
系統學習-協程理解
目錄
在面對非同步IO頻繁的業務需求的時,可以使用回撥的機制。在利用回撥的過程中,如果利用狀態機則會發生回撥金字塔(callback hell),主要表現為:1.程式碼複用率極低。2.邏輯複雜。此時利用協同程式可以很好的解決這個問題。
CPU (CentralProcessingUnit)
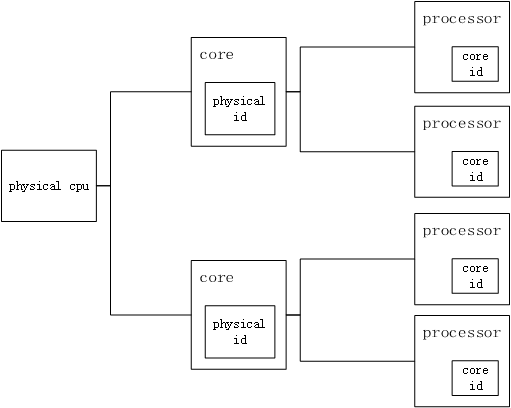
計算機的核心是CPU,所有的計算任務都是由它完成。CPU概念包括:
物理CPU
物理CPU就是插在主機上的真實的CPU硬體,在Linux下可以數不同的physical id 來確認主機的物理CPU個數。
核心數
物理CPU下一層概念就是核心數,我們常常會聽說多核處理器,其中的核指的就是核心數。在Linux下可以通過cores來確認主機的物理CPU的核心數。
邏輯CPU
邏輯CPU跟超執行緒技術有聯絡,假如物理CPU不支援超執行緒的,那麼邏輯CPU的數量等於核心數的數量;如果物理CPU支援超執行緒,那麼邏輯CPU的數目是核心數數目的兩倍。在Linux下可以通過 processors 的數目來確認邏輯CPU的數量。
層級如下圖所示:
程序與執行緒
**程序是CPU資源分配的最小單位,執行緒是CPU排程的最小單位。**程序包含執行緒,常見的模型有:
1.單程序單執行緒模型
程序與執行緒的區別在於:程序掌管著資源,執行緒是程序的一部分,CPU執行排程的是執行緒。
2.單程序多執行緒模型
多個執行緒共享全域性資源,但不包括執行緒自己的棧空間。
3.多程序單執行緒模型
單個應用可以通過fork拷貝出多個程序,程序的資源會進行復制。注意:fd同樣會複製,不建議多個程序共用同一個fd,會出現資料亂序的情況。
4.多程序單執行緒模型
涉及多執行緒時,鎖是個必須掌握的知識點,否則同時對共享資源進行處理可能導致覆蓋寫問題。
網路程式設計中5種I/O模型
在Unix(linux)平臺下有5中I/O模型:
同步I/O模型
堵塞I/O模型(blocking I/O)
非堵塞I/O模型(un-blocking I/O)
I/O多路複用模型(select, poll, epoll)(較常見)
訊號驅動I/O模型(SIGIO)
非同步I/O模型
同步與非同步的區別
同步:指關於這個I/O中的一系列動作都需要自己來完成,無論你是原地等待事件的發生(阻塞)還是當某個事件已經準備好的時候你去完成後面的的動作(非阻塞)都屬於同步。
非同步:它是指是呼叫另一個執行者去完成,當執行者發現要處理的事件後呼叫你,你再完成這件事情,執行的過程和你的動作是不牽扯的。
因此,前四種是同步I/O模型,只有第五種是非同步的。
I/O操作一般分為兩個階段:
- 等待資料達到核心快取區
- 將資料從核心拷貝到使用者程序
阻塞型I/O
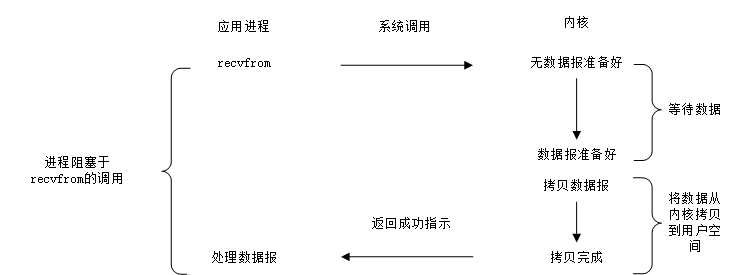
通常把阻塞的檔案描述符(file descriptor,fd)稱之為阻塞I/O。預設條件下,建立的socket fd是阻塞的,針對阻塞I/O呼叫系統介面,可能因為等待的事件沒有到達而被系統掛起,直到等待的事件觸發呼叫接口才返回,例如,tcp socket的recvfrom呼叫會阻塞至連線有資料返回,如上圖所示。另外socket 的系統API ,如,accept、send、connect等都可能被阻塞。
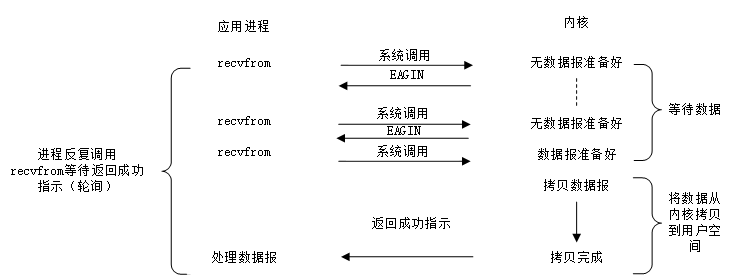
非阻塞型I/O
一種輪詢的機制
把非阻塞的檔案描述符稱為非阻塞I/O。可以通過設定SOCK_NONBLOCK標記建立非阻塞的socket fd,或者使用fcntl將fd設定為非阻塞。
對非阻塞fd呼叫系統介面時,不需要等待事件發生而立即返回,事件沒有發生,介面返回-1,此時需要通過errno的值來區分是否出錯,有過網路程式設計的經驗的應該都瞭解這點。不同的介面,立即返回時的errno值不盡相同,如,recv、send、accept errno通常被設定為EAGIN 或者EWOULDBLOCK,connect 則為EINPRO- GRESS 。
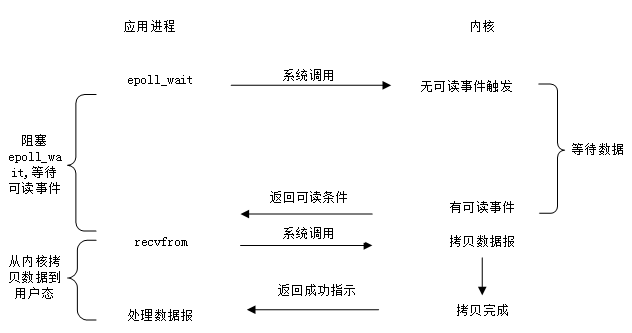
I/O多路複用
最常用的I/O事件通知機制就是I/O複用(I/O multiplexing)。Linux 環境中使用select/poll/epoll 實現I/O複用,I/O複用介面本身是阻塞的,在應用程式中通過I/O複用介面向核心註冊fd所關注的事件,當關注事件觸發時,通過I/O複用介面的返回值通知到應用程式,如圖3所示,以recv為例。I/O複用介面可以同時監聽多個I/O事件以提高事件處理效率。
好處:其實這就是一個回撥實現的機制。在這個過程中,只需要兩個執行緒就可以完成多個連線請求。一個為業務執行緒,一個為epoll模型監聽執行緒。這樣的話,就可以利用一個業務執行緒進行大量的訪問請求處理。而不必像PHP等實現機制,每一個請求都分配一個執行緒,之後阻塞等待。
回撥機制
在這種典型的回撥機制的實現過程中,通過epoll模型返回的結果即狀態機的條件,以及結合上下文即狀態機的現態,可以觸發動作。即:條件+現態->動作(狀態機是一種switch-case的結構,邏輯是非順序的,類似於一種表格的結構—詳見深入淺出理解有限狀態機),因為狀態機的邏輯非順序化,所以將其邏輯順序化的過程,會出現callback hell的問題。如下圖所示:
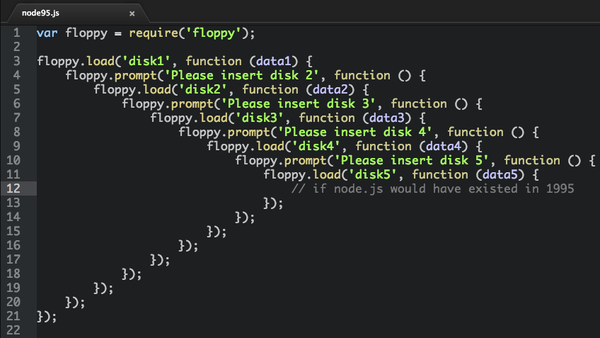
