
Introducing Texar: A Modularized, Versatile, and Extensible Toolkit for Text Generation and Beyond

Introducing Texar: A Modularized, Versatile, and Extensible Toolkit for Text Generation and Beyond
Crossposted on the Petuum blog.
We are excited to introduce Texar, an open-source, general-purpose toolkit that supports a broad set of machine learning applications with a focus on text generation tasks. Texar is particularly suitable for researchers and practitioners of fast model prototyping and experimentation.
Text Generation at a Glance
Text generation spans a broad set of natural language processing (NLP) tasks that aim to generate natural language from input data or machine representations. Such tasks include machine translation, dialog systems, text summarization, article writing, text paraphrasing and manipulation, image captioning, and more. While this field has undergone rapid progress in both academic and industry settings, in part due to the integration of modern deep learning approaches, considerable research efforts are still needed in order to improve techniques and enable real-world applications.
Text generation tasks have many common properties and share two central goals:
- Generating human-like, grammatical, and readable text.
- Generating text that contains all relevant information inferred from inputs. For example, in machine translation, the translated sentence that is generated must express the same meaning as the source sentence.
To this end, a few key techniques are increasingly widely-used, such as neural encoder- decoders, attentions, memory networks, adversarial methods, reinforcement learning, and structured supervision, as well as optimization, data pre-processing and result post-processing procedures, evaluations, and etc. These techniques are often combined together in various ways to tackle different problems (Figure 1).

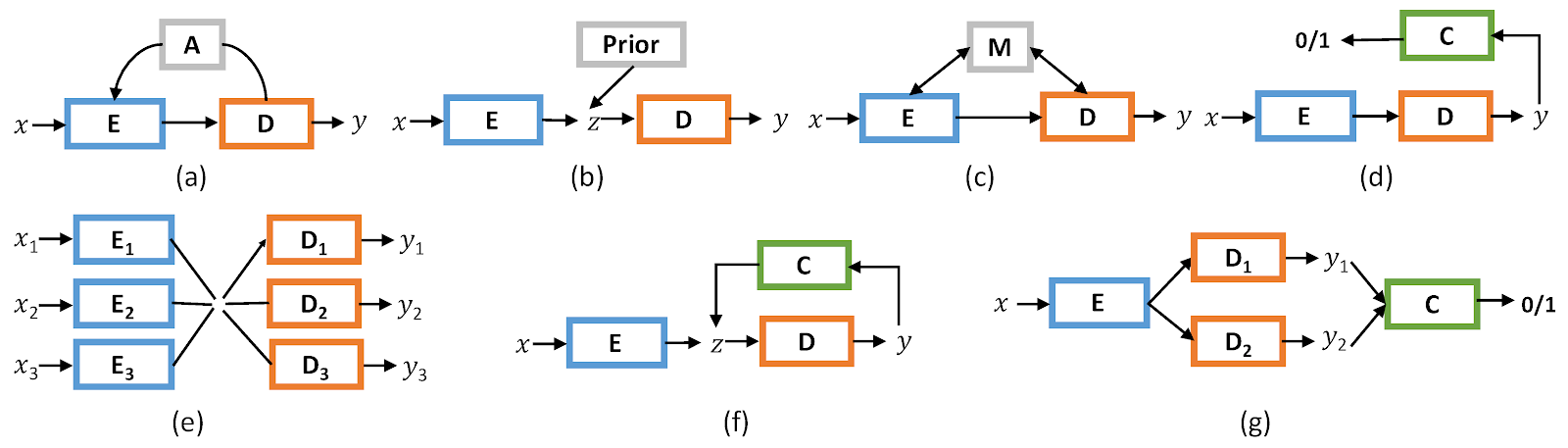
It is therefore highly desirable to have an open-source platform that unifies the development of these diverse yet closely-related text generation applications, backed with clean and consistent implementations of the core algorithms. Such a unified platform would enable reuse of common components and functionalities; standardize design, implementation, and experimentation; foster reproducible research; and, importantly, encourage technique sharing among different text generation tasks so that an algorithmic advance developed for a specific task can quickly be evaluated and generalized to many other tasks.
Introducing Texar
To that end, we have developed Texar, an open-source toolkit focused on text generation tasks, using the TensorFlow language. Texar is modular, versatile, and extensible. It extracts common patterns underlying the diverse tasks and methodologies within text generation and creates a library of highly reusable modules and functionalities.

