
Movin’ Data is a Dream
Search is a big feature at Shaadi.com. It helps our matchmaking algorithms bring out the best matches and it gets our customers closer to finding their partners based on their preferences.
Almost two years ago, our search was running on Solr and MySQL. Data sync between these two systems was rough. We had to sync our search database with our transaction database. To do this, we used to rely on cron jobs but these were hitting their limits. The queries required joining across multiple tables. And sometimes, we could not add extra fields as the JOINs became prohibitively expensive. Also, we have several different databases with profile information scattered across them and as you might know, joining across databases is simply impossible.
The system was fragile and hitting its limits. We needed something else!
Little did we know that a single Kafka stream would give us that power.
Transitioning to a better search experience


The first thing we did was move to ElasticSearch as clustering Solr is very hard and ES offers excellent horizontal scaling semantics.


At Shaadi, we capture more than 200 attributes of a user, which includes their contact details, appearances details, occupation details, family details, partner preferences, etc. The attributes are captured in RDBMS (MySQL). From there we wanted to update the profile index in Elastic Search.
So what we did was write a puller
Every time a user’s profile was updated, we made an entry into a table in MySQL. A cron job would run every 5 minutes and process each entry in this table by firing a query on the MySQL profile tables and would write the updated profile data into ElasticSearch.
A twist in the tale
The puller program served well for the first 20–30 attributes. But as we started adding more and more attributes, we started facing some key limitations:
- The SQL for fetching data was becoming big and complex
- We could not scale horizontally without having to re-start more program instances to cope up with the growing data payloads. Since all of this was hitting the same database we started having to scale the database out horizontally as well with follower databases. This was going to get expensive!
- Adding hooks at various places to add user id in lookup table increased complexity and made our setup more fragile
- Back-populating started becoming a very lengthy and time consuming process. Making a new field available in ES took an average of 7–10 days.
- Adding filters or transformation on the data started slowing our infra down


Time to re-think the system (architecture)
Adapting ES came with it’s own problems. We realised that we were quickly heading towards a “spider nest” architecture because to update elastic, we were manually updating MySQL using queue tables and every application had to write to those tables. This meant there was no single unified layer we could publish to!
Also we couldn’t do partial updates. We were trapped in an architecture where we were unable to move or scale.
We now wanted to design a system which could overcome these limitations and give us a fast, persistent queue between our data sources and make our data searchable. And that’s when we started investigating what Kafka Streams could do for us.
Managing Risk


We had heard Kafka was a beast to run in production and that it would take the team some experience with Kafka before the whole organisation could lean on it as the backbone of the data pipeline. So we wanted a non-critical use case we could experiment with. And that’s when we thought about all the dashboards we could power from this stream.
Dashboards are not user facing and so not mission critical. Our Kafka could fail and all we’d have is some jagged lines on the dashboard. So now we needed a way to get event data onto the Kafka stream. Being a 17 year old system, there are myriad entry and exit points for every type of interaction. Some parts of the website use an older system, some new APIs use a newer system, the customer support system also writes to the database. There was just no single point of entry into the system where we could start capturing events from. That’s when we decided to read the events from the database itself.
Enter Maxwell
While building this integration, we came across a awesome open-source tool called Maxwell from engineers out in zendesk land. Maxwell is a tool which can read your Mysql binlog and produce a Mysql log as events. Piping these events into Kafka then became a trivial matter. Now whenever there is any insert, update or delete happening on the table, Maxwell produces that change in Kafka. A beautiful python script then takes those events, hydrates them with any metadata and sends them to datadog.
If you want to get more context of what I mean by MySql log to events, you should really watch this wonderful talk “Turning database inside out” by Martin Kleppmann.
Our first experience with Kafka was learning all the ways in which our brand new distributed system could fail.

The journey to making Kafka reliable was a memorable one, which we will cover in Part Two of this series. For now, let’s see what our new architecture is going to look like.

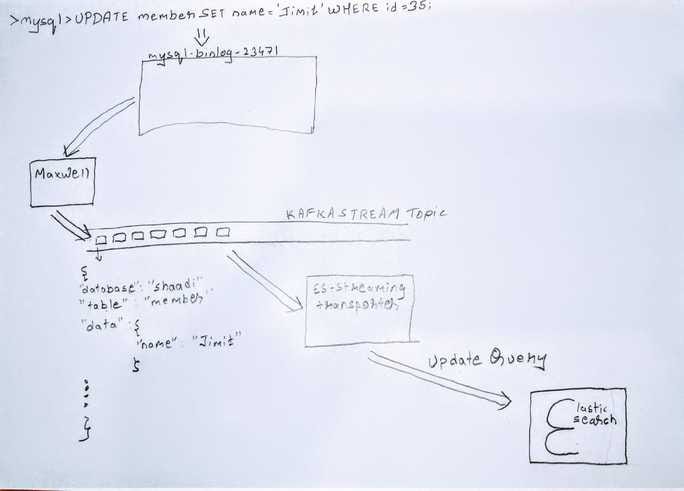
Now whenever, an insert or update happens in the table we are interested in, Maxwell produces the change event as a message in a Kafka topic.
From there a Kafka Consumer (es-streaming-transporter) takes that message and processes it according to the transformation logic required for that attributes. And after that a update query is fired on ES.
So what you get with Kafka is a decoupled architecture that looks like this:
Journey from puller to transporter
The system sketched above is divided into 2 parts:
First part is powered by Maxwell which is responsible of producing database changes by reading Mysql binlogs.
Second part consists of the ESST aka elastic-search-streaming-transporter. ESST is a kafka consumer written in python, where all the transformation logic resides based on the table. Based on the table, it loads the transformation logic for that table and generates the ES update query.

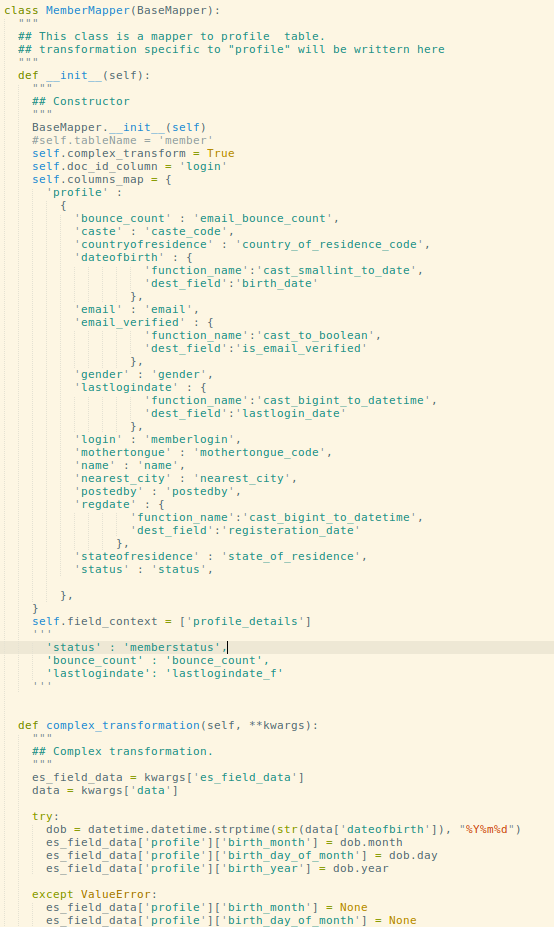
Et Voila! Not more SQL queries needed to fetch data!
To scale horizontally, we just start more consumers. Also Maxwell scales superbly. Our experience shows Maxwell producing 43 Million updates in less than 10 minutes with it’s bootstrap feature.
Instead of adding complex filters or transformations on the data, we now let ESST handle it.
Our new architecture with Kafka allows us to create new aggregations real fast. For example, our initial data model had us maintaining only one app notification end point per user. With the release of Sangam, our community matchmaking product, we needed to maintain more than one endpoint per user. With the streaming transporter, this kind of data model change which would have required expensive alterations across the app and database, was completed trivially merely by changing the code in the streaming transporter.
This is the kind of velocity that a fine data pipeline can provide!
But that’s not the whole story…
What was really remarkable about adapting Kafka and the new stack is the way it gave us a new vocabulary and conceptual framework to think about our components.
In part two, we will talk about the journey to a reliable Kafka setup including the devops, high availability and failure and recovery modes of Kafka. In the third part we will explore the resultant cultural shifts our engineering org and how it changed the way we now move data anywhere we want to and in any shape we want.
Credit here goes to our engineers and storytellers: Sanket Shah, Jimit Modi and our CTO, svs
Follow us here to read part two of this post.