
基於深度學習的單目影象深度估計
基於深度學習的單目深度估計算近年比較火的方向
之前蒐集過相關的論文,嘗試回答一下。
NIPS2014,第一篇CNN-based來做單目深度估計的文章。
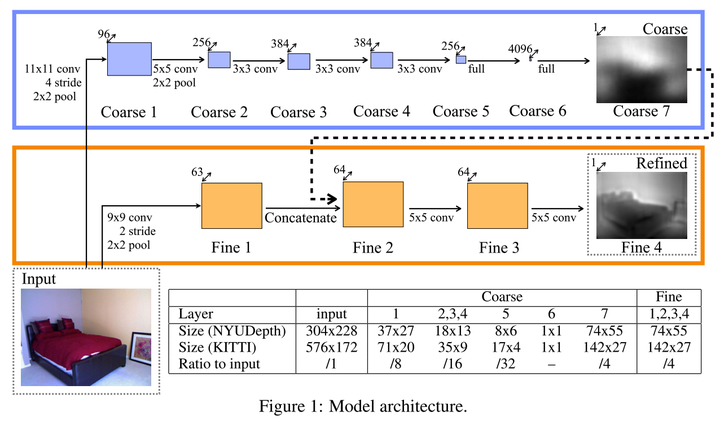
基本思想用的是一個Multi-scale的網路,這裡的Multi-scale不是現在網路中Multi-scale features的做法,而是分為兩個scale的網路來做DepthMap的估計,分別是Global Coarse-Scale Network和Local Fine-Scale Network。前者其實就是AlexNet,來得到一個低解析度的Coarse的Depth Map,再用後者去refine前者的輸出得到最後的refined depth map.
ICCV2015,也是上一篇作者David Eigen發的,號稱是multi-task的一個network.

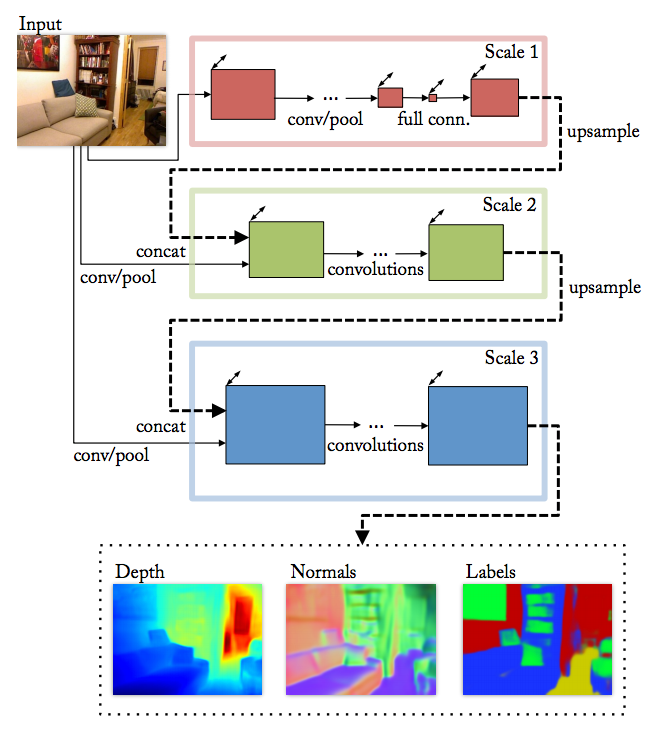
網路結構上做了一些改進,從兩個scale增加到了三個scale,scale1考慮了用VGG替換AlexNet,這篇沒細看,有錯請指出~
掛在Arxiv1607上的,在上一篇的基礎上做了一些改進。
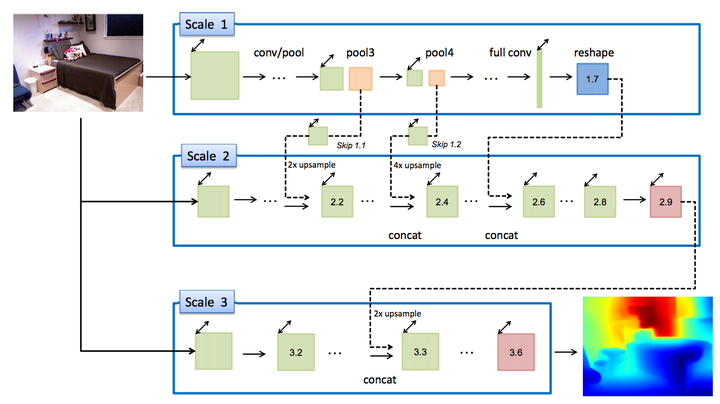

主要的contributions:
1.在ICCV2015的基礎上加入了multi-scale之間的skip connections,號稱可以加速網路的收斂。
2.考慮了在做Data Augmentation的時候,相同的資料生成的train data之間的相關性,其恢復得到的深度要儘可能接近,因此構建了基於set of transformed images的loss的約束。
Arxiv1604,分割和單目深度估計Joint的文章。。。然而。
IEEE 3D Vision 2016的文章,用ResNet的結構來做了。
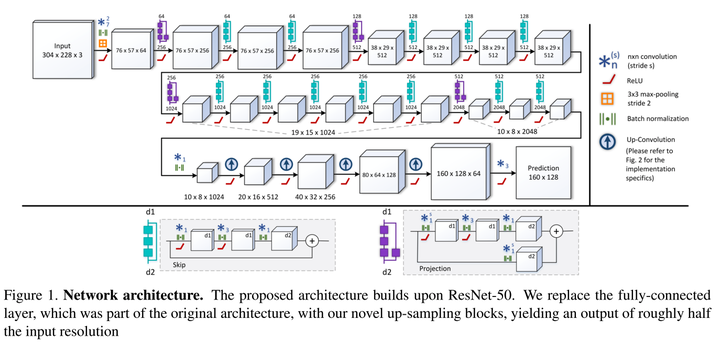
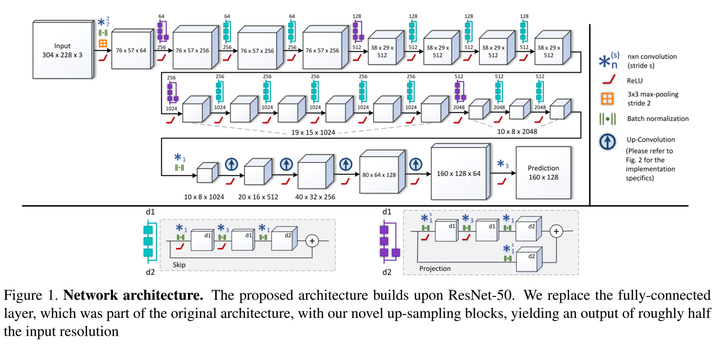
Deconv部分提出了幾個版本,如下圖.
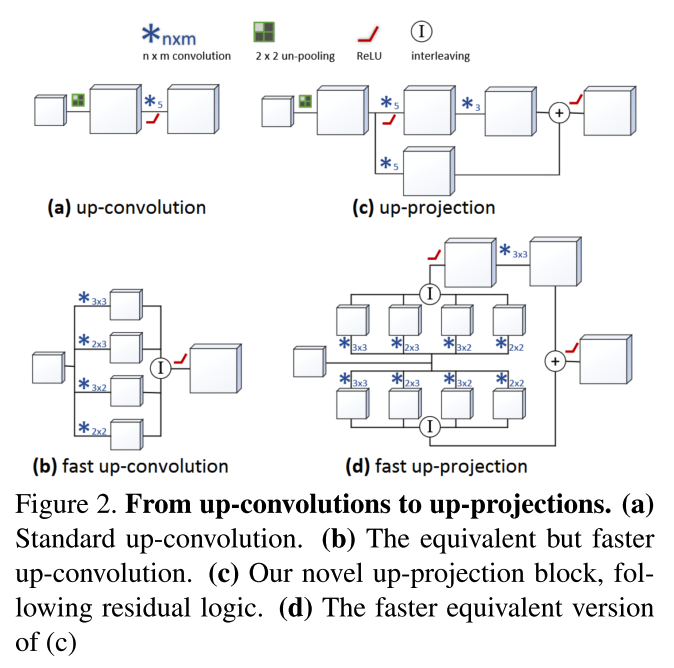
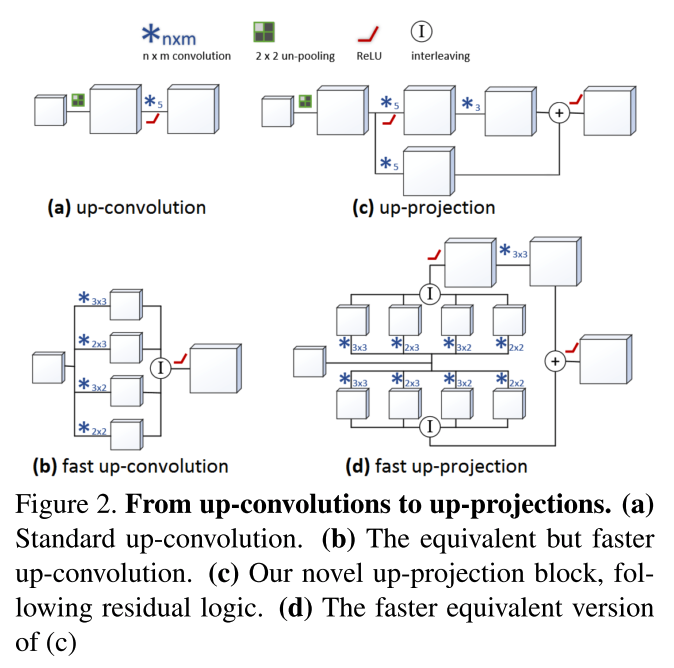
1. up-convolution:基本的unpooling+convolution
2. up-projection: 引入了殘差的up-convolution單元
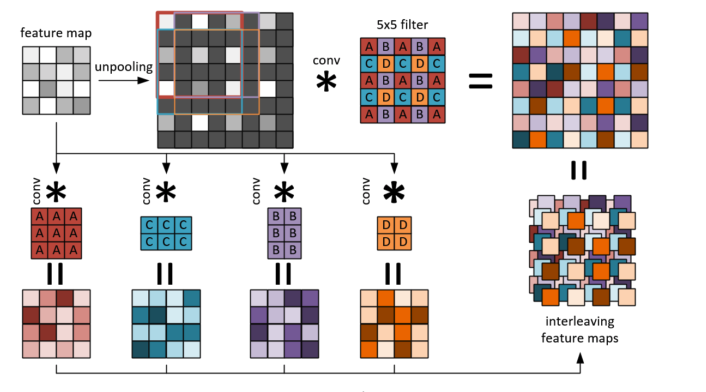
3. 兩者的fast版本,基本思想就是unpooling+5*5的conv可以用4個更小的conv來實現,從而加速,如下圖

CVPR2017也有3篇。
這篇沒細看,思想應該是loss不是直接用的depth的loss.
而是用估計出來的depthmap來做左右圖的匹配,利用匹配後rgb影象的強度的偏差來構建loss,所以說是unsupervised.
