
C&C控制服務的設計和偵測方法綜述
這篇文章總結了一些我在安全工作裡見到過的千奇百怪的C&C控制伺服器的設計方法以及對應的偵測方法,在每個C&C控制服務先介紹黑帽部分即針對不同目的的C&C伺服器設計方法,再介紹白帽部分即相關偵測辦法,大家來感受一下西方的那一套。這裡的白帽部分有一部分偵測方法需要一些資料和統計知識,我也順便從原理上簡單討論了一下用資料進行安全分析的方法,從數學和資料原理上思考為什麼這麼做,可以當作資料科學在安全領域的一些例子學習一下。
0x00 什麼是C&C伺服器
C&C伺服器(又稱CNC伺服器)也就是 Command & Control Server,一般是指揮控制僵屍網路botnet的主控伺服器,用來和僵屍網路的每個感染了惡意軟體(malware)的宿主機進行通訊並指揮它們的攻擊行為。每個malware的例項通過和它的C&C伺服器通訊獲得指令進行攻擊活動,包括獲取DDoS攻擊開始的時間和目標,上傳從宿主機偷竊的到的資訊,定時給感染機檔案加密勒索等。
為什麼malware需要主動和C&C服務通訊?因為多數情況下malware是通過釣魚郵件啊等方法下載到感染宿主機,攻擊者並不能主動得知malware被誰下載,也不能主動得知宿主機的狀態(是否開機是否聯網等),除非malware主動告訴他,所以malware都會內建一套尋找C&C主控伺服器的方法以保持和C&C的聯絡和斷線重連。C&C控制服務的攻防要點在於,攻擊者能不能欺騙防禦者成功隱藏C&C服務:如果防禦者偵測到了隱藏的C&C服務,通過一些技術(封禁域名和IP等)或者非技術手段(彙報給安全應急中心等)切斷malware和C&C之間的聯絡,就可以有效的摧毀botnet。
尋找到C&C之後malware和C&C之間的通訊方式並不是本文攻防重點,它可以是SSH檔案傳輸也可以是簡單的HTTP GET和POST,技巧性不是很大,不多的幾個靠傳輸來隱藏的技巧比如用DNS隧道隱藏流量這類方法如果有需要以後再來一發詳細闡述。
0x01 IP地址:難度低,易被抓
這是最常見的一類C&C伺服器。攻擊者在惡意軟體的程式碼裡硬編碼寫上C&C伺服器的IP地址,然後在需要和C&C通訊的時候用HTTP拉取需要的攻擊指令或者上傳從宿主感染機上盜取的資訊等等。
這並不是一個高階的辦法,因為如果malware的二進位制程式碼被獲取,這種用IP的方法很容易被安全人員通過反向工程二進位制程式碼或者檢測蜜罐流量得到C&C伺服器的地址,從而彙報給服務提供商封禁IP。所以這種方法並不能有效隱藏C&C服務,IP被抓了被反毒軟體更新病毒庫以後整個botnet就被摧毀了。現在國內的多數malware的主控伺服器都是以這種拼運氣不被抓的方式存在,他們靠的是malware數量多,今天抓一個當天就再出來三個,市場競爭很激烈。
國外用IP的C&C伺服器一般是在Amazon AWS之類的雲伺服器上,通知了服務提供商很容易封禁IP。國內的雲服務商態度曖昧,不過也算還行吧。有機智的國內malware作者在東南亞地區租用雲服務IP,可以有效避開國內監管而且速度不錯(我並不是教你這麼做啊)。
安全人員也不要以為這個方法低階就以為能輕易有效防禦,比如說如果感染機不能安裝防毒軟體或者根本你就不知道中毒了。最近的一個例子是最近比較火的植入路由器的Linux/Xor.DDOS,它的C&C控制就是在AWS上面的IP,造成的影響很大,因為多數人並不知道路由器會被大規模植入惡意軟體,路由器本身也很少有防護,正好適合用IP做C&C,還省去了複雜的域名演算法和DNS查詢的程式碼保證了軟體本身的輕量化。也由於路由本身常開的特性,路由木馬也不用擔心失去連結,一次C&C的通訊可以保持連線很久,降低了木馬被發現的機會。技巧雖然不華麗,但是用的好還是威力強大。該木馬的詳細分析參見http://blog.malwaremustdie.org/2015/09/mmd-0042-2015-polymorphic-in-elf.html 。
