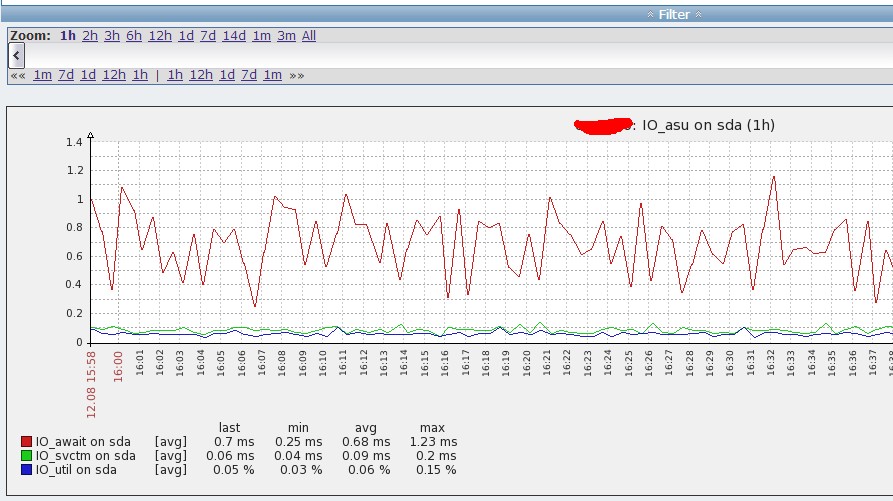
最後,看一下勞動成功,這樣就實現了zabbix自動判斷伺服器上的磁碟個數,然後自動部署對應磁碟的監控並生成圖表。