
Quickbooks Search Platform — Our Journey to AWS
Quickbooks Search Platform — Our Journey to AWS
“The journey is what brings us happiness, not the destination”
— Dan Millman, Way of the Peaceful Warrior
In all honesty, reaching our destination made us just as happy as the journey itself, probably more so ?. Our journey has been going on for about a year now and finally,
The Beginning
About a year and half ago, after a lot of experiments and “Follow Me Homes” with our customers, we finally launched QuickBooks Universal Search, with only one goal in mind — be “the Google” of Quickbooks — power type-ahead search
This was by no means a small feat — We had to design an extremely scalable and distributed search platform that would not crumble under peak loads of incoming requests at every character typed by the user (debounced of course!). Nor should it require any major upgrades in the near future because being deployed in our own datacenters had limitations on how fast we could scale our hardware. So, we had to prepare for the future. A future where we can continue to support this platform from our own datacenters for the upcoming year, while we journey towards AWS.
The Architecture
Now Pay Attention. This is where I dump all the gruesome, gory details about how complex our Application Architecture was and how intertwined our usage of technologies was just so we could scale. Sounds about right?
“Simplicity is the soul of Efficiency”
— Austin Freeman (in The Eye of Osiris)
No, actually it does not. Architectures are supposed to be as simplistic as possible. Simplicity of our architecture is what allowed us to achieve maximum Developer Productivity and with that comes faster (and more frequent) releases.
Below is the high level design of what our architecture looked like when we were in our own datacenters (from here on, we will refer to datacenters as IHP — Intuit Hosting Platform — consisting of 2 datacenters, LVDC & QDC).

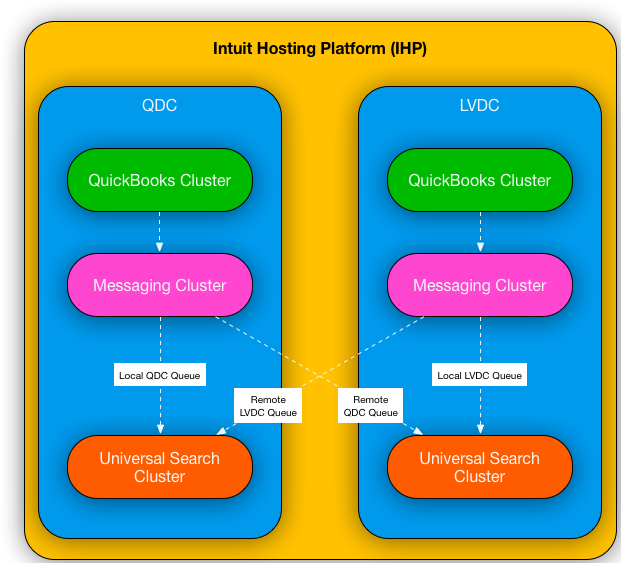
Quite simple, really. Search Clusters are hosted in both LVDC & QDC datacenters. At any point in time, Quickbooks would be active in one datacenter, thus publishing events on the message bus. The messaging cluster would forward the messages to 2 queues, one per each search cluster in each datacenter. Point to note — we had to do this because Elasticsearch did not provide Data Center Replication out-of-the-box. We basically used Eventing Architecture to feed both our Search Clusters in realtime, essentially being capable of Active-Active DR strategies. Pretty Standard Stuff.
Speaking of Elasticsearch, yes — We chose Elasticsearch as our weapon of choice to power type-ahead search queries. This Lucene backed search engine is quite powerful and is really the de-facto industry standard for enterprise search. Plus it scales quite well if proper design patterns are implemented based on the nature of the application (Caution: I cannot stress enough — Do your due diligence upfront on how you plan to index, store & query your data because as your business grows, your original designs (to some extent) will determine how well you scale. If you don’t plan well, you will keep reindexing your data and rebalancing your cluster all day long!). Without going too deep into Elasticsearch design, I would just like to share a brief overview about how the data is organized in indices/shards. This is important to discuss because this is what allowed us to scale at Terabyte scale with sub-second latencies in our queries.
Our Elasticsearch Cluster has 100 indices with the naming conventions of “search-XX” where XX is just a representation of our bucketing strategy. For example, company with realmId 12343564 will belong to index “search-35”. Because our queries are always constrained within a company, there will never be a cross-index query. This already gave us a huge boost in our performance.
Each index has 15 primary shards with 1 replication. To further tune and boost our performance we used Elasticsearch Routing to index all documents specific to a company in a specific shard within an index, using realmId as the routing value. With the understanding that our queries are strictly bounded within the context of a company, this bolstered the idea of each query specific to a company will always route the same shard, further enhancing our performance
“Your most unhappy customers are your greatest source of learning”
— Bill Gates
What’s the take-away from this? — Know Your Customers, their data and their business! This is where “Follow Me Homes” with our customers really paid off. We spent some serious time learning how our customers search their data, what specific data do they really care for and what kind of search capabilities do they expect on their fingertips with a Modern SaaS based product such as QuickBooks. Technologies are flexible enough to tune at will. It all boils down to how you tune them to your customers’ delight!
Talking about Scale — With this simplistic architecture in place, we currently ingest around 50 million business transactions and handle 2 million queries