
Mastering data structures in ruby — linked lists
Mastering data structures in ruby — singly linked lists
A singly linked list (or just linked list) is a data structure that you can use to represent almost any sequence of elements. Unlike their cousins the arrays, linked lists can grow or shrink to accommodate variable-sized data without hassles. A nice trait to have for those cases where the exact amount of data is unknown beforehand.
Each element on the linked list is represented by a node that contains two attributes:
- The value that the element holds.
- A pointer to the next node in the list.
The first node of the list is called “head” and the last one is called “tail”. To mark the end of the list, you have to set the next pointer of the tail node to nil.
[ value | next ] -> [ value | next ] -> [ value | next ] -> X (nil)To get an element from a singly linked list you have to traverse it from head to tail. That’s the only direction possible because nodes on singly linked lists don’t have back pointers.
Singly linked lists interface
Here is the interface of the linked list. (I have included some operations that are no present in most programming books just because they show up quite frequently the wild and it’s handy to have them around.)

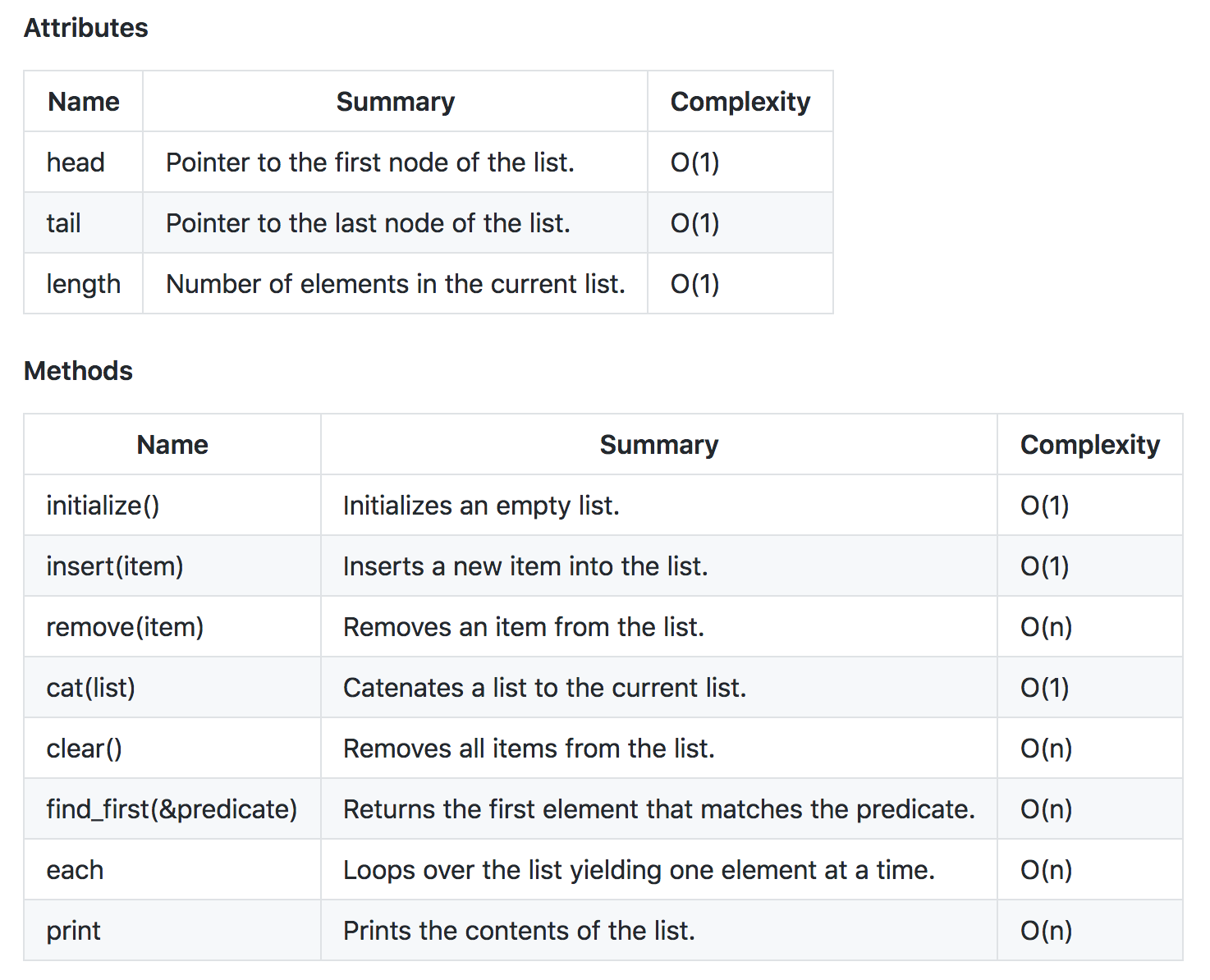
Implementations details
What flows is a detailed description of each method along with its complexity and its source code.
But before jumping into the code, let’s talk a bit about Big 0, a notation that allows us to describe how an algorithm will perform as the data that it has to process increases. Since in this post we are going to work on methods with O(1) and O(n) complexity, let’s focus on that.
- O(1) Means that the algorithm will perform in constant time. That is, that it doesn’t matter is the list has one element or a million, the time required to run the algorithm won’t change at all. For instance, insert and cat are both O(1) operations.
- O(n) Means that the resources required to run the algorithm will increase linearly with the volume of the data it has to process. If we have to traverse a list of 1 element, complexity will be O(n) where n=1. If we have to do the same with on a list that has a million elements, complexity will be O(n) where n = 1.000.000.
On linked lists, the performance of operations is said to be are polarized, because they are either O(1) or O(n).
Of course, there is a lot more about Big O. But that’s a subject for another post.
Initialize
This method is the list constructor. The only thing it does is to create an empty list setting the head and tail pointer to nil, and the list length to 0.
The complexity of this method is O(1).
def initialize self.head = nil self.tail = nil self.length = 0endInsert
Creates a new node to insert a value into the list. If the list has no nodes, the new node becomes the head of the list; otherwise, it’s appended at the tail of the list.
Since the list keeps pointers to its head and its tail, the complexity of this method is O(1).
def insert data node = Node.new data unless head self.head = node else self.tail.next = node end self.tail = node self.length += 1endRemove
Removes the given node from the linked list and adjusts pointers to keep the elements together.
This is probably the most complex method to implement on linked lists because depending on the location of the node to be removed we need to do different things.
If the node we have to remove is the head of the list, we need to cover two situations:
- Head is the only node in the list. We set head and tail to nil and we are done.
- There are more elements in the list. The node that’s next to head becomes the new head and the original head goes out of scope and gets ready to be “garbage collected”.
If the node we have to remove is not at the head of the list, we have to traverse the list from head to tail to find the node to be removed and the node that precedes it. We need both nodes because we have to set the next pointer of the precedent node to the next pointer of the node that will be removed. After doing that, the target node is effectively removed.
(Unlike in languages like C, in ruby we don’t have to manually release allocated memory. When an object goes out of scope and there are no references pointing to it, the object becomes eligible for garbage collection; from there on is up to the garbage collector when to reclaim those allocated bytes.)
Since we may have to walk the whole list to remove the node, the complexity of this method is O(n).
def remove node return nil unless node if node == head if head.next.nil? self.head = self.tail = nil else self.head = self.head.next end else tmp = self.head while tmp && tmp.next != node tmp = tmp.next end tmp.next = node.next if tmp end self.length -= 1endCat
This is a handy method that allows us two join two lists together. The implementation is really simple, the only thing we need to do is set the next pointer of the tail node to point to the head of the list we want to append and adjust the list length.
The complexity of this method is O(1).
def cat list return nil unless list self.tail.next = list.head self.length += list.lengthendClear
This method removes all elements from the list. Since we have to walk the whole list, the complexity is O(n).
def clear while self.length > 0 remove self.head endend
Find First
This method allows us to get the first element of the list that satisfies a given predicate.
In this context, a predicate is a function that takes an element from the list as its only argument and returns a boolean value indicating whether the item satisfies the conditions expressed in that function.
The way the list finds the first element that matches the predicate is by walking its elements and applying the predicate to each one of them until the result is true or the list gets exhausted. Whatever comes first.
The complexity of this method is O(n) because we may have to walk all of the elements in the list.
def find_first &predicate return nil unless block_given? current = self.head while current return current if predicate.call(current) current = current.next endendTo see this method in action, let’s say you have a list that contains a bunch of integers and you want to find the first occurrence of the number 3.
The “rudimentary” way (what you see in most books) could be something like this:
e = nil current = list.head while current if current.data == 3 e = current.data break end current = current.next endBy using the helper method find_first you will get the same result writing ruby idiomatic code. (Elegant, succinct and right to the point!)
e = list.find_first { |item| item.data == 3; }Each
This method is a common ruby idiom for objects that support enumeration. Basically, what it does is to yield items from the list, one at a time, until the list is exhausted.
If you are not familiar with ruby, this may seem odd to you, but in ruby, methods can take arguments and a block of code. Typically, enumerators yield items to a given block of code (or lambda).
The complexity to yield the next item is O(1). The complexity to yield the whole list is O(n).
def each return nil unless block_given? current = self.head while current yield current current = current.next endendThis method prints the contents of the current list.
(A good example on how to use the each method, BTW.)
# Prints the contents of the list. # Complexity: O(n). def print if self.length == 0 puts "empty" else self.each { |item| puts item.data } end endWhen to use singly linked lists
Linked lists are well suited to manage variable-sized sequences of objects. So, whenever you have to handle collections of unknown sizes, singly linked lists will certainly do. But keep in mind that in CS there are no silver bullets, linked lists work well when:
- Sequences are small.
- Sequences are large but you don’t care about lookup times.
- You can sacrifice read performance for the sake of optimal writes (inserts).
- You can afford to walk the list from head to tail, only.
To-do lists, shopping cart items, and append-only logs are good fits for singly linked lists; whereas carousels, windows managers and multi-million data sets are not.
So, that’s about it for singly linked lists. I hope you enjoyed it!
You can click here to get the source code from this post.
Next time, doubly linked list. Stay tuned.
Thanks for reading! and see you next time.
PS: Don’t forget to clap if you like this post :)