
解讀SSD目標檢測方法
SSD是YOLO之後又一個引人注目的目標檢測結構,它沿用了YOLO中直接回歸 bbox和分類概率的方法,同時又參考了Faster R-CNN,大量使用anchor來提升識別準確度。通過把這兩種結構相結合,SSD保持了很高的識別速度,還能把mAP提升到較高的水平。
一、基本結構與原理
原作者給了兩種SSD結構,SSD 300和SSD 512,用於不同輸入尺寸的影象識別。本文中以SSD 300為例,圖1上半部分就是SSD 300,下半部分是YOLO,可以對比來看。SSD 300中輸入影象的大小是300x300,特徵提取部分使用了VGG16的卷積層,並將VGG16的兩個全連線層轉換成了普通的卷積層(圖中conv6和conv7),之後又接了多個卷積(conv8_1,conv8_2,conv9_1,conv9_2,conv10_1,conv10_2),最後用一個Global Average Pool來變成1x1的輸出(conv11_2)。
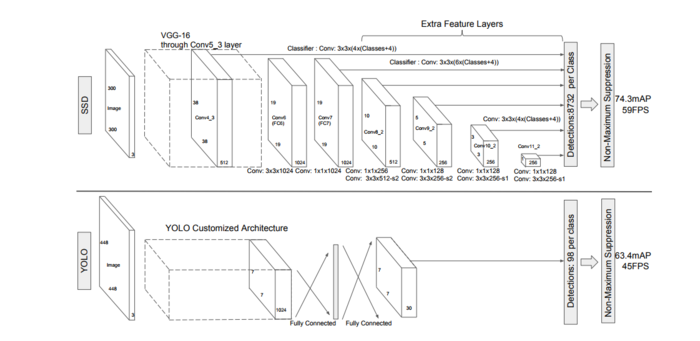 圖1:SSD 300和YOLO的結構對比
圖1:SSD 300和YOLO的結構對比
1、SSD同時使用多個卷積層的輸出來做分類和位置迴歸:
從圖1可以看到YOLO只使用了最後一層的7x7資料來做迴歸,而SSD將conv4_3、conv7、conv8_2、conv9_2、conv10_2、conv11_2都連線到了最後的檢測、分類層做迴歸。SSD這麼做有什麼好處呢?
要回答這個問題得先回顧下YOLO的結構,YOLO在訓練時ground truth和bbox是一一對應的關係(ground truth對應到其中心位置所在區域中IOU最大的那個bbox來計算loss),如果有兩個ground truth的尺寸和位置都比較相近,就很有可能對應到同一個區域的同一個bbox,這種場景下必然會有一個目標無法識別。為了解決這個問題SSD的作者把YOLO的結構做了如下優化:
a、重新啟用了Faster R-CNN中anchor的結構
在SSD中如果有多個ground truth,每個anchor(原文中稱作default box,取名不同而已)會選擇對應到IOU最大的那個ground truth。一個anchor只會對應一個ground truth,但一個ground truth都可以對應到大量anchor,這樣無論兩個ground truth靠的有多近,都不會出現YOLO中bbox衝突的情況。
b、同時使用多個層級上的anchor來進行迴歸
作者認為僅僅靠同一層上的多個anchor來回歸,還遠遠不夠。因為有很大可能這層上所有anchor的IOU都比較小,就是說所有anchor離ground truth都比較遠,用這種anchor來訓練誤差會很大。例如圖2中,左邊較低的層級因為feature map尺寸比較大,anchor覆蓋的範圍就比較小,遠小於ground truth的尺寸,所以這層上所有anchor對應的IOU都比較小;右邊較高的層級因為feature map尺寸比較小,anchor覆蓋的範圍就比較大,遠超過ground truth的尺寸,所以IOU也同樣比較小;只有圖2中間的anchor才有較大的IOU。通過同時對多個層級上的anchor計算IOU,就能找到與ground
truth的尺寸、位置最接近(即IOU最大)的一批anchor,在訓練時也就能達到最好的準確度。
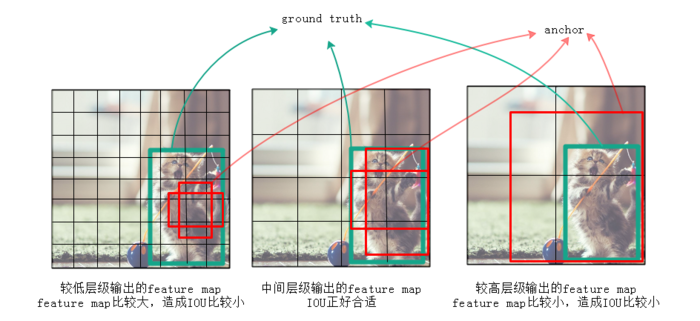 圖2:不同層級輸出的feature map上anchor的IOU差異會比較大
圖2:不同層級輸出的feature map上anchor的IOU差異會比較大
2、anchor尺寸的選擇:
下面來看下SSD選擇anchor的方法。首先每個點都會有一大一小兩個正方形的anchor,小方形的邊長用min_size來表示,大方形的邊長用sqrt(min_size*max_size)來表示(min_size與max_size的值每一層都不同)。同時還有多個長方形的anchor,長方形anchor的數目在不同層級會有差異,他們的長寬可以用下面的公式來表達,ratio的數目就決定了某層上每一個點對應的長方形anchor的數目:
公式1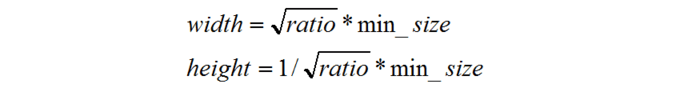 公式1
公式1
上面的min_size和max_size由公式2計算得到,Smin=0.2,Smax=0.95,m代表全部用於迴歸的層數,比如在SSD 300中m就是6。第k層的min_size=Sk,第k層的max_size=Sk+1
公式2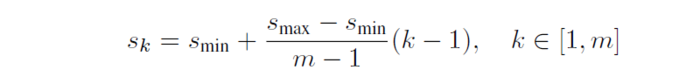 公式2
公式2
注:以上是作者論文中給的計算各層anchor尺寸的方法,但在作者原始碼中給的計算anchor方法有點差異,沒有和論文的方法完全對應上。
圖3:anchor的尺寸的選擇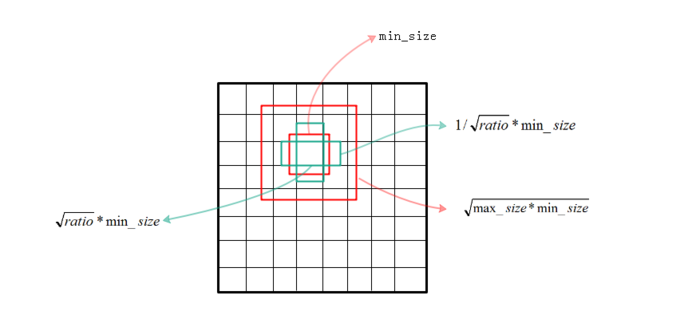 圖3:anchor的尺寸的選擇
圖3:anchor的尺寸的選擇
3、loss的計算:
SSD包含三部分的loss:前景分類的loss、背景分類的loss、位置迴歸的loss。計算公式如下:
公式3 公式4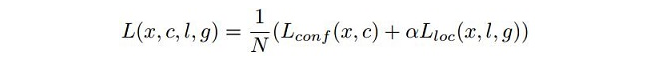 公式3
公式3
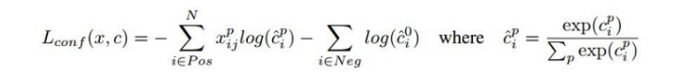 公式4
公式4
公式3中Lconf (x,c)是前景的分類loss和背景的分類loss的和,Lloc (x,l,g)是所有用於前景分類的anchor的位置座標的迴歸loss。
公式裡的N表示被選擇用作前景分類的anchor的數目,在原始碼中把IOU>0.5的anchor都用於前景分類,在IOU<0.5的anchor中選擇部分用作背景分類。只選擇部分的原因是背景anchor的數目一般遠遠大於前景anchor,如果都選為背景,就會弱化前景loss的值,造成定位不準確。在作者原始碼中背景分類的anchor數目定為前景分類anchor數的三倍來保持它們的平衡。xpij是第i個anchor對第j個ground truth的分類值,xpij不是1就是0。
Lloc (x,l,g)位置迴歸仍採用Smooth L1方法, 有不瞭解的可以去百度下,其中的α是前景loss和背景loss的調節比例,論文中α=1。
整個loss的選取如下圖,這只是個示意圖,每個點的anchor被定死成了6個來方便演示,實際應用時不同層級是不一樣的:
圖4:SSD在6個層級上進行迴歸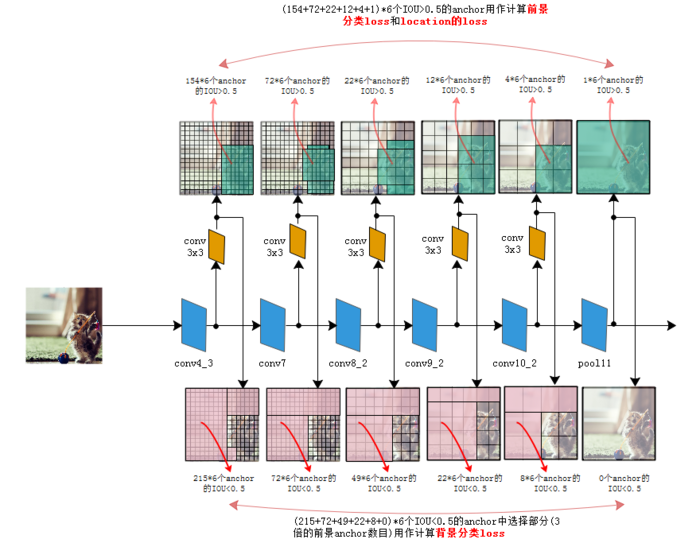 圖4:SSD在6個層級上進行迴歸
圖4:SSD在6個層級上進行迴歸
二、優缺點
SSD的優點在前面章節已經說了:通過在不同層級選用不同尺寸、不同比例的anchor,能夠找到與ground truth匹配最好的anchor來進行訓練,從而使整個結構的精確度更高。
SSD的缺點是對小尺寸的目標識別仍比較差,還達不到Faster R-CNN的水準。這主要是因為小尺寸的目標多用較低層級的anchor來訓練(因為小尺寸目標在較低層級IOU較大),較低層級的特徵非線性程度不夠,無法訓練到足夠的精確度。
下圖是各種目標識別結構在mAP和訓練速度上的比較,可以看到SSD在其中的位置:
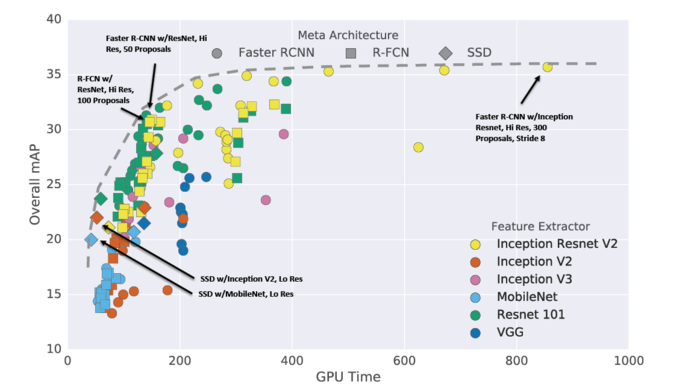 圖5:各種目標檢測結構的比較
圖5:各種目標檢測結構的比較