0x02 單一C&C域名:難度較低,易被抓
因為硬編碼的IP容易通過在二進位制碼內的字串段批量regex掃描抓到,一個變通的辦法就是申請一些域名,比如idontthinkyoucanreadthisdomain.biz代替IP本身,掃描二進位制碼就不會立刻找到IP欄位。這是個很廣泛使用的方法,通常C&C域名會名字很長,偽裝成一些個人主頁或者合法生意,甚至還有個假的首頁。即使這麼用心,這種方法還是治標不治本,偵測的方法也相對簡單,原因是:
安全廠商比如Sophos等的資深安全人員經驗豐富,他們會很快人工定位到惡意軟體可能包含C&C域名的函式,並且通過監測蜜罐的DNS查詢資料,很快定位到C&C域名。這些定位的域名會被上報給其他廠商比如運營商或者VirusTotal的黑名單。
新的C&C域名會在DNS資料的異常檢測裡面形成一些特定的模式,通過資料做威脅感知的廠商很容易偵測到這些新出現的奇怪域名,並且通過IP和其他網路特徵判定這是可疑C&C域名。
所以常見的C&C域名都在和安全廠商的黑名單比速度,如果比安全研究員反向工程快,它就贏了,但是最近的格局是隨著基於資料的威脅感知越來越普遍,這些C&C域名的生命週期越來越短,運氣不好的通常活不過半個小時。攻擊者也會設計更復雜的辦法隱藏自己,因為註冊域名需要一定費用,比如帶隱私保護的.com域名需要好幾十美元,尋找肉雞植入木馬也要費很大功夫,本來準備大幹一場連攻半年結果半個小時就被封了得不償失。
在這個速度的比賽裡,一個低階但是省錢方便技巧就是用免費二級域名,比如3322家族啊vicp家族等不審查二級域名的免費二級域名提供商,最著名的例子就是Win32/Nitol家族,搞的微軟靠法院判來3322.org的所有權把他們整個端了(雖然後來域名控制權又被要回去了)。這個方法是國內malware作者最喜歡的一個方法,資料裡常見一些漢語拼音類的C&C域名,比如woshinidie.3322.org等喜感又不忘佔便宜的二級域名,可能因為在我國申請頂級域名麻煩還費錢容易暴露身份,不如悶聲發大財。你看,這也不是我在教你這麼做啊。
真正有意思的是技術是,比較高階的C&C域名都不止一個,通過一個叫做fast flux的辦法隱藏自己。
0x03 Fast flux, double flux and triple flux
攻擊者對付傳統蜜罐和二進位制分析的辦法就是不要依靠單一C&C,取而代之的是快速轉換的C&C域名列表(fast flux技術):攻擊者控制幾個到幾十個C&C域名,這些域名都指向同一個IP地址,域名對應IP的DNS record每幾個小時或者幾天換一次,然後把這些C&C域名分散的寫到malware的程式碼裡面。對於傳統二進位制分析來說,掛一漏萬,如果不能把整個C&C域名列表裡面的所有域名放到黑名單上,就不能有效的摧毀這個惡意軟體。這就比賽攻擊者的隱藏程式碼能力和防禦者的反向工程以及蜜罐監測能力了。這種方法叫做Fast flux,專門設計用來對付安全人員的人工分析。
防禦Fast flux的方法在流量資料裡看相對容易,比如威脅感知系統只需要簡單的把每個域名解析指向的IP的歷史資料按照IP做一次group by就抓住了,利用資料並不難嘛。所以應運而生有更高階double flux和triple flux的辦法。
如果攻擊者比較有錢,租用了多個IP地址,那麼他可以在輪換C&C域名的同時輪換IP地址,這樣M個C&C域名和N個IP地址可以有M*N種組合,如果設計的輪換時間稍微分散一些,會讓蜜罐流量分析缺乏足夠的資料支援。偵測double flux的辦法需要一些簡單的圖知識(請繫好安全帶在家長陪同下觀看):
