
你與Kafka監控進階,只差一個“視角”的距離
Kakfa監控實踐
監控工具選擇
實際使用中對比了多種Kafka監控工具,最終選擇如下幾種工具:
Kafka Monitor:這是LinkedIn開源的Kafka核心功能監控工具,並且提供了視覺化介面。它可以模擬資料生產並消費,基本上覆蓋了黑盒監控大部分指標,包括叢集核心功能、資料讀寫、讀寫延遲等。使用者使用成本也相對簡單,只需對接告警系統即可。
如果你的產品用到了Kafka,強烈推薦使用Kafka Monitor。
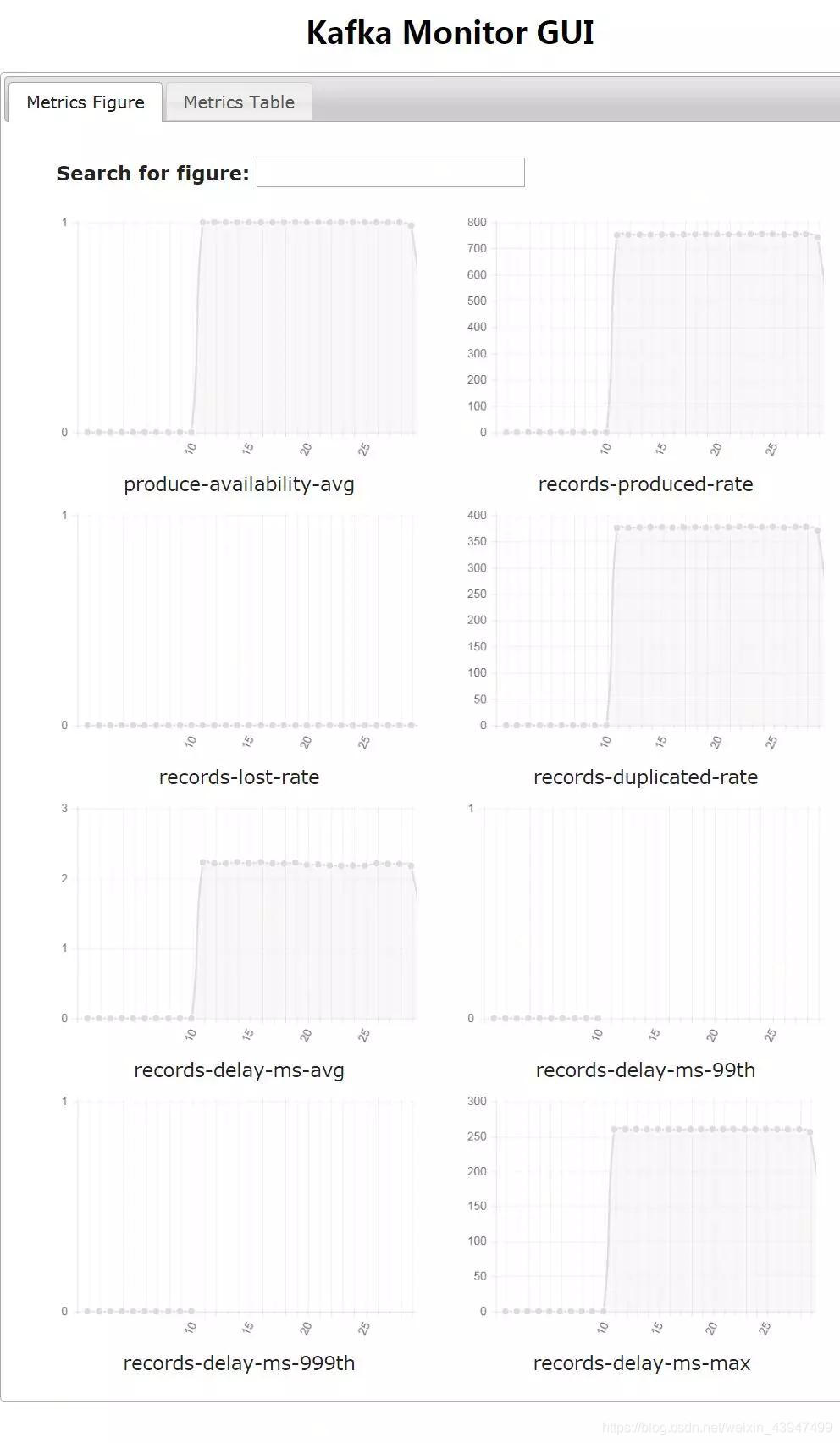
▲圖一 Kafka Monitor視覺化介面
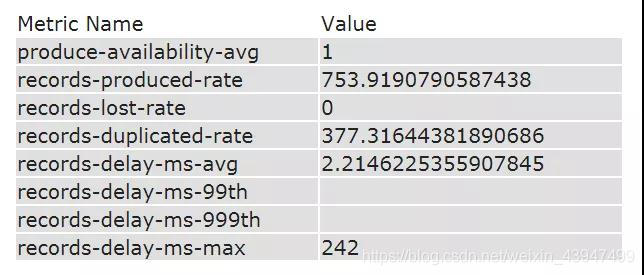
▲表一 Kafka Monitor監控指標樣例
Kafka Manager:
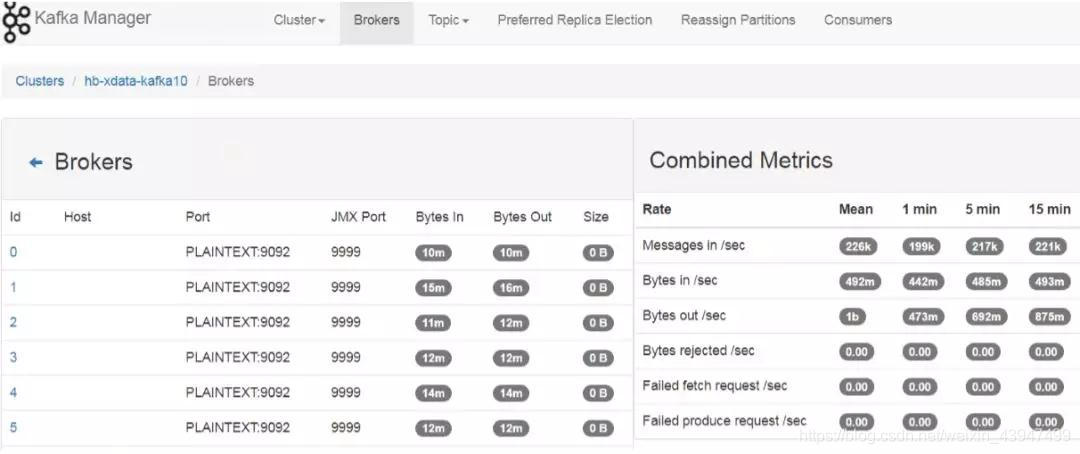
▲圖二 Kafka Manager介面
Jmxtrans+Influxdb:Jmxtrans通過Jmx埠可以採集Kafka多種維度監控資料,預儲存在Influxdb。Jmxtrans也是非常優秀的工具,通過它採集的資料項很多,因此採集項篩選是一個難題,篩選後的資料不僅可以作為儀表盤展現使用,也可以為後續產品層面的監控做準備。
叢集層面的空間使用率相關資料,需要自研工具來完成,附件中提供了參考指令碼。
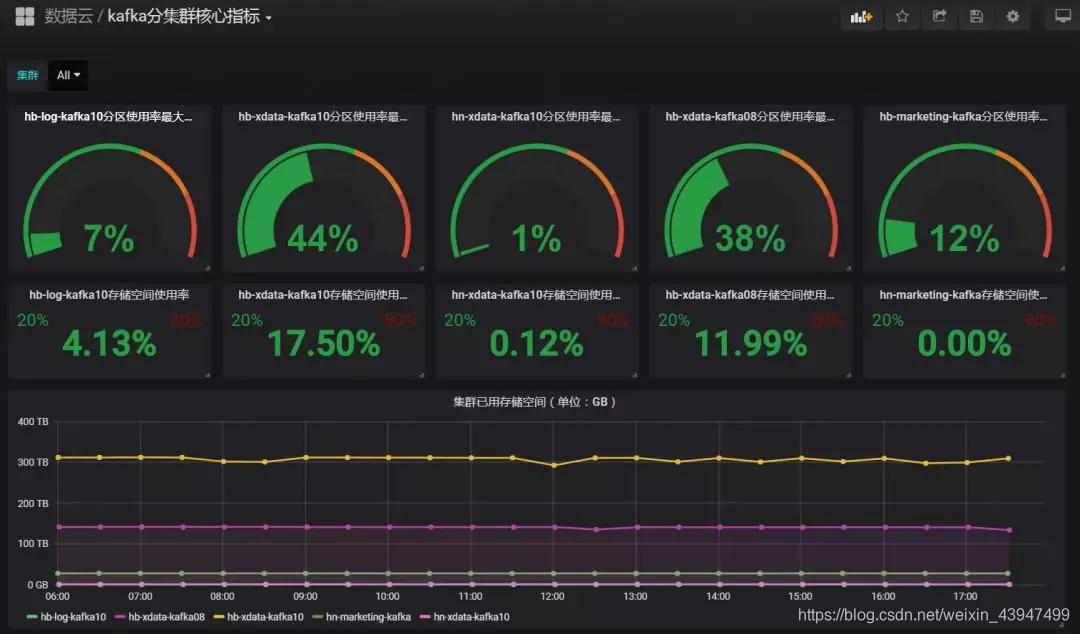
▲圖三 Kafka運維儀表盤部分指標
監控指標
確定黑盒監控指標
黑盒監控指標不符合預期說明叢集不能正常工作或出現異常,它更多是一種現象。常用的黑盒監控指標有:叢集核心功能、資料讀寫、讀寫延遲等。
確定白盒監控指標
對比其他儲存元件,大部分監控指標是通用的,或者能找到類似的監控指標,白盒監控是黑盒監控的補充,服務於故障定位,從叢集容量、流量、延遲、錯誤四個方面梳理。

▲表二 梳理Kafka監控指標分類
部分採集指標
-
核心功能
採集項:produce-availability-avg
說明:單獨建立監控主題,對其進行功能監控,覆蓋訊息生成、寫入、消費整個生命週期
資料來源:Kafka Monitor
-
主題操作
採集項:topic-function
說明:覆蓋主題的整個生命週期(創建出的主題要清理,否則主題過多,在例項恢復時會很慢)
資料來源:自研
-
延遲
採集項:records-delay-ms-avg
說明:生產、消費延遲時間
來源:Kafka Monitor
採集項:records-delay-ms-max
說明:最大延遲時間
來源:Kafka Monitor
-
流量
採集項:kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec,topic=*
說明:某一主題每秒寫入
來源:Jmxtrans
採集項:kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec,topic=*
說明:某一主題每秒讀出
資料來源:Jmxtrans
採集項:kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec,topic=*
說明:某一主題每秒寫入訊息數
資料來源:Jmxtrans
採集項:kafka.network:type=RequestMetrics,name=RequestsPerSec,request=Produce
說明:每秒Produce的請求次數
資料來源:Jmxtrans
-
容量
採集項:kafka.log:type=Log,name=Size,topic=*,partition=*
說明:分割槽大小
資料來源:Jmxtrans
採集項:topicSizeALL
說明:某一主題大小(需要基於各Broker資料進行計算)
資料來源:自研
-
錯誤
採集項:kafka.controller:name=OfflinePartitionsCount,type=KafkaController
說明:沒有Leader的分割槽數
資料來源:Jmxtrans
採集項:kafka.controller:name=ActiveControllerCount,type=KafkaController
說明:是否為活躍控制器(整個叢集只能有1個例項為1)
資料來源:Jmxtrans
採集項:kafka.server:type=ReplicaFetcherManager,name=MaxLag,clientId=Replica
說明:副本落後主分片的最大訊息數量
資料來源:Jmxtrans
採集項:kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions
說明:正在做同步的分割槽數量
資料來源:Jmxtrans
採集項:kafka.server:type=ReplicaManager,name=LeaderCount
說明:Leader的Replica的數量
資料來源:Jmxtrans
採集項:kafka.server:clientId=*,name=ConsumerLag,partition=*,topic=*,type=FetcherLagMetrics
說明:消費延遲量(Lag)
資料來源:Jmxtrans
採集項:kafka.log:type=Log,name=LogEndOffset,topic=*,partition=*
說明:每個分割槽最後的Offset
資料來源:Jmxtrans
總結
Kafka監控經驗
-
通過Jmxtrans獲取到採集項之後,如果期望獲取到全域性資料,則必須對所有Broker上的資料進行彙總計算,附件中提供了部分Jmxtrans採集項計算指令碼。
-
在分割槽大小告警閾值設定上,主題的某個分割槽不要過大(我們場景,最大為800G),否則,在遷移分割槽時會很慢。
-
Kafka在不同資料目錄分配分割槽時,會按照分割槽數來均衡。因此,實際部署中,不同例項最好做到:資料目錄大小、資料目錄數一致。否則,在叢集達到上千個主題後,你的分割槽遷移工作量會很大。
-
預採集資料。監控並不能一蹴而就,隨著產品或叢集變化,需要迭代。因此,需要預採集那些當前看似沒有價值的資料,當需要時,所存即所用。另外,從歷史故障中進行總結,也可以發掘一些待採集的監控資料。
-
針對Kafka,一個可行的監控資料儲存、展現工具集:Jmxtrans+Influxdb+Grafana。Grafana既可以充當巡檢儀表盤,也可充當監控資料檢視工具。
-
在Kafka採集項獲取或分析資料時,Jmxcmd也是不錯的小工具。
Kafka實際產品監控
資料匯流排、Kafka訊息佇列等公有云產品,一般是基於Kafka來實現。按照上述監控方法完善Kafka叢集監控,可以做到大部分Kafka問題都能及時發現。但對使用者來說,產品本身的監控才更為重要。
產品SLO指標
按照Google SRE提出的SLO(Service Level Objectives服務等級目標)和“錯誤預算”理論與實踐,需要從使用者視角對Kafka相關產品進行分析並監控。
以“資料匯流排”產品為例,這些產品一般提供給使用者的核心功能主要有:
-
資料接入
-
資料歸檔
在我們實際產品中,總結了歷史故障,確立了當前產品的SLO指標,並對其進行監控。部分SLO指標:
-
流資料匯流排生命週期健康>99.9%
-
重點使用者主題健康>99.9%
-
歸檔延遲資料<20分鐘

▲圖四 資料匯流排SLO及錯誤預算部分指標預覽
滿足多租戶
如果只關注整體SLO指標,那麼有些租戶可能會遺漏,對於這些租戶的核心功能也需要監控,此時,我們需要藉助已有監控工具預採集的資料,這些資料包含了所有主題的相關資料。這樣,當我們需要知道使用者的主題時,就能快速搜尋到對應主題的流量、延遲等密切指標,及時反饋到租戶。
可以為租戶搜尋到的部分指標:
-
kafka.cluster:name=UnderReplicated,partition=*,type=Partition
-
kafka.log:name=LogEndOffset,partition=*,type=Log
-
kafka.log:name=LogStartOffset,partition=*,type=Log
-
kafka.log:name=Size,partition=*,type=Log
-
kafka.server:name=BytesInPerSec,type=BrokerTopicMetrics
-
kafka.server:name=BytesOutPerSec,type=BrokerTopicMetrics
-
kafka.server:name=MessagesInPerSec,topic=*,type=BrokerTopicMetrics
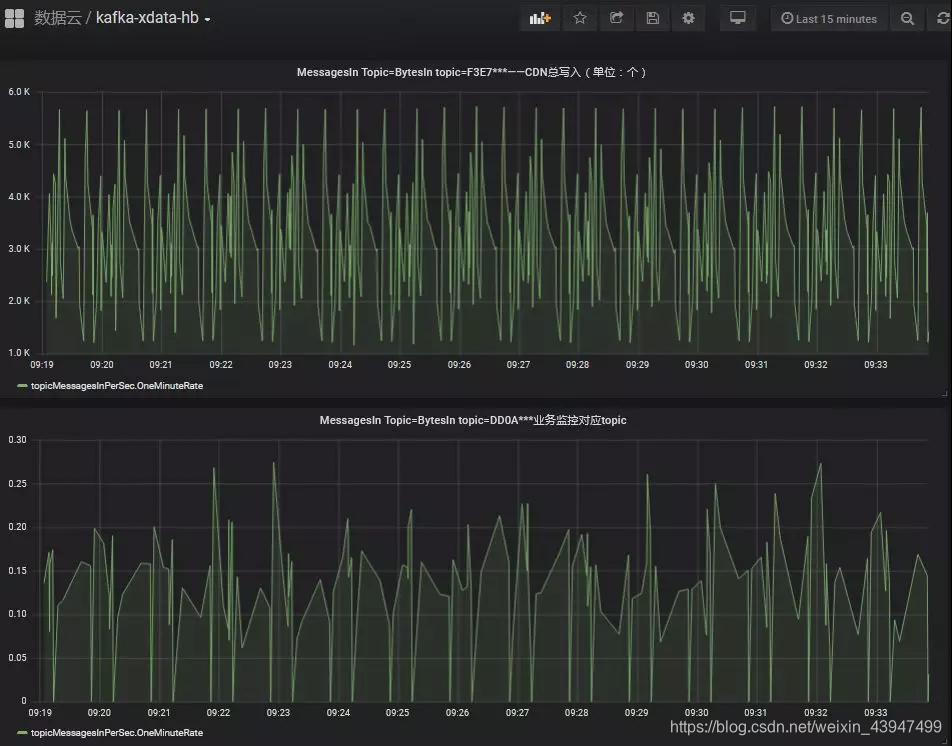
▲圖五 搜尋某租戶部分SLO指標結果
附:
Kafka監控相關指令碼
https://github.com/cloud-op/monitor/tree/master/kafka