解決這樣的問題協程是一種有效的手段,即:協程可以處理大量的非同步I/O操作的需求業務。
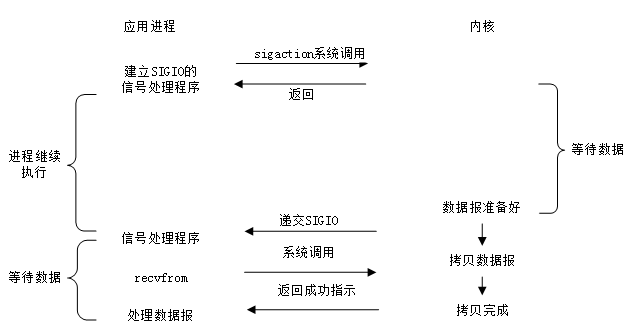
訊號驅動I/O
除了I/O複用方式通知I/O事件,還可以通過SIGIO訊號來通知I/O事件,如上圖所示。兩者不同的是,在等待資料達到期間,I/O複用是會阻塞應用程式,而SIGIO方式是不會阻塞應用程式的。
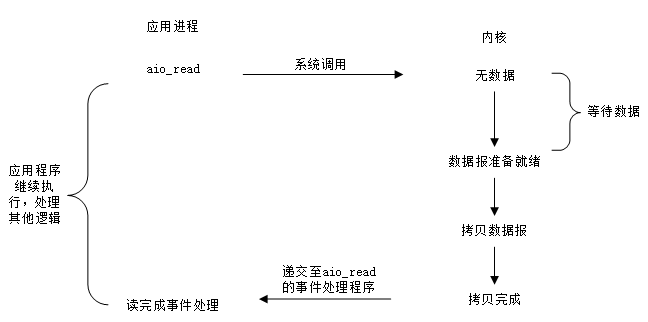
非同步I/O
POSIX規範定義了一組非同步操作I/O的介面,不用關心fd 是阻塞還是非阻塞,非同步I/O是由核心接管應用層對fd的I/O操作。非同步I/O嚮應用層通知I/O操作完成的事件,這與前面介紹的I/O 複用模型、SIGIO模型通知事件就緒的方式明顯不同。以aio_read 實現非同步讀取IO資料為例,如圖5所示,在等待I/O操作完成期間,不會阻塞應用程式。
目前常見的服務端模型(多程序結合I/O多路複用)
虛擬碼:
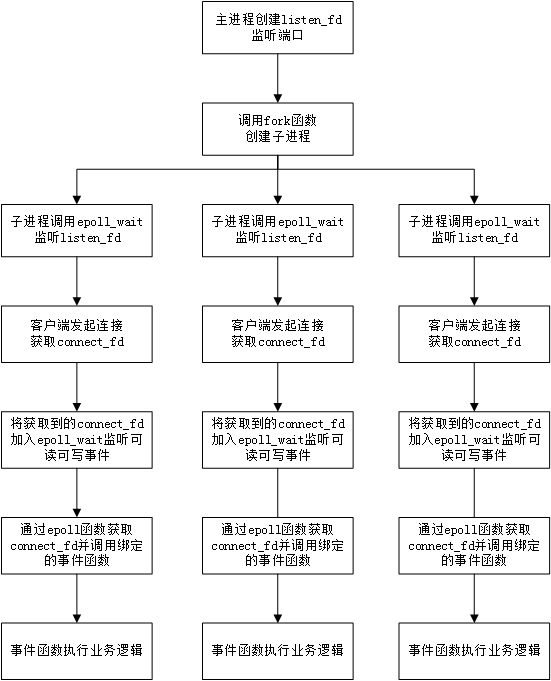
void dispatch(...){
將connect_fd加入epoll佇列,等待可讀(可寫)事件
}
void run(...){
執行業務邏輯(read或者write該fd)
//其他業務邏輯(如curl)
}
int main()
{
建立listen_fd監聽埠
fork建立子程序
if(當前程序為父程序){
/*************父程序***************/
管理子程序
}else{
/*************子程序***************/
子程序建立epoll佇列
將dispatch事件繫結到listen_fd的可讀事件上
使用epoll函式監聽listen_fd
while(1){
//第一次觸發epoll函式
出現listen_fd可讀(可寫)事件,觸發dispatch事件
epoll佇列中有listen_fd和每個客戶端的connect_fd
//第N次(N!=1)
出現listen_fd或者connect_fd的可讀(可寫)事件,觸發對應的dispatch事件或者run事件
}
}
}
從伺服器端的程式碼邏輯可以知道,epoll是可以同時監聽多個fd的,並且在有對應的事件時才喚醒對應的事件函式,這是通常說的非同步呼叫。
但是,這裡有個問題,如果在run函式中業務邏輯需要建立tcp連線(如curl)請求其他服務介面(建立fd),此時的fd因為沒有使用epoll,就會出現阻塞。
那我們設想一下,如果在run函式中寫epoll監聽該fd,那如果這個tcp連線請求的後續事件依舊需要建立tcp請求呢,這個程式碼該怎麼編寫下去呢,這就是常說的一種情況,回撥地獄。
那如何優雅解決這個問題呢?
設想一下,如果我們不需要去寫epoll監聽,直接對read/write函式進行hook,預設所有IO操作行為會被直接加入epoll佇列,這樣就不會有回撥地獄。因此,協程誕生了!
協程
協程是一種程式元件,是由子例程(過程、函式、例程、方法、子程式)的概念泛化而來的,子例程只有一個入口點且只返回一次,而協程允許多個入口點,可以在指定位置掛起和恢復執行。協程是一種“偽多執行緒”,一個執行緒中可以包含多個協程,但同一時刻只能有一個協程在執行。
協程是一種可以暫停執行過程的函式,它可以中斷當前的執行過程直到下一個Yield指令達成。在實現上,大多數都是以函式來作為一個協程,因此這裡列出此簡化的定義方便理解。
例如:實現一個0到9的迴圈輸出。
int function(void) {
static int i, state = 0;
switch (state) {
case 0: /* start of function */
for (i = 0; i < 10; i++) {
state = __LINE__ + 2; /* so we will come back to "case __LINE__" */
return i;
case __LINE__:; /* resume control straight after the return */
}
}
}
用static變數儲存上下文,再用switch進行程式碼行的跳轉,就可以實現一個簡單的協程。
協程的運用
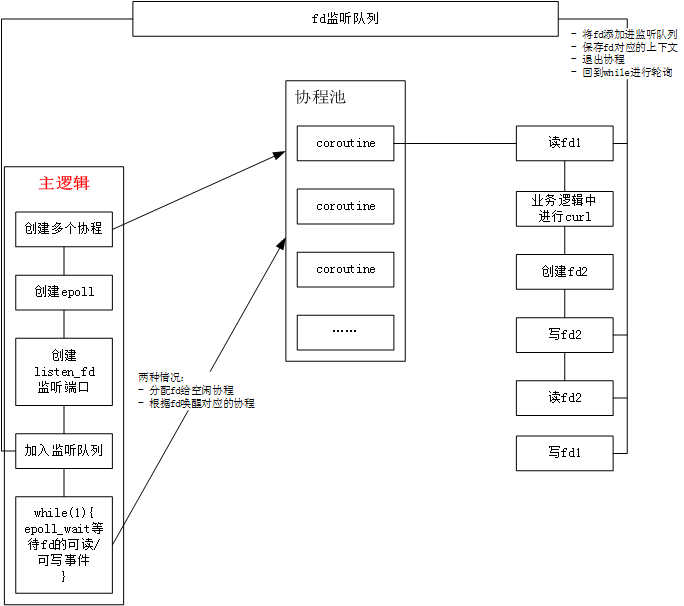
總結
協程主要適合於一些IO比較頻繁的系統,在這樣的系統中,使用協程跟多執行緒的優缺點比較如下:
- 單執行緒非同步IO: 優點是效能高,程式碼執行是順序的,不需要關心鎖,競爭等情況;缺點是需要自己處理非同步I/O、epoll等,無法便捷地做到hook所有fd操作;
- 協程: 比單執行緒非同步I/O容易程式設計,程式碼更好寫,協程裡面是順序程式設計的,但協程之間是獨立棧,共享堆記憶體,單執行緒執行環境,在一個CPU上執行。協程切換代價比執行緒少多了,只需要十幾條彙編指令切換暫存器。每秒據說能達到上百萬次切換。
- 多執行緒同步I/O: 程式碼相對也好寫,跟協程一樣獨立棧,共享堆記憶體。 需要處理資源競爭問題,而且執行緒切換代價特別大,linux裡面沒有原生的執行緒,是用程序實現的。
- 多程序:程式碼相對容易編寫,但需要解決共享資料的問題。