如果把每個域名和IP地址當做圖的節點V,一個有效的域名-IP記錄當做對應兩個節點的邊E,那麼整個流量資料就可以表示為一個由V_域名指向V_IP的二分有向圖。Double flux的圖就是這個巨大二分有向圖裡的互相為滿射的完全二分圖,換句人話就是,存在這樣一個子圖,當中每個V_域名節點都指向同樣一個集合的V_IP節點,而每個V_IP節點都被同一個集合的V_域名節點指向。圖示如下:
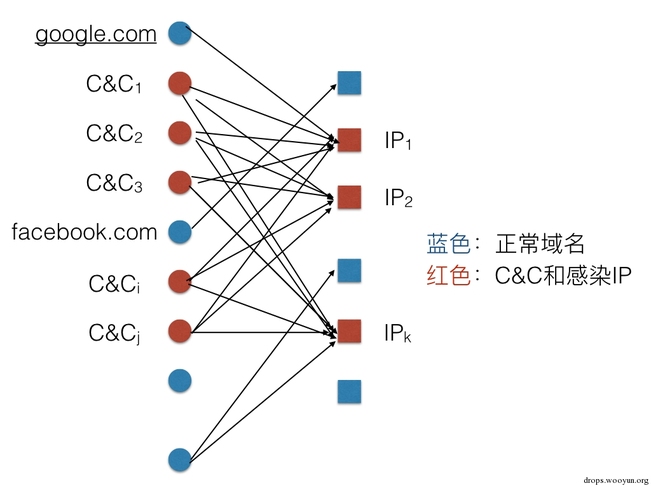
當然了,感染的IP可以訪問別的域名,比如圖中google.com。在實際情況裡,由於資料採集時間的限制,每個IP節點都要訪問所有C&C域名這個條件可以放寬。
當攻擊者得知安全人員居然可以用圖論的方法幹掉他們的double flux這麼高階的設計方法之後,更瘋狂的triple flux出現了:每個域名的記錄裡不僅可以新增A record也就是IP的指向,還可以選定不同的命名伺服器Name server來解析這個域名,如果攻擊者足夠有錢(以及有時間精力),他可以控制K個name server定時或者不定時輪換,這樣可以造成M\*N\*K種組合。
Triple flux方法看似機智,好像跑得比誰都快,其實在實現上聰明反被聰明誤,漏洞就在name server的設定上:多數正常服務的name server都是專有服務,而多數C&C多架設在免費name server比如DNSpod的免費伺服器上。如果攻擊者能夠控制自己的一系列name server專門作fast flux,這些server並不是常見的name server。任何非常見的伺服器域名都會在流量資料的異常檢測裡面被監測出來,上一節裡面提到異常檢測偵測C&C域名的方法對triple flux裡面的name server也是可用的。你看,攻擊者Naive了吧。
對於fast flux這一類特定flux類方法的監測還有另外一個基於資料和機器學習的方法:如果仔細思考一下fast flux,我們也會發現攻擊者試圖創造一個聰明的辦法,但這種辦法本身有一個致命缺陷,也就是追求fast,它的域名對IP的記錄轉換太快了,導致每個域名紀錄的存活時間TTL被迫設計的很短,而絕大多數的正常服務並不會有如此快速的域名對應IP的記錄轉換,大型網站的負載均衡和CDN服務的IP紀錄轉換和fast flux有截然不同的特徵。這些特徵可以很容易被機器學習演算法利用判別fast flux的僵屍網路,相關研究可以參看比如https://www.syssec.rub.de/media/emma/veroeffentlichungen/2012/08/07/Fastflux-Malware08.pdf等較早研究fast flux的論文。
0x04 使用隨機DGA演算法:難度較高,不易被抓
DGA域名生成演算法 (Domain Generation Algorithm) 是現在高階C&C方法的主流,多見於國外各大活躍的惡意軟體裡,在VirusTotal裡如果見到看似隨機的C&C域名都算這一類。它的基本設計思想是,絕不把域名字串放到malware程式碼裡,而是寫入一個確定隨機演算法計算出來按照一個約定的隨機數種子計算出一系列候選域名。攻擊者通過同樣的演算法和約定的種子算出來同樣列表,並註冊其中的一個到多個域名。這樣malware並不需要在程式碼裡寫入任何字串,而只是要卸乳這個約定就好。這個方法厲害在於,這個隨機數種子的約定可以不通過通訊完成,比如當天的日期,比如當天twitter頭條等。這種方法在密碼學裡稱之為puzzle challenge,也就是控制端和被控端約好一個數學題,有很多答案,控制端選一個,被控端都給算出來,總有一個答上了。
一個簡單的例子(引用自wikipedia)比如說這段程式碼可以用今天2015年11月3日當做種子生成cqaqofiwtfrbjegt這個隨機字串當做今天的備選C&C域名:
def generate_domain(year, month, day):
“””Generates a domain name for the given date.”””
domain = “”
for i in range(16):
year = ((year ^ 8 * year) >> 11) ^ ((year & 0xFFFFFFF0) << 17)
month = ((month ^ 4 * month) >> 25) ^ 16 * (month & 0xFFFFFFF8)
day = ((day ^ (day << 13)) >> 19) ^ ((day & 0xFFFFFFFE) << 12)
domain += chr(((year ^ month ^ day) % 25) + 97)
return domain
DGA方法的代表做就是Conficker,它的分析論文可以在這裡找到:http://www.honeynet.org/papers/conficker 它的基本思想是用每天的日期當做隨機數種子生成幾百到幾千不等的偽隨機字串,然後在可選的域名字尾比如.com .cn .ws裡面挑選後綴生成候選的C&C域名,攻擊者用同樣演算法和種子得到同樣的列表,然後選擇一個註冊作為有效的C&C。安全人員即使抓到了二進位制程式碼,在組合語言裡面反向出來這個隨機數生成演算法也遠比搜尋字串難的多,所以DGA是個有效防止人工破解的方法。最近幾年使用DGA演算法的惡意軟體裡,Conficker的方法是被研究人員反向工程成功,Zeus是因為原始碼洩漏,其他的解出來DGA演算法的案例並不多。
如果一個DGA演算法被破解,安全人員可以用sinkhole的辦法搶在攻擊者之前把可能的域名都搶注並指向一個無效的IP。這種方法雖然有安全公司在做,但費時費力,是個絕對雷鋒的做法,因為註冊域名要錢啊,每天備選的域名又很多,都給註冊了很貴的。現在常見的Torpig之類的C&C域名被sinkhole。更便宜有效的另外一個方法就是和DNS廠商合作,比如Nominum的Vantio伺服器上TheatAvert服務可以實時推送DGA名單並禁止這些域名解析,使用了ThreatAvert的服務商就不會解析這些C&C域名,從而阻斷了惡意軟體和C&C域名的通訊。
從資料分析上可以看到DGA的另一個致命缺點就在於生成了很多備選域名。攻擊者為了更快速的發起攻擊,比如攻擊者的客戶要求付錢之後半小時內發起DDoS攻擊,那麼C&C的查詢頻率至少是每半小時,這就導致botnet對於C&C的查詢過於頻繁。雖然DGA本身看起來像是隱藏在眾多其他合法流量裡,但是現在已經有很多有針對DGA的各個特性演算法研究,比如鄙人的用機器學習識別隨機生成的C&C域名裡面利用到了DGA的隨機性等其它特性進行判別,安全研究人員可以用類似演算法篩選疑似DGA然後根據頻繁訪問這些DGA域名的IP地址等其他特徵通過圖論或其他統計方法判別C&C服務和感染的IP等。
0x05 高階變形DGA:如果DGA看起來不隨機
基於DGA偵測的多數辦法利用DGA的隨機性,所以現在高階的DGA一般都用字典組合,比如ObamaPresident123.info等等看起來遠不如cqaqofiwtfrbjegt.info可疑,攻擊者利用這種方法對付威脅感知和機器學習方法的偵測。最近的一個例子出現在Cisco的一篇blog裡面提到的DGA就是一個很小的硬編碼在程式碼裡字典檔案,通過單詞的組合生成C&C域名。這些字典組合的DGA看起來並不隨機,多數論文和blog裡針對隨機DGA機器學習的辦法就不管用了。
