
Digging into Data Science Tools: Docker
Digging into Data Science Tools: Docker
Docker is a tool for creating and managing “containers” which are like little virtual machines where you can run your code. A Docker container is like a little Linux OS, preinstalled with everything you need to run your web app, machine learning model, script, or any other code you write.
Docker containers are like a really lightweight version of virtual machines. They use way less computer resources than a virtual machine, and can spin up in seconds rather than minutes. (The reason for this performance improvement is Docker containers share the kernel of the host machine, whereas virtual machines run a separate OS with a separate kernel for every virtual machine.)
Aly Sivji provides a great comparison of Docker containers to shipping containers. Shipping containers improved efficiency of logistics by standardizing the design: they all operate the same way and we have standardized infrastructure for dealing with them, and as a result you can ship them regardless of transportation type (truck, train, or boat) and logistics company (all are aware of shipping containers and mold to their standards). In a similar way, Docker provides a standardized software container which you can pass into different environments and be confident they’ll run as you expect.
Brief Overview of How Docker Works
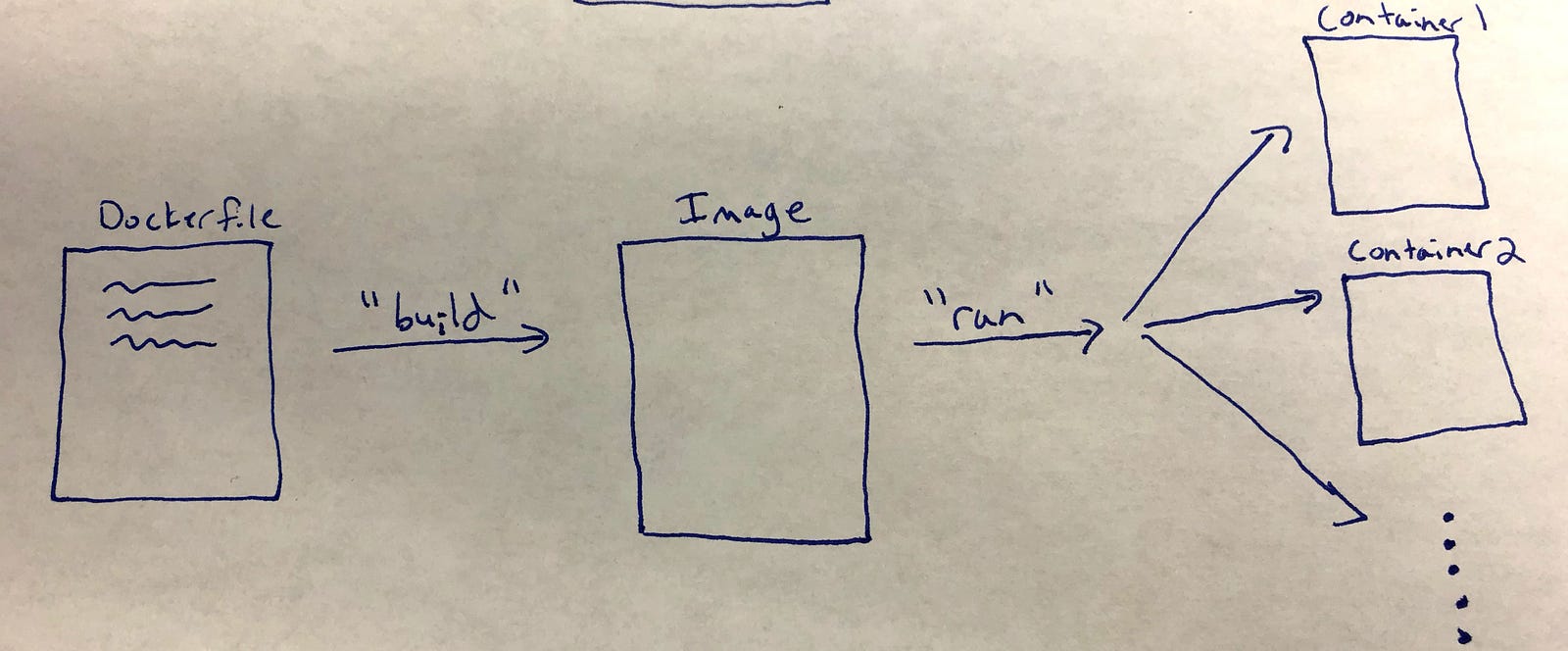
To give you a really high-level overview of how Docker works, first let’s define three big Docker-related terms — “Dockerfile”, “Image”, and “Container”:
- Dockerfile: A text file you write to build the Docker “image” that you need (see definition of image below). You can think of the Dockerfile like a wrapper around the Linux command line: the commands that you would use to set up a Linux system on the command line have equivalents which you can place in a docker file. “Building” the Dockerfile produces an image that represents a Linux machine that’s in the exact state that you need. You can learn all about the ins-and-outs of the syntax and commands at the Dockerfile reference page. To get an idea of what Dockerfiles look like, here is a Dockerfile you would use to create an image that has the Ubuntu 15.04 Linux distribution, copy all the files from your application to ./app in the image, run the make command on /app within your image’s Linux command line, and then finally run the python file defined in /app/app.py:
FROM ubuntu:15.04 COPY . /app RUN make /app CMD python /app/app.py
- Image: A “snapshot” of the environment that you want the containers to run. The images include all you need to run your code, such as code dependencies (e.g. python venv or conda environment) and system dependencies (e.g. server, database). You “build” images from Dockerfiles which define everything the image should include. You then use these images to create containers.