這篇是semi-supervised,網路結構基本用的是上面的FCRN,主要在loss上做了手腳。
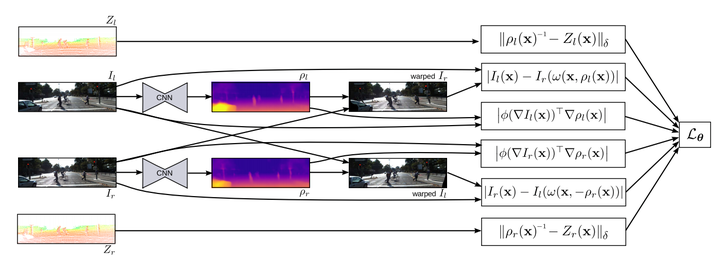
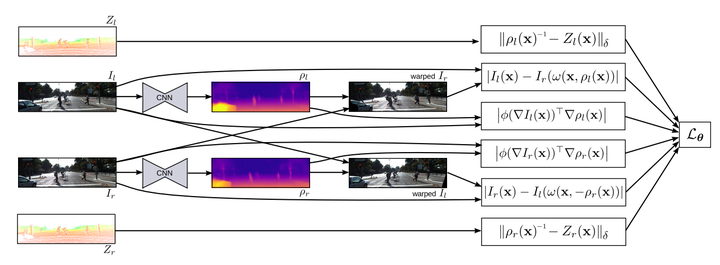
loss一共分為Supervised loss,Unsupervised loss,Regularization loss
1.Unsupervised loss
和上一篇unsupervised的一樣,用的也是網路inference得到depthmap後做左右rgb影象匹配構建的loss.
2.Supervised loss
同時因為用的是kitti的資料,有雷達影象資料配準後的sparse的深度值圖,將這些sparse的depth values作為seed點,也引入了loss中。
3.Regularization loss
還添加了gradient的Regularization loss作為約束。
所以個人感覺是,這篇文章是上兩篇文章的結合。
xiaogang wang他們的成果,這篇主要是CNN和Graphical Model的結合。
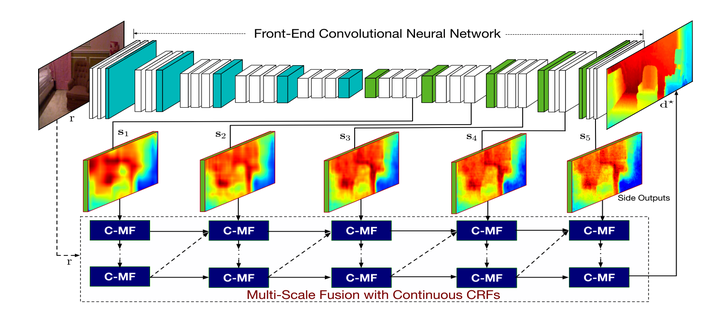
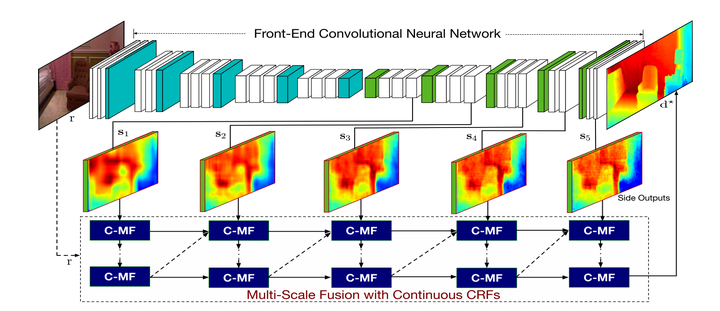
主要的motivation:
1.在CNN解決pixel級的classification/regression問題時,引入multi-scale的資訊可以更好的結合low-level和high-level的feature。
2.在semantic segmentation問題中,CRFasRNN中將CRF的mean-field解法展開用RNN網路的結構實現,使得CNN+CRF可以進行end-to-end的優化,這是針對discrete domain的問題,而對於continuous domain的regression問題,還沒有這樣翻譯成網路的CRF層的存在。
3.以及圖模型有很好的表達能力,可以與CNN模型的特徵表達結合,得到更好的效果。
因此作者提出了Multi-scale CRFs和Cascade CRFs兩個模組。
具體推導不展開,有興趣的可以看論文,兩個CRFs的最小單元可以用一個C-MF block來實現。