對於這種DGA暫時並沒有成熟有效的偵測方法,因為字典是未知的,可以是英語詞彙,可以是人名,可以是任何語言裡的單詞。常用的方法還是基於隨機DGA裡面用到過的n-gram方法,比如用已知的DGA的n-gram分佈判斷未知DGA,同時結合其它的特徵比如解析的IP等等,或者利用DGA頻繁查詢的特性用n-gram特徵作聚類。相關論文可以自行使用“Algorithmically Generated Domains”等關鍵詞搜尋。
0x06 多層混合C&C,跟著我左手右手一個慢動作:難度最高,不易被抓
在DGA部分提到了,DGA的致命缺點在於被動查詢,如果想要快速啟動攻擊就必須讓malware頻繁查詢C&C,導致C&C查詢資料上異常於正常的查詢流量。多層混合C&C可以有效避免這個問題,是個丟卒保帥的戰術。這種方法在亞洲區的malware裡面見到過很少幾次。
比如攻擊者設計一個兩層的C&C網路,Boss級的C&C使用主域名列表比如.com域名,Soldier雜兵級C&C用免費二級域名列表比如woshinidaye.3322.org,malware每天查詢一次Boss級C&C拉取當天雜兵C&C域名列表,然後以一分鐘一次的頻率查詢雜兵C&C域名,接受攻擊指令,示意圖如下:
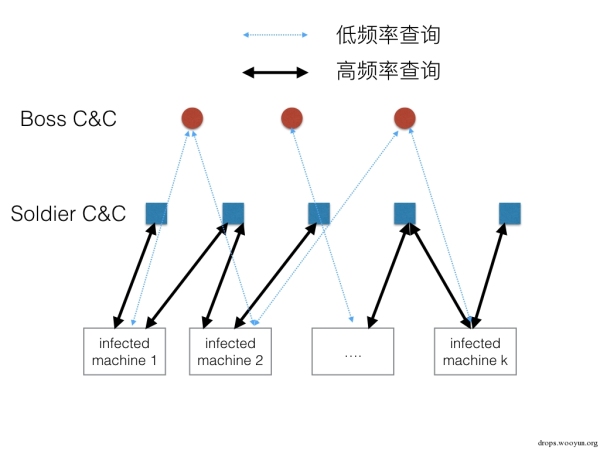
偵測和封禁這類高階混合C&C難點在於:
在資料裡,Boss級的C&C出現機率很低,可以不定時也可以一週一次,如果用一些早就註冊過的域名或者通過黑進他人伺服器利用無辜域名,Boss級的C&C很容易逃過異常檢測。
資料裡可以檢測到的是頻繁查詢的低階的雜兵C&C域名。如果把這些域名封禁,malware在下一輪更新雜兵C&C列表後會使這種封禁方法無效。雜兵域名就是主動跑上來送死的,反正二級域名不要錢。
更高階的做法是,如果Boss級的C&C列表裡的域名用完了,它可以通過這個兩層網路實時推送新的Boss級C&C列表。你看人家都不需要DGA這麼麻煩。
偵測和防禦方法需要一些資料和圖論的知識,具體參考偵測double flux的模型,同樣是兩層網路,不同點在於兩層節點都是域名節點,留作課後作業,這裡就不贅述了。針對實現上另一個特徵是,雜兵域名主要目的是來送死,他們的價格往往不高,比如免費二級域名或者免費的ccTLD或者gTLD字尾,利用這個特徵可以把第二層網路的尺度縮小,從而在圖資料庫的計算速度上有不小的提升。
0x07 利用Twitter Reddit等論壇:難度低,被抓看運氣
前面提到的辦法多是攻擊者自己架設伺服器,如果攻擊者的C&C域名被發現封禁了,這個botnet就被摧毀了。機智的攻擊者就想到了通過論壇發帖的辦法,比如在Twitter發一條在特定冷門話題下的包含C&C指令的tweet或者reddit上面找個十分冷門的subreddit發個包含控制指令的貼,這樣即使被運營商或者安全研究小組發現了,人家總不能把推特和reddit封了吧(我說的是美國政府沒有這個權利)。去年被抓住的名為Mac.BackDoor.iWorm的惡意軟體就是利用reddit做C&C控制伺服器,具體細節請參考http://news.drweb.com/show/?i=5976&lng=en&c=1 也有把C&C資訊隱藏在一篇看起來很正常的文章裡面防止被發現,比如MIT的這個把加密訊息隱藏在一篇論文裡的有趣的demo https://pdos.csail.mit.edu/archive/scigen/scipher.html 不過在實際工作裡暫時還沒有看到這麼高科技的C&C做法(你看我也不是教你這麼做啊)。
這種方法不適合國內的大環境,因為國外論壇發帖是不舉報不刪帖很容易悶聲發大財,但是水能載舟,亦可賽艇,國內由於發帖的身份控制嚴格,如果用這個方法很可能被眼尖的版主發現彙報給警察叔叔。而且新浪微博發C&C控制微博也不現實,微博為了防爬蟲要強制登陸而且微博那個API的麻煩程度你也是知道的。所以這個方法只是拓展視野,順便寫個段子。
這裡必須要插入一個段子了。一個真實的故事就是,我們抓到了一個做DDoS攻擊的botnet,我們的模型告訴我這些攻擊流量和twitter.com的訪問流量有強相關,經過細緻研究發現,這個bot可能用twitter的關鍵詞當隨機數種子生成攻擊DGA域名。但奇怪的是,同一個bot感染的IP列表裡面,中國區IP的隨機數種子似乎有初始化的問題,每次的種子都是一樣的。我們機智的抓住了這一點,把中國區當做對比組反向出了DGA演算法:因為一個特殊的原因中國區感染IP不能訪問twitter,如果認為中國區的DGA種子總是空字串,我們對比中國區的DGA和其他地區的DGA差不多可以猜出來它的DGA的方法,從而反向工程出來它們的DGA演算法。這裡需要感謝一下國家。
0x08 一些其它的高階技術
限於篇幅限制有一些現階段不太常用的C&C技術在這裡僅僅簡單描述一下,有興趣的觀眾朋友們可以自行搜尋。
利用P2P網路的C&C。如果一個僵屍網路裡面所有的感染IP互相成為對方的C&C控制伺服器,看起來很難摧毀所有的C&C。偵測重點在這個網路初始化的時候,就好比其它的BT下載必須從一個種子或者磁力鏈開始,當感染IP訪問初始化C&C的時候,它還是需要用上面說到的C&C方法,只是頻率很低。
IRC通訊.這是一個傳統歷史悠久的C&C控制方法。因為現在日常生活裡IRC已經被一些即時訊息服務比如微信等等取代,很少有普通群眾會用到IRC,年輕的安全人員可能會忽視IRC這個老辦法。辦法雖老,但是用處廣泛,好比T-800機器人,”Old, but not obsolete.”
你知道還可以手動C&C麼?我就見過在鄉鎮政府內網留了Windows Server 2003後門手工進去挨個啟動的,毫無PS痕跡,嗯。
0x09 結語
說了這麼多,主要目的是想介紹一下國際先進的惡意軟體C&C設計和偵測經驗,我們國內的malware不能總糾結於易語言啊VC6.0啊之類的我國特色,也需要向國際靠攏。同樣的,我國的安全研究人員也需要國際先進經驗,走在攻擊者前面。C&C的設計和防禦一直都是貓鼠遊戲,不定期會出現一些大家都沒想到的很機智的辦法。在偵測C&C服務的過程裡,資料科學和機器學習是很重要的工具,C&C的偵測現在越來越多的用到資料方法,在文中大家也看到了,攻擊者已經設計出來一些對抗資料分析和機器學習的更高階C&C設計方法,足以看出資料科學在安全領域的重要作用,連攻擊者都體會到了。很多C&C服務看似隨機,分佈也廣泛,但是在統計分析上會顯示出一些特定規律從而讓安全人員發現。沒有人可以騙的過統計規律,不是嗎?