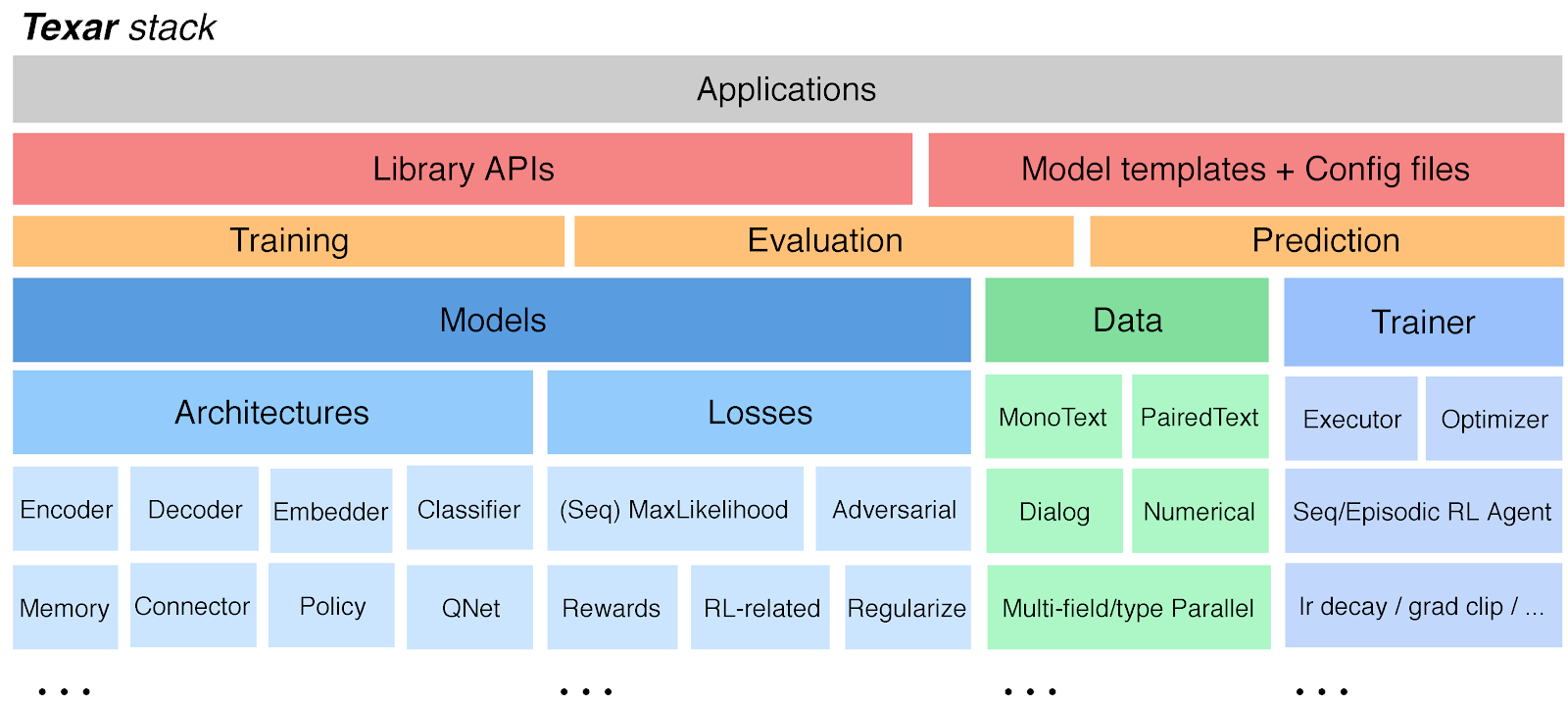
Versatility
Texar contains a wide range of modules and functionalities for composing arbitrary model architectures and implementing various learning algorithms such as maximum likelihood learning, reinforcement learning, adversarial learning, probabilistic modeling, and so forth (Figure 2).
Modularity
Texar decomposes diverse complex machine learning models/algorithms into highly-reusable model architecture, loss, and learning process modules, among others.
Users can easily construct their own models at a high conceptual level by assembling Texar’s modules like building blocks. Texar makes plugging-in and swapping-out modules simple — for example, switching between maximum likelihood learning and reinforcement learning only involves changing a few lines of code.
Extensibility
Texar can be effortlessly integrated with any user-customized, external modules, and is fully compatible with the TensorFlow open source community, including TensorFlow-native interfaces, features, and resources.
Usability
With Texar, users can customize models with templates/examples and simple Python/YAML configuration files, or program from Texar’s Python Library APIs for maximal customizability.
Texar provides convenient automatic variable reuse (no need to worry about complicated TensorFlow variable scopes), simple function-like calls to perform module logic, and rich configuration options with sensible default values for every module.
Texar emphasizes well-structured, highly-readable code with uniform design patterns and consistent styles, along with clean documentation and rich tutorial examples.
Texar is currently supporting several research and engineering projects at Petuum, Inc. We hope the toolkit can also empower the community to accelerate technique development in text generation and beyond. We also invite researchers and practitioners to join and further enrich the toolkit so that, together, we can advance text generation research and applications.
Please check out the following resources to learn more about Texar: