
elasticsearch的查詢流程分析
我們都知道es是一個分散式的儲存和檢索系統,在儲存的時候預設是根據每條記錄的_id欄位做路由分發的,這意味著es服務端是準確知道每個document分佈在那個shard上的。
相對比於CURD上操作,search一個比較複雜的執行模式,因為我們不知道那些document會被匹配到,任何一個shard上都有可能,所以一個search請求必須查詢一個索引或多個索引裡面的所有shard才能完整的查詢到我們想要的結果。
找到所有匹配的結果是查詢的第一步,來自多個shard上的資料集在分頁返回到客戶端的之前會被合併到一個排序後的list列表,由於需要經過一步取top N的操作,所以search需要進過兩個階段才能完成,分別是query和fetch。
(一)query(查詢階段)
當一個search請求發出的時候,這個query會被廣播到索引裡面的每一個shard(主shard或副本shard),每個shard會在本地執行查詢請求後會生成一個命中文件的優先順序佇列。
這個佇列是一個排序好的top N資料的列表,它的size等於from+size的和,也就是說如果你的from是10,size是10,那麼這個佇列的size就是20,所以這也是為什麼深度分頁不能用from+size這種方式,因為from越大,效能就越低。
es裡面分散式search的查詢流程如下:
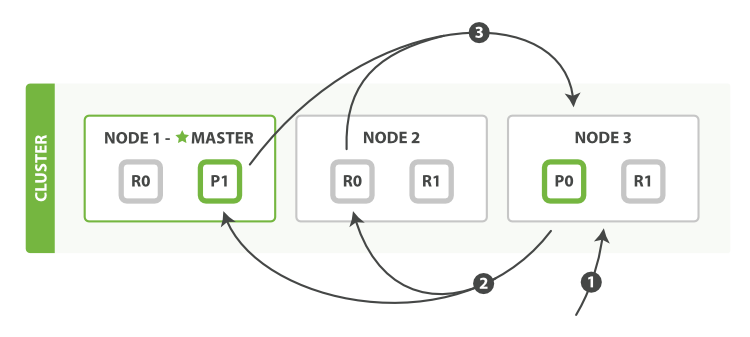
1,客戶端傳送一個search請求到Node3上,然後Node3會建立一個優先順序佇列它的大小=from+size
2 上面提到一個術語叫coordinating node,這個節點是當search請求隨機負載的傳送到一個節點上,然後這個節點就會成為一個coordinating node,它的職責是廣播search請求到所有相關的shard上,然後合併他們的響應結果到一個全域性的排序列表中然後進行第二個fetch階段,注意這個結果集僅僅包含docId和所有排序的欄位值,search請求可以被主shard或者副本shard處理,這也是為什麼我們說增加副本的個數就能增加搜尋吞吐量的原因,coordinating節點將會通過round-robin的方式自動負載均衡。
(二)fetch(讀取階段)
query階段標識了那些文件滿足了該次的search請求,但是我們仍然需要檢索回document整條資料,這個階段稱為fetch
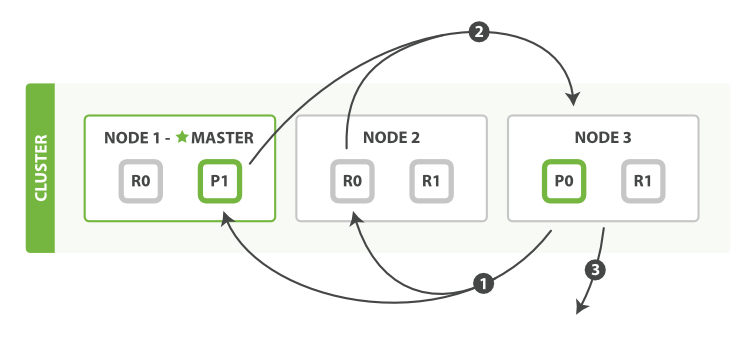
流程如下:
1,coordinating 節點標識了那些document需要被拉取出來,併發送一個批量的mutil get請求到相關的shard上
2,每個shard載入相關document,如果需要他們將會被返回到coordinating 節點上
3,一旦所有的document被拉取回來,coordinating節點將會返回結果集到客戶端上。這裡需要注意,coordinating節點拉取的時候只拉取需要被拉取的資料,比如from=90,size=10,那麼fetch只會讀取需要被讀取的10條資料,這10條資料可能在一個shard上,也可能在多個shard上所以 coordinating節點會構建一個multi-get請求併發送到每一個shard上,每個shard會根據需要從_source欄位裡面獲取資料,一旦所有的資料返回,coordinating節點會組裝資料進入單個response裡面然後將其返回給最終的client。
總結:
本文介紹了es的分散式search的查詢流程分為query和fetch兩個階段,在query階段會從所有的shard上讀取相關document的docId及相關的排序欄位值,並最終在coordinating節點上收集所有的結果數進入一個全域性的排序列表後,然後獲取根據from+size指定page頁的資料,獲取這些docId後再構建一個multi-get請求傳送相關的shard上從_source裡面獲取需要載入的資料,最終再返回給client端,至此整個search請求流程執行完畢,至於為什麼es要通過兩個階段來完成一次search請求而不是一次搞定,歡迎大家在評論區留言討論。