
Kylin執行查詢流程分析
Kylin基於MOLAP實現,查詢的時候利用Calcite框架,從儲存在Hbase的segment表(每一個segment對應著一個htable)獲取資料,其實理論上就相當於使用Calcite支援SQL解析,資料從Hbase中讀取,中間Kylin主要完成如何確定從Hbase中的哪些表讀資料,如何讀取資料,以及解析資料的格式。
場景設定
首先設想一種cube的場景:
維度:A(cardinality=10)、B(cardinality=20)、C(cardinality=30)、D(cardinality=40),其中A為mandatory維度,rowkey順序為A、B、C、D,只有一個分組。
度量:COUNT(1), SUM(X)
在這種情況下,這個cube包含如下的cuboid:ABCD、ABC、ABD、ACD、AB、AC、AD、A。目前Kylin在執行查詢的時候只能通過查詢cube進行匹配,如果能夠找到一個匹配的cube則讀取通過掃描該cube的所有segment處理該請求,首先先看一下kylin是如何處理一個SQL查詢的。
執行查詢
Kylin提供了兩種執行SQL查詢的方式:jdbc訪問和http api的訪問,前者的實現實際上是在客戶端封裝了http api請求,然後獲取結果再轉換成ResultSet物件,在執行查詢之前Kylin服務端會對查詢的SQL做快取,尤其是執行時間比較久的查詢,快取是基於SQL的內容作為key,結果作為value的,所以重複執行一個查詢會很快返回的(這是因為Kylin假設資料是隻讀的,不會被修改)。如果快取不命中則使用伺服器內嵌的Calcite建立一個向Calcite的jdbc connection,然後使用jdbc的方式獲取執行結果,在使用Calcite的時候使用者只需要給Calcite提供資料,Calcite能夠完成其他物理運算元的優化和執行,但是對於Kylin來說,它深度定製了Calcite,增加了一些優化的策略,所以總的來說查詢可以分成兩部分:1、kylin是如何使用calcite完成SQL的解析,獲取SQL的上下文;2、kylin如何從預計算的資料中獲取資料並進行計算的。
使用Calcite完成SQL解析,獲取查詢上下文
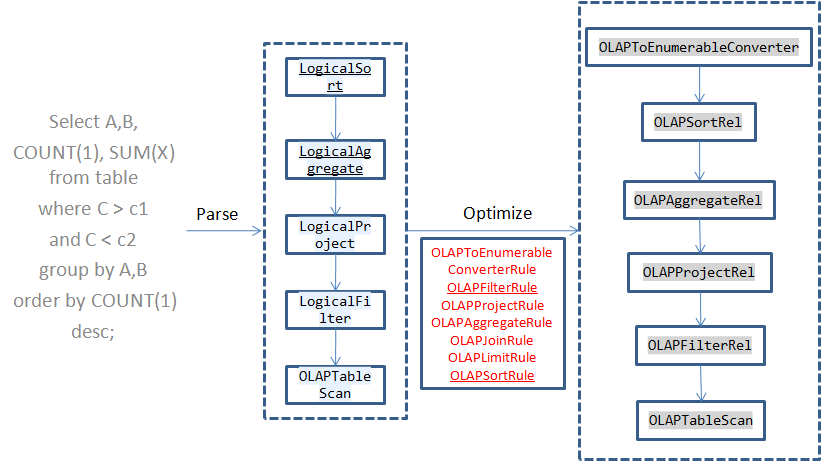
當在Calcite中執行一個SQL時,Calcite會解析得到AST樹,然後再對邏輯執行計劃進行優化,Calcite的優化規則是基於規則的,在Calcite中註冊了一些新的Rule,在優化的過程中會根據這些規則對運算元進行轉換為對應的物理執行運算元,接下來Calcite從上到下一次執行這些運算元。這些運算元都實現了EnumerableRel介面,在執行的時候呼叫implement函式:
public interface EnumerableRel extends RelNode { /** * Creates a plan for this expression according to a calling convention. * * @param implementor Implementor * @param pref Preferred representation for rows in result expression * @return Plan for this expression according to a calling convention */ Result implement (EnumerableRelImplementor implementor , Prefer pref); }
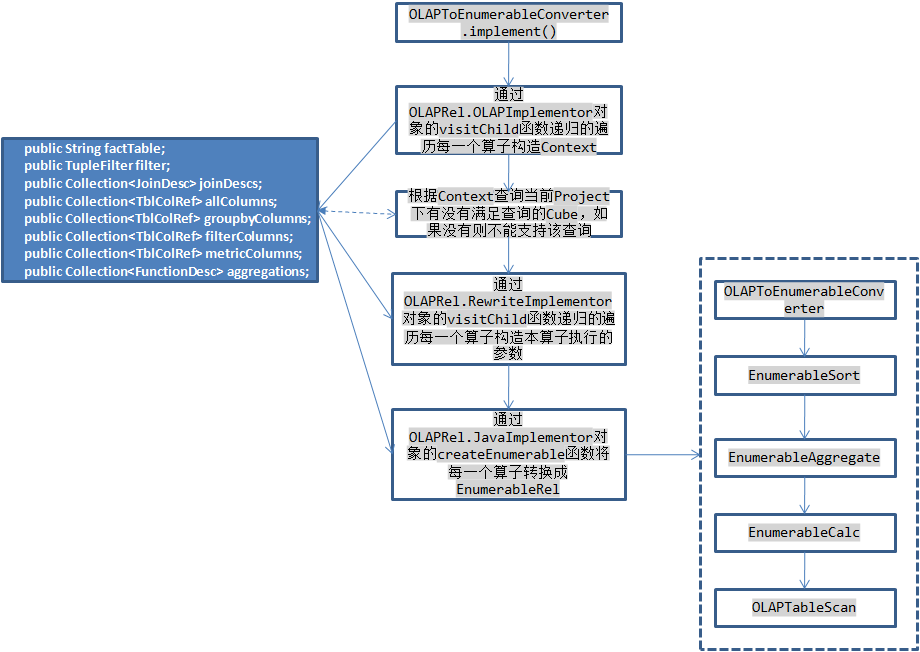
在所有Kylin優化之後的查詢樹中,根節點都是OLAPToEnumerableConverter,在它的implement函式中首先根據每一個運算元中保持的資訊構造本次查詢的上下文OLAPContext,例如根據OLAPAggregateRel運算元獲取groupByColumns,根據OLAPFilterRel運算元將每次查詢的過濾條件轉換成TupleFilter。然後根據本次查詢中使用的維度列(出現在groupByColumns和filterColumns中)、度量資訊(aggregations)查詢是否有滿足本次查詢的Cube,如果有則將其儲存在OLAPContext的realization中,獲取資料時需要依賴於它。然後再rewrite回撥函式中遞迴呼叫每一個運算元的implementRewrite函式重新構造每一個運算元的引數,最後再呼叫每一個運算元的implementEnumerable函式將其轉換成EnumerableRel物件,這一步相當於將上面生成的物理執行計劃再次轉換生成一個新的物理執行計劃。
Calcite會根據這個執行計劃動態生成執行程式碼,其中程式碼的生成根據每一個運算元的implement函式構造,並且Calcite根據運算元之間的依賴關係生成在新生成的類中構造bind函式,在bind函式中首先會執行TableScan獲取資料,資料是通過一個Enumerable物件返回的,所以OLAPTableScan需要負責產生一個該物件獲取原始資料,在執行moveNext獲取下一條記錄的時候通過filter中指定的條件對原始資料進行過濾,在current函式中執行對映返回select中指定的列資料,接著對這個Enumerable依次執行groupBy和orderBy函式,將結果返回。本次查詢的statement會根據bind函式返回的Enumerable物件構造ResultSet物件。
上面大致上介紹了Kylin利用Calcite框架執行查詢的流程,Kylin主要註冊了幾個優化規則,在每一個優化規則中將對應的物理運算元轉換成Kylin自己的OLAPxxxRel運算元,然後再將每一個運算元根據本次查詢的引數生成Calcite自身的EnumerableXXX運算元執行,比較特殊的是OLAPTableScan並不會轉換成其他的運算元,同樣的還有OLAPJoinRel(當執行的sql有JOIN是會產生該運算元),這OLAPTableScan運算元的implement函式實現如下:
@Override
public Result implement(EnumerableRelImplementor implementor, Prefer pref ) {
PhysType physType = PhysTypeImpl. of(implementor.getTypeFactory(), this.rowType , pref .preferArray());
String execFunction = genExecFunc();
MethodCallExpression exprCall = Expressions.call(table.getExpression(OLAPTable. class), execFunction , implementor.getRootExpression(), Expressions.constant( context. id));
return implementor .result(physType , Blocks.toBlock( exprCall));
}
private String genExecFunc() {
// if the table to scan is not the fact table of cube, then it's a lookup table
if (context .hasJoin == false && tableName.equalsIgnoreCase(context .realization .getFactTable()) == false) {
return "executeLookupTableQuery" ;
} else {
return "executeIndexQuery" ;
}
}
可以看出它根據MethodCallExpression物件exprCall執行Blocks.toBlock生成對應的程式碼段(在bind函式中呼叫),例如本例中生成的程式碼段如下:
final org.apache.calcite.linq4j.Enumerable _inputEnumerable = ((org.apache.kylin.query.schema.OLAPTable)
root.getRootSchema().getSubSchema("databaseName").getTable("tableName")).executeIndexQuery(root, 0);
返回的Enumerable是由executeIndexQuery函式返回的,在genExecFunc函式中會判斷是根據之前生成的查詢上下文OLAPContext,如果本次查詢沒有join並且查詢的表不是當前使用的Cube的事實表,則使用executeLookupTableQuery函式,否則(有join或者查詢事實表)則使用executeIndexQuery函式。
而在OLAPJoinRel的implement函式的實現則是直接使用executeIndexQuery函式。
@Override
public Result implement(EnumerableRelImplementor implementor, Prefer pref ) {
PhysType physType = PhysTypeImpl. of(implementor.getTypeFactory(), getRowType(), pref.preferArray());
RelOptTable factTable = context .firstTableScan .getTable();
MethodCallExpression exprCall = Expressions.call(factTable.getExpression(OLAPTable. class), "executeIndexQuery" , implementor.getRootExpression(), Expressions.constant( context. id));
return implementor .result(physType , Blocks.toBlock( exprCall));
}
為什麼是這兩個不同的函式呢?這是由於在Kylin中預計算了所有可能的組合值儲存在hbase中,rowkey為值的組合,例如A=”abc”,B=”xyz”就對應著一條記錄,value為select count(1), sum(X) from table where A=”abc” and B=”xyz”的返回值,所以對於事實表中的資料都是需要進行計算的,儲存在hbase中,只能通過訪問hbase獲取,而Kylin會儲存所有維度表的資訊,在記憶體中生成SnapshotTable,這樣對維度表的查詢則不需要掃描hbase了。
Kylin從Hbase中獲取資料
上面吧Calcite解析和執行部分介紹完了,在bind函式中需要返回一個Enumerable物件給Calcite執行接下來的過濾、Project、groupBy、orderBy、limit等操作,這裡不關注只對維度表的查詢,而是看一下Kylin如何從Hbase中獲取資料的。首先這個Enumerable物件時OLAPTable的executeIndexQuery函式返回的。
public Enumerable<Object[]> executeIndexQuery(DataContext optiqContext, int ctxSeq) {
return new OLAPQuery(optiqContext, EnumeratorTypeEnum. INDEX, ctxSeq );
}
它的enumerator函式如下:
public Enumerator<Object[]> enumerator() {
OLAPContext olapContext = OLAPContext.getThreadLocalContextById( contextId);
switch (type ) {
case INDEX :
return new CubeEnumerator(olapContext, optiqContext);
case LOOKUP_TABLE :
return new LookupTableEnumerator(olapContext);
case HIVE :
return new HiveEnumerator(olapContext);
default:
throw new IllegalArgumentException("Wrong type " + type + "!");
}
}
在CubeEnumerator中主要由current返回當前的資料,moveNext檢視是否還有資料,它們完成了一個迭代器的功能:
@Override
public Object[] current() {
return current ;
}
@Override
public boolean moveNext() {
if (cursor == null) {
cursor = queryStorage();
}
if (!cursor .hasNext()) {
return false ;
}
ITuple tuple = cursor.next();
if (tuple == null) {
return false ;
}
convertCurrentRow (tuple );
return true ;
}
queryStorage函式返回一個迭代器,所有的資料都是通過這個迭代器獲得,其中current變數是在covertCurrentRow函式中根據hbase中的資料解碼之後的值,為什麼需要解碼呢?首先hbase中儲存的都是二進位制的資料,然後由於維度的成員的值可能會佔用很大的空間,如果儲存原始值的話會造成:1、hbase儲存空間增大,2、相同cuboid的rowkey的長度不一樣,所以Kylin在構建Cube的時候會將每一個維度下的成員進行編碼,每一個維度中的每一個成員編碼程一個從0開始的整數值,儲存在hbase中的資料是這些編碼值的二進位制組合,因此讀取到這些值之後需要解碼獲取原始的維度值。
querySorage函式主要執行邏輯:
IStorageEngine storageEngine = StorageEngineFactory.getStorageEngine( olapContext.realization );
ITupleIterator iterator = storageEngine.search(olapContext .storageContext , olapContext.getSQLDigest());
首先根據本次查詢選中的Cube生成storageEngine物件,然後通過search方法返回一個迭代器,從其中獲取全部資料。CubeStorageEngine是在Cube中獲取資料使用的engine,它的search方法執行邏輯如下:
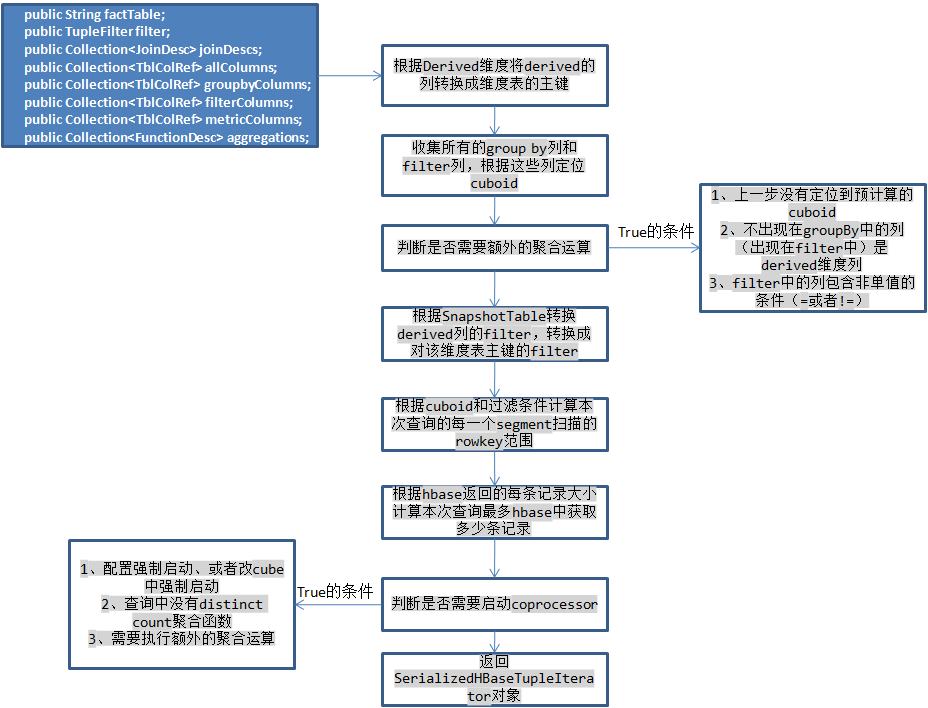
由於線上程區域性變數中儲存了本次查詢的OLAPContext,可以根據它儲存的資訊獲取根據哪些列group by和filter,以及對哪些度量進行計算,此時需要考慮derived維度,這種維度實際上會被它所在的維度表的主鍵代替,所以需要將這些列轉換為主鍵列,並根據snapshotTable修改filter物件,然後判斷本次查詢是否需要啟動hbase的coprocessor,Kylin對於每一個htable都設定了一個observer型別的coprocessor,當執行scan操作之前會回撥這個類的doPostScannerObserver函式,執行對錶中的原始記錄執行一些過濾和聚合運算,這樣可以減小每一個scan返回的記錄數,例如執行select A,count(1) from table where B > 1 and C not in (”) group by A,這樣的查詢可以根據B>1計算出本次查詢需要掃描的rowkey範圍,而C not in (”)則需要在coprocessor對掃描獲得的每一條記錄執行判斷,如果滿足才可以從hbase中返回。例如上例中查詢出現了A/B/C維度,但是這個cuboid並沒有預計算,此時只能定位到A/B/C/D這個cuboid,在coprocessor中需要再根據D這一列執行聚合,進一步減小返回記錄數。
關於記憶體
1、首先在coprocessor中,它是在hbase的regionServer中執行的,所以不能佔用hbase太多的記憶體,Kylin在這裡做的記憶體限制是500MB,因為需要執行額外的聚合運算,因此在coprocessor中維護了一個map儲存每一個需要返回的記錄並且持續的執行聚合運算,但是如果查詢中帶有distinct count的聚合運算,Kylin使用HLL實現的,每一個聚合值大概佔用32KB大小(根據精確度),所以如果查詢中有這樣的聚合函式會很快消耗完這些記憶體,所以這種聚合的查詢不會啟動coprocessor。
2、對於返回的記錄,只是原始的資料,需要再交給calcite完成下面的聚合、過濾和排序等操作,但是既然coprocessor中都已經把過濾和聚合做完了,為什麼還要在coprocessor中做呢?filter的確是在Kylin中已經完成的了,再使用Calcite執行過濾是為了正確性的保證,但是這樣也限制的Kylin不能支援全部的Calcite的過濾(這裡可以擴充套件,Kylin只處理自己能處理的,剩餘由Calcite處理),至於還需要聚合運算是因為一個Cube查詢可能涉及到多個segment,因此這些segment可能返回相同的key,此時就需要Calcite執行聚合運算,運算函式是由Kylin指定的,但是需要將所有從hbase中返回的記錄儲存在記憶體中,Kylin為每一個查詢設定了最大記憶體記憶體上線為3GB,根據每一個key-value的大小計算出hbase最多返回的記錄數,如果超出這個數則根據配置是否接受部分結果,如果不接受則返回查詢失敗,如果接受則指根據已返回的記錄進行Calcite的運算,可能出現錯誤。
獲取資料
將filter轉換為扁平式的使用AND連線filter,然後每一個childFilter可以根據不同的segment生成一個keyRange,這裡成為ColumnKeyRange,每一個segment中有多個ColumnKeyRange,由於每一個segment對應著一個htable,所以首先會嘗試merge每一個segment下的ColumnKeyRange(根據是否有重合的範圍),生成多個HBaseKeyRange(merge之後的多個範圍,直接對應著hbase中rowkey的範圍),根據這些HBaseKeyRange生成SerializedHBaseTupleIterator。
在這個SerializedHBaseTupleIterator迭代器中按照每一個segment下的HbaseKeyRange建立一個map,segment為key,這個segment下需要掃面的HbaseKeyRange陣列作為value,然後為每一個Segment建立一個CubeSegmentTupleIterator物件,它中保持了多個HbaseKeyRange,然後對每一個HbaseKeyRange建立Scan物件,接著使用該物件向Hbase發起一個scan請求,上面每一個迭代器都是對它包含的迭代器陣列的封裝。
總結
本文介紹了Kylin如何處理Sql的查詢,充分利用了Calcite的sql解析和優化的功能,可以看到Calcite是一個非常強大的SQL引擎框架,Kylin較深入的定製了Calcite的功能,對於Calcite的初級使用可以參考:http://blog.csdn.net/yu616568/article/details/49915577,而Kylin提供從Hbase中讀取資料返回前端又有點類似於phoenix的做法(它也是通過Calcite完成解析和優化的),但是後者更加通用一些。Kylin 2.0中把儲存做成外掛式的,理論上可以支援更多的儲存元件(需要支援scan和類似coprocessor的功能啊),但是基本上查詢流程是類似的。本文如果有什麼錯誤,還請多多指正,謝謝~