
對目標檢測方法yolo的理解 (二)
本文轉載自:
http://blog.csdn.net/u011534057/article/details/51244354
Reference link:
http://blog.csdn.NET/tangwei2014
這是繼RCNN,fast-RCNN 和 faster-RCNN之後,rbg(Ross Girshick)大神掛名的又一大作,起了一個很娛樂化的名字:YOLO。
雖然目前版本還有一些硬傷,但是解決了目前基於DL檢測中一個大痛點,就是速度問題。
其增強版本GPU中能跑45fps,簡化版本155fps。
本篇博文focus到方法上。實驗結果等整理全了再奉上。
1. YOLO的核心思想
-
YOLO的核心思想就是利用整張圖作為網路的輸入,直接在輸出層迴歸bounding box的位置和bounding box所屬的類別。
-
沒記錯的話faster RCNN中也直接用整張圖作為輸入,但是faster-RCNN整體還是採用了RCNN那種 proposal+classifier的思想,只不過是將提取proposal的步驟放在CNN中實現了。
2.YOLO的實現方法
- 將一幅影象分成SxS個網格(grid cell),如果某個object的中心 落在這個網格中,則這個網格就負責預測這個object。
-
每個網格要預測B個bounding box,每個bounding box除了要回歸自身的位置之外
,還要附帶預測一個confidence值。
這個confidence代表了所預測的box中含有object的置信度和這個box預測的有多準兩重資訊,其值是這樣計算的:
其中如果有object落在一個grid cell裡,第一項取1,否則取0。 第二項是預測的bounding box和實際的groundtruth之間的IoU值。 -
每個bounding box要預測(x, y, w, h)和confidence共5個值,每個網格還要預測一個類別資訊,記為C類。則SxS個網格,每個網格要預測B個bounding box還要預測C個categories。輸出就是S x S x (5*B+C)的一個tensor。
注意:class資訊是針對每個網格的,confidence資訊是針對每個bounding box的。 -
舉例說明: 在PASCAL VOC中,影象輸入為448x448,取S=7,B=2,一共有20個類別(C=20)。則輸出就是7x7x30的一個tensor。
整個網路結構如下圖所示: -
在test的時候,每個網格預測的class資訊和bounding box預測的confidence資訊相乘,就得到每個bounding box的class-specific confidence score:
等式左邊第一項就是每個網格預測的類別資訊,第二三項就是每個bounding box預測的confidence。這個乘積即encode了預測的box屬於某一類的概率,也有該box準確度的資訊。 -
得到每個box的class-specific confidence score以後,設定閾值,濾掉得分低的boxes,對保留的boxes進行NMS處理,就得到最終的檢測結果。
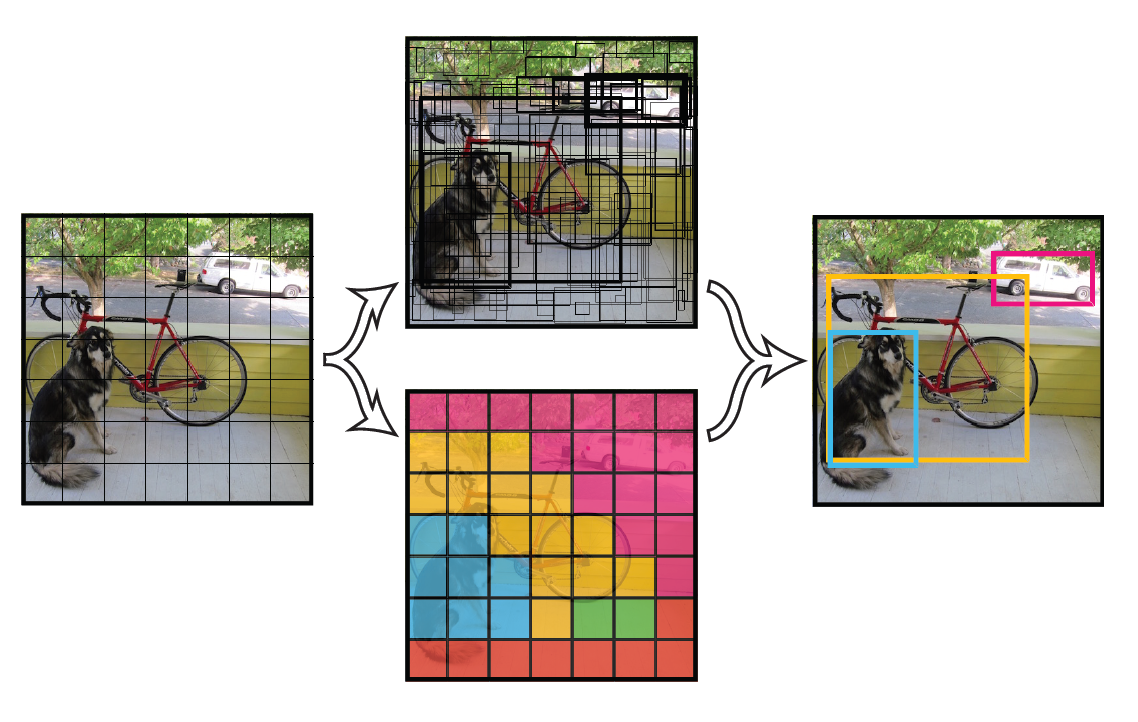

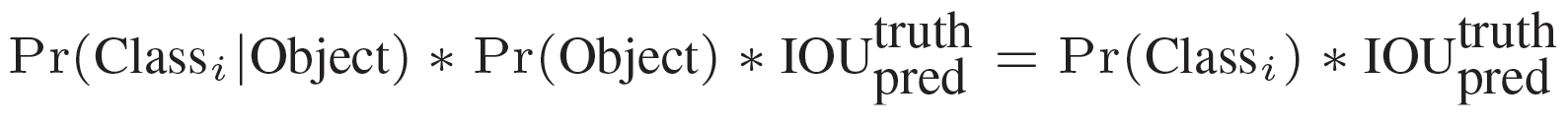
3.YOLO的實現細節
-
每個grid有30維,這30維中,8維是迴歸box的座標,2維是box的confidence,還有20維是類別。
其中座標的x,y用對應網格的offset歸一化到0-1之間,w,h用影象的width和height歸一化到0-1之間。 -
在實現中,最主要的就是怎麼設計損失函式,讓這個三個方面得到很好的平衡。作者簡單粗暴的全部採用了sum-squared error loss來做這件事。
這種做法存在以下幾個問題:
第一,8維的localization error和20維的classification error同等重要顯然是不合理的;
第二,如果一個網格中沒有object(一幅圖中這種網格很多),那麼就會將這些網格中的box的confidence push到0,相比於較少的有object的網格,這種做法是overpowering的,這會導致網路不穩定甚至發散。
解決辦法:- 更重視8維的座標預測,給這些損失前面賦予更大的loss weight, 記為
在pascal VOC訓練中取5。
- 對沒有object的box的confidence loss,賦予小的loss weight,記為
在pascal VOC訓練中取0.5。
- 有object的box的confidence loss和類別的loss的loss weight正常取1。
- 更重視8維的座標預測,給這些損失前面賦予更大的loss weight, 記為
-
對不同大小的box預測中,相比於大box預測偏一點,小box預測偏一點肯定更不能被忍受的。而sum-square error loss中對同樣的偏移loss是一樣。
為了緩和這個問題,作者用了一個比較取巧的辦法,就是將box的width和height取平方根代替原本的height和width。這個參考下面的圖很容易理解,小box的橫軸值較小,發生偏移時,反應到y軸上相比大box要大。 -
一個網格預測多個box,希望的是每個box predictor專門負責預測某個object。具體做法就是看當前預測的box與ground truth box中哪個IoU大,就負責哪個。這種做法稱作box predictor的specialization。
- 最後整個的損失函式如下所示:
這個損失函式中:- 只有當某個網格中有object的時候才對classification error進行懲罰。
- 只有當某個box predictor對某個ground truth box負責的時候,才會對box的coordinate error進行懲罰,而對哪個ground truth box負責就看其預測值和ground truth box的IoU是不是在那個cell的所有box中最大。
- 其他細節,例如使用啟用函式使用leak RELU,模型用ImageNet預訓練等等,在這裡就不一一贅述了。
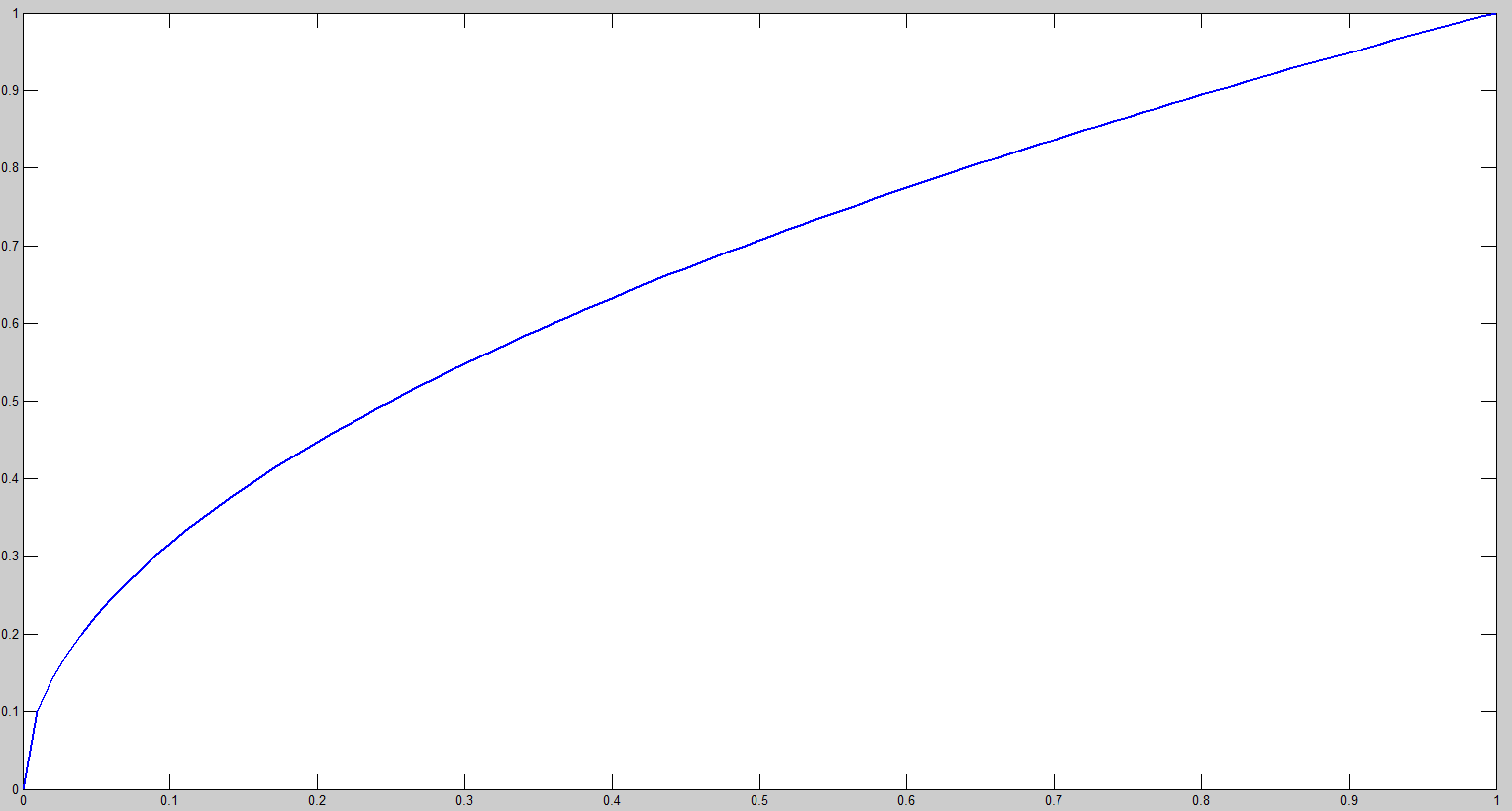

4.YOLO的缺點
-
YOLO對相互靠的很近的物體,還有很小的群體 檢測效果不好,這是因為一個網格中只預測了兩個框,並且只屬於一類。
-
對測試影象中,同一類物體出現的新的不常見的長寬比和其他情況是。泛化能力偏弱。
-
由於損失函式的問題,定位誤差是影響檢測效果的主要原因。尤其是大小物體的處理上,還有待加強。