
NLP Guide: Identifying Part of Speech Tags using Conditional Random Fields
In the world of Natural Language Processing (NLP), the most basic models are based on Bag of Words. But such models fail to capture the syntactic relations between words.
For example, suppose we build a sentiment analyser based on only Bag of Words. Such a model will not be able to capture the difference between “I like you”, where “like” is a verb with a positive sentiment, and “I am like you”, where “like” is a preposition with a neutral sentiment.
So this leaves us with a question — how do we improve on this Bag of Words technique?
Part of Speech (hereby referred to as POS) Tags are useful for building parse trees, which are used in building NERs (most named entities are Nouns) and extracting relations between words. POS Tagging is also essential for building lemmatizers which are used to reduce a word to its root form.
POS tagging is the process of marking up a word in a corpus to a corresponding part of a speech tag, based on its context and definition. This task is not straightforward, as a particular word may have a different part of speech based on the context in which the word is used.
For example: In the sentence “Give me your answer”, answer
To understand the meaning of any sentence or to extract relationships and build a knowledge graph, POS Tagging is a very important step.
The Different POS Tagging Techniques
There are different techniques for POS Tagging:
- Lexical Based Methods — Assigns the POS tag the most frequently occurring with a word in the training corpus.
- Rule-Based Methods — Assigns POS tags based on rules. For example, we can have a rule that says, words ending with “ed” or “ing” must be assigned to a verb. Rule-Based Techniques can be used along with Lexical Based approaches to allow POS Tagging of words that are not present in the training corpus but are there in the testing data.
- Probabilistic Methods — This method assigns the POS tags based on the probability of a particular tag sequence occurring. Conditional Random Fields (CRFs) and Hidden Markov Models (HMMs) are probabilistic approaches to assign a POS Tag.
- Deep Learning Methods — Recurrent Neural Networks can also be used for POS tagging.
In this article, we will look at using Conditional Random Fields on the Penn Treebank Corpus (this is present in the NLTK library).
Conditional Random Fields(CRF)
A CRF is a Discriminative Probabilistic Classifiers. The difference between discriminative and generative models is that while discriminative models try to model conditional probability distribution, i.e., P(y|x), generative models try to model a joint probability distribution, i.e., P(x,y).
Logistic Regression, SVM, CRF are Discriminative Classifiers. Naive Bayes, HMMs are Generative Classifiers. CRF’s can also be used for sequence labelling tasks like Named Entity Recognisers and POS Taggers.
In CRFs, the input is a set of features (real numbers) derived from the input sequence using feature functions, the weights associated with the features (that are learned) and the previous label and the task is to predict the current label. The weights of different feature functions will be determined such that the likelihood of the labels in the training data will be maximised.
In CRF, a set of feature functions are defined to extract features for each word in a sentence. Some examples of feature functions are: is the first letter of the word capitalised, what the suffix and prefix of the word, what is the previous word, is it the first or the last word of the sentence, is it a number etc. These set of features are called State Features. In CRF, we also pass the label of the previous word and the label of the current word to learn the weights. CRF will try to determine the weights of different feature functions that will maximise the likelihood of the labels in the training data. The feature function dependent on the label of the previous word is Transition Feature
Let’s now jump into how to use CRF for identifying POS Tags in Python. The code can be found here.
Data Set
We will use the NLTK Treebank dataset with the Universal Tagset. The Universal tagset of NLTK comprises of 12 tag classes: Verb, Noun, Pronouns, Adjectives, Adverbs, Adpositions, Conjunctions, Determiners, Cardinal Numbers, Particles, Other/ Foreign words, Punctuations. This dataset has 3,914 tagged sentences and a vocabulary of 12,408 words.
Next, we will split the data into Training and Test data in a 80:20 ratio — 3,131 sentences in the training set and 783 sentences in the test set.
Creating the Feature Function
For identifying POS tags, we will create a function which returns a dictionary with the following features for each word in a sentence:
- Is the first letter of the word capitalised (Generally Proper Nouns have the first letter capitalised)?
- Is it the first word of the sentence?
- Is it the last word of the sentence
- Does the word contain both numbers and alphabets?
- Does it have a hyphen (generally, adjectives have hyphens - for example, words like fast-growing, slow-moving)
- Is the complete word capitalised?
- Is it a number?
- What are the first four suffixes and prefixes?(words ending with “ed” are generally verbs, words ending with “ous” like disastrous are adjectives)
The feature function is defined as below and the features for train and test data are extracted.
Fitting a CRF Model
The next step is to use the sklearn_crfsuite to fit the CRF model. The model is optimised by Gradient Descent using the LBGS method with L1 and L2 regularisation. We will set the CRF to generate all possible label transitions, even those that do not occur in the training data.
Evaluating the CRF Model
We use F-score to evaluate the CRF Model. F-score conveys balance between Precision and Recall and is defined as:
2*((precision*recall)/(precision+recall))
Precision is defined as the number of True Positives divided by the total number of positive predictions. It is also called the Positive Predictive Value (PPV):
Precision=TP/(TP+FP)
Recall is defined as the total number of True Positives divided by the total number of positive class values in the data. It is also called Sensitivity or the True Positive Rate:
Recall=TP/(TP+FN)
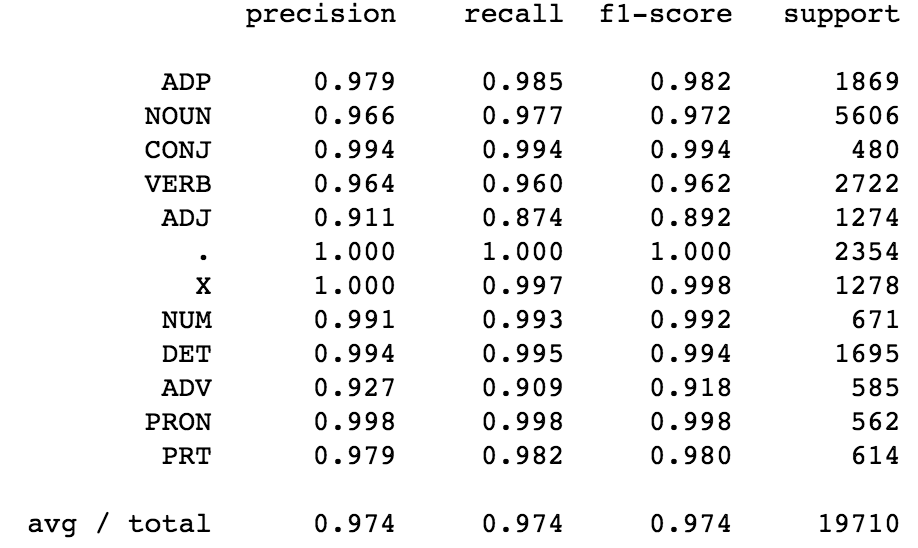
The CRF model gave an F-score of 0.996 on the training data and 0.97 on the test data.
From the class-wise score of the CRF (image below), we observe that for predicting Adjectives, the precision, recall and F-score are lower — indicating that more features related to adjectives must be added to the CRF feature function.

The next step is to look at the top 20 most likely Transition Features.


As we can see, an Adjective is most likely to be followed by a Noun. A verb is most likely to be followed by a Particle (like TO), a Determinant like “The” is also more likely to be followed a noun.
Similarly, we can look at the most common state features.


If the previous word is “will” or “would”, it is most likely to be a Verb, or if a word ends in “ed”, it is definitely a verb. As we discussed during defining features, if the word has a hyphen, as per CRF model the probability of being an Adjective is higher. Similarly if the first letter of a word is capitalised, it is more likely to be a NOUN. Natural language is such a complex yet beautiful thing!
End Notes
In this article, we learnt how to use CRF to build a POS Tagger. A similar approach can be used to build NERs using CRF. To improve the accuracy of our CRF model, we can include more features in the model — like the last two words in the sentence instead of only the previous word, or the next two words in the sentence, etc. The code of this entire analysis can be found here.
Hope you found this article useful. As always, any feedback is highly appreciated. Please feel free to share your comments below.