
Grammars for programming languages
A Boolean grammar was constructed to specify syntax and static semantics (including scoping rules) of a programming language. This was apparently the first such specification by an efficiently parsable grammatical model. Because conjunction and negation operators work on entire strings, rather than merely being a lookahead mechanism, the mentioned grammar is quite knotty.
A new life for cross-references and scoping?
Boolean predicates & and ! in parsing expression grammars are, in fact, positive and negative lookahead predicates, respectively. In the rules for bullet lists in Markdown, predicate &BulletSymbol succeeds if the next symbol of the input is a bullet, and predicate ! succeeds if the next symbol is not a bullet.
Neither of the predicates consume any input: they are only used to check the lookahead symbols in the input, and those lookahead symbols can be regarded as the right context of a string.
Drawing upon both parsing expression grammars and Boolean grammars,
ValidIdentifier : ident & << it was declared beforeValidIdentifier : ident & >> it will be declared later
These two informal rules state that whenever an identifier is used in a program, its declaration should appear either to its left (<<) or to its right (>>).
Consider the following fragment of a program in an assumed C-like language.
int f() { int ms, sec, min; ... return 60 * min;}Let’s write it once again, this time horizontally.

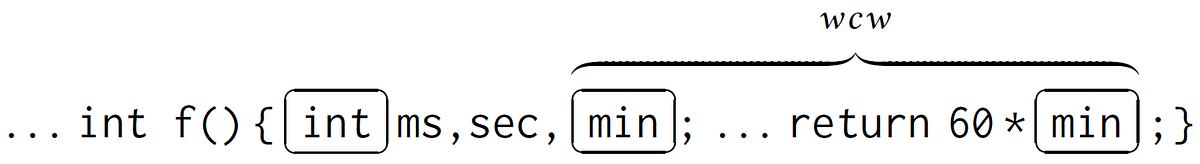
To ensure that identifier min used in the assignment expression is declared, one can verify whether its left context contains a function header (int f() {), keyword int, other identifiers (ms, sec), a comma, and the declaration of identifier min, followed by any other constructs ( ; ... return 60 * ), all the way up to the use of min itself.
This can be expressed in a grammar with contexts almost verbatim.
ValidIdentifier : ident & <<== Functions FuncHeader "int" Identifiers CopiedString
This rule finds the substring between two positions in the input: before the declaration of an identifier and after its use. To include the use of the identifier into this substring, a so called extended left context <<== is used (that is, extended context of an identifier is its left context concatenated with that very identifier). After the desired substring has been found by the rule, it remains to check whether it forms a copy language wcw (and copy language can be defined by a conjunctive grammar, so everything works).
The standard restriction that forbids redeclaration of identifiers can be now expressed by the following rules:
IntegerDeclaration : "int" InvalidIdentifier ";"InvalidIdentifier : ident & ¬ ValidIdentifier
It also becomes possible to distinguish between types of identifiers: the rule for a valid identifier breaks up into several rules, one for each type in the language.
ValidIntegerIdentifier : ident & <<== Functions FuncHeader "int" Identifiers CopiedString
The only difference between these rules is in the keyword that should occur in the left context of an identifier use.
ValidBooleanIdentifier : ident & <<== Functions FuncHeader "bool" Identifiers CopiedString
Because identifiers are now distinguished according to their type, it makes sense to embed type checking directly into a grammar with contexts.
Assignment : ValidIntegerIdentifier "=" IntegerExpression | ValidBooleanIdentifier "=" BooleanExpression
These rules state that a variable of a certain type can only be assigned an expression of the same type.