- Container: An “instance” of the image, similar to how objects are instances of classes in object oriented programming. You create (or “run” using Docker language) containers from images. You can think of containers as a running the “virtual machine” defined by your image.
To sum up these three main concepts: you write a Dockerfile to “build” the image that you need, which represents the snapshot of your system at a point in time. From this image, you can then “run” one or more containers with that image.

Here are a few other useful terms to know:
- Volume: “Shared folders” that lets a docker container see the folder on your host machine (very useful for development, so your container is automatically updated with your code changes). Volumes also allow one docker container to see data in another container. Volumes can be “persistent” (the volume continues to exist after the container is stopped) or “ephemeral” (the volume disappears as soon as the container is stopped).
- Container Orchestration: When you first start using Docker, you’ll probably just spin up one container at a time. However, you’ll soon find that you want to have multiple containers, each running using a different image with different configurations. For example, a common use of Docker is deployment of applications as “microservices”, where each Docker container represents an individual microservice that interacts with your other microservices to deliver your application. Since it can get very unwieldy to manage multiple containers manually, there are “container orchestration” tools that automate tasks such as starting up all your containers, automatically restarting failing containers, connecting containers together so they can see each other, and distributing containers across multiple computers. Examples of tools in this space include docker-compose and Kubernetes.
- Docker Daemon / Docker Client: The Docker Daemon must be running on the machine where you want to run containers (could be on your local or remote machine). The Docker Client is front-end command line interface to interact with Docker, connect to the Docker Daemon, and tell it what to do. It’s through the Docker client where you run commands to build images from Dockerfiles, create containers from images, and do other Docker-related tasks.
Why is Docker useful to Data Scientists?
You might be thinking “Oh god, another tool for me to learn on top of the millions of other things I have to keep on top of? Is it worth my time to learn it? Will this technology even exist in a couple years?”
I think the answer is, yes, this is definitely a worthwhile tool for you to add to your data science toolbox.
To help illustrate, here is a list of reasons for using Docker as a data scientist, many of which are discussed in Michael D’agostino’s “Docker for Data Scientists” talk as well as this Lynda course from Arthur Ulfeldt:
- Creating 100% Reproducible Data Analysis: Reproducibility is increasingly recognized as critical for both methodological and legal reasons. When you’re doing analysis, you want others to be able to verify your work. Jupyter notebooks and Python virtual environments are a big help, but you’re out of luck if you have critical system dependencies. Docker ensures you’re running your code in exactly the same way every time, with the same OS and system libraries.
- Documentation: As mentioned above, the basis for building docker containers is a “Dockerfile”, which is a line by line description of all the stuff that needs to exist in your image / container. Reading this file gives you (and anyone else that needs to deploy your code) a great understanding about what exactly is running on the container.
- Isolation: Using Docker helps ensure that your tools don’t conflict with one another. By running them in separate containers, you’ll know that you can run Python 2, Python 3, and R and these pieces of software will not interfere with each other.
- Gain DevOps powers: in the words of Michaelangelo D’Agostino, “Docker Democratizes DevOps”, since it opens up opportunities to people that used to only available to systems / DevOps experts:
- Docker allows you to more easily “sidestep” DevOps / system administration if you aren’t interested, since someone can create a container for you and all you have to do it run it. Similarly, if you like working with Docker, you can create a container less technically savvy coworkers that lets them run things easily in the environment they need.
- Docker provides the ability to build docker containers starting from existing containers. You can find many of these on DockerHub, which holds thousands of pre-built Dockerfiles and images. So if you’re running a well-known application (or even obscure applications), there is often a Dockerfile already available that can give you a tremendous running start to deploy your project. This includes “official” Docker repositories for many tools, such as ubuntu, postgres, nginx, wordpress, python, and much more.
- Using Docker helps you work with your IT / DevOps colleagues, since you can do your Data Science work in a container, and simply pass it over to DevOps as a black box that they can run without having to know everything about your model.
Here are a few examples of applications relevant to data science where you might try out with Docker:
- Create an ultra-portable, custom development workflow: Build a personal development environment in a Dockerfile, so you can access your workflow immediately on any machine with Docker installed. Simply load up the image wherever you are, on whatever machine you’re on, and your entire work environment is there: everything you need to do your job, and how you want to do your job.
- Create development, testing, staging, and production environments: Rest assured that your code will run as you expect and become able to create staging environments identical to production so you know when you push to production, you’re going to be OK.
- Reproduce your Jupyter notebook on any machine: Create a container that runs everything you need for your Jupyter Notebook data analysis, so you can pass it along to other researchers / colleagues and know that it will run on their machine. As great as Jupyter Notebooks are for doing analysis, they tend to suffer from the “it works on my machine” issue, and Docker can solve this issue.
For more inspiration, check out Civis Analytics Michaelangelo D’Agostino describe the Docker containers they use (start at the 18:08 mark). This includes containers specialized for survey processing, R shiny apps and other dashboards, Bayesian time series modeling and poll aggregation, as well as general purpose R/Python packages that have all the common packages needed for staff.
Further Resources
If you’re serious about starting to use Docker, I highly recommend the Lynda Course Learning Docker by Arthur Ulfeldt as a starting point. It’s well-explained and concise (only about 3 hours of video in total).
Here are a few other useful resources you might want to check out: