
機器學習--無監督學習之K-means聚類方法
一、引言
從上次SVM之後幾節課講的是學習理論,這塊理論性比較深,我得好好消化一下。所以先總結一下第一個無監督的機器學習演算法,K-means聚類方法。
所謂無監督學習,就是資料樣本沒有標籤,要讓學習演算法自己去發現數據之間內在的一些結構和規律。就好比做題沒有標準答案,所以訓練效果自然比監督學習差。但是目前機器學習最大的問題還是在於大量標記樣本的需求,掌握資料才能訓練出好的演算法,但是資料卻不是人人都能輕易獲得的。所以無監督學習演算法的研究是必要的和長期的。
二、演算法介紹
k-means演算法是一種迭代演算法,其思想很簡單。就是找出樣本所聚集的類個數並找出每一個樣本點歸屬於哪個類。
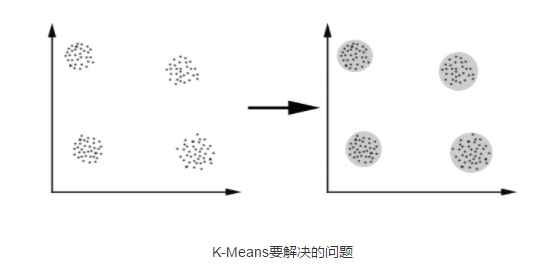
分成兩步:
先人工指定K個聚類中心,並採用一定規則初始化它們的位置;
(1) 簇分配:遍歷樣本分別找到與k個聚類中心的點,分別歸類。
(2)移動中心:將聚類中心移到上一步歸屬於該中心的樣本點的均值處
重複以上步驟直到收斂。給個圖就是這樣:
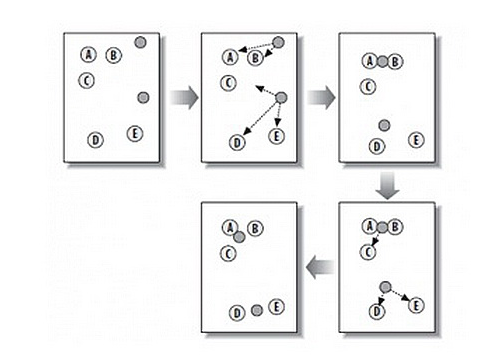
還有個動圖地址:https://datasciencelab.files.wordpress.com/2013/12/p_n100_k7.gif
演算法非常簡單,下面給出幾個需要注意的點:
(1)每次求取樣本點到 各個聚類中心距離時,可以用一般的兩點之間的距離,也可以有其餘求取距離的方法:
①Euclidean Distance公式——歐幾里得距離,就是最常見的二範數

②CityBlock Distance公式
![]()
這裡有一些公式,說明演算法的步驟:
①初始化k個聚類中心(通常不是很多,2,3,4,5個左右)
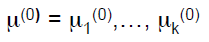
②把每個樣本點(j=1,...m)分配給裡它最近的聚類中心,t表示第t次迭代
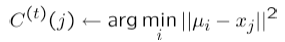
③把聚類中心更新為屬於它的樣本點的平均值點
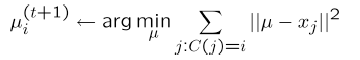
它的優化函式為:
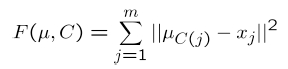
引數部分分為兩塊,其中C是針對每個樣本點的,m為,每一維表示了每一個樣本點所屬的聚類中心索引,μ是針對聚類中心的,有k維。優化的過程就是演算法的迭代的過程,分為兩部分。每一步固定一組引數,優化另一組引數。
那麼,最重要的問題來了,如何選擇k-means的初始聚類中心個數以及初始聚類中心位置?
①首先k<m,聚類中心個數肯定比樣本點個數少。第二,可以用肘部法則選擇k的個數,示意圖如下:
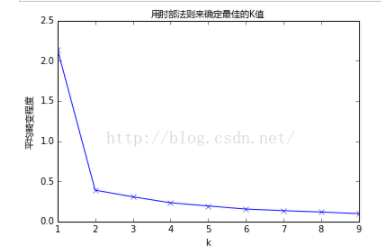
針對不同的k個數繪製代價函式最後最優值曲線繪製,一般在k=1~10之間,找到類似於手肘的點對應的k個數,應該是最好的一個。但是這種方法也不是萬能,最好的方法還是人工選擇,結合k-means應用的場景來選。
②初始聚類中心的位置選擇不同,最後收斂的結果和速度也可能不同。選擇思路如下:
1、從輸入的資料點集合(要求有k個聚類)中隨機選擇一個點作為第一個聚類中心
2、對於資料集中的每一個點x,計算它與最近聚類中心(指已選擇的聚類中心)的距離D(x)
3、選擇一個新的資料點作為新的聚類中心,選擇的原則是:D(x)較大的點,被選取作為聚類中心的概率較大
4、重複2和3直到k個聚類中心被選出來
5、利用這k個初始的聚類中心來執行標準的k-means演算法
三、程式碼實現
from math import pi, sin, cos
from collections import namedtuple
from random import random, choice
from copy import copy
try:
import psyco
psyco.full()
except ImportError:
pass
FLOAT_MAX = 1e100
class Point:
__slots__ = ["x", "y", "group"]
def __init__(self, x=0.0, y=0.0, group=0):
self.x, self.y, self.group = x, y, group
def generate_points(npoints, radius):
points = [Point() for _ in xrange(npoints)]
# note: this is not a uniform 2-d distribution
for p in points:
r = random() * radius
ang = random() * 2 * pi
p.x = r * cos(ang)
p.y = r * sin(ang)
return points
def nearest_cluster_center(point, cluster_centers):
"""Distance and index of the closest cluster center"""
def sqr_distance_2D(a, b):
return (a.x - b.x) ** 2 + (a.y - b.y) ** 2
min_index = point.group
min_dist = FLOAT_MAX
for i, cc in enumerate(cluster_centers):
d = sqr_distance_2D(cc, point)
if min_dist > d:
min_dist = d
min_index = i
return (min_index, min_dist)
def kpp(points, cluster_centers):
cluster_centers[0] = copy(choice(points))
d = [0.0 for _ in xrange(len(points))]
for i in xrange(1, len(cluster_centers)):
sum = 0
for j, p in enumerate(points):
d[j] = nearest_cluster_center(p, cluster_centers[:i])[1]
sum += d[j]
sum *= random()
for j, di in enumerate(d):
sum -= di
if sum > 0:
continue
cluster_centers[i] = copy(points[j])
break
for p in points:
p.group = nearest_cluster_center(p, cluster_centers)[0]
def lloyd(points, nclusters):
cluster_centers = [Point() for _ in xrange(nclusters)]
# call k++ init
kpp(points, cluster_centers)
lenpts10 = len(points) >> 10
changed = 0
while True:
# group element for centroids are used as counters
for cc in cluster_centers:
cc.x = 0
cc.y = 0
cc.group = 0
for p in points:
cluster_centers[p.group].group += 1
cluster_centers[p.group].x += p.x
cluster_centers[p.group].y += p.y
for cc in cluster_centers:
cc.x /= cc.group
cc.y /= cc.group
# find closest centroid of each PointPtr
changed = 0
for p in points:
min_i = nearest_cluster_center(p, cluster_centers)[0]
if min_i != p.group:
changed += 1
p.group = min_i
# stop when 99.9% of points are good
if changed <= lenpts10:
break
for i, cc in enumerate(cluster_centers):
cc.group = i
return cluster_centers
def print_eps(points, cluster_centers, W=400, H=400):
Color = namedtuple("Color", "r g b");
colors = []
for i in xrange(len(cluster_centers)):
colors.append(Color((3 * (i + 1) % 11) / 11.0,
(7 * i % 11) / 11.0,
(9 * i % 11) / 11.0))
max_x = max_y = -FLOAT_MAX
min_x = min_y = FLOAT_MAX
for p in points:
if max_x < p.x: max_x = p.x
if min_x > p.x: min_x = p.x
if max_y < p.y: max_y = p.y
if min_y > p.y: min_y = p.y
scale = min(W / (max_x - min_x),
H / (max_y - min_y))
cx = (max_x + min_x) / 2
cy = (max_y + min_y) / 2
print "%%!PS-Adobe-3.0\n%%%%BoundingBox: -5 -5 %d %d" % (W + 10, H + 10)
print ("/l {rlineto} def /m {rmoveto} def\n" +
"/c { .25 sub exch .25 sub exch .5 0 360 arc fill } def\n" +
"/s { moveto -2 0 m 2 2 l 2 -2 l -2 -2 l closepath " +
" gsave 1 setgray fill grestore gsave 3 setlinewidth" +
" 1 setgray stroke grestore 0 setgray stroke }def")
for i, cc in enumerate(cluster_centers):
print ("%g %g %g setrgbcolor" %
(colors[i].r, colors[i].g, colors[i].b))
for p in points:
if p.group != i:
continue
print ("%.3f %.3f c" % ((p.x - cx) * scale + W / 2,
(p.y - cy) * scale + H / 2))
print ("\n0 setgray %g %g s" % ((cc.x - cx) * scale + W / 2,
(cc.y - cy) * scale + H / 2))
print "\n%%%%EOF"
def main():
npoints = 30000
k = 7 # # clusters
points = generate_points(npoints, 10)
cluster_centers = lloyd(points, k)
print_eps(points, cluster_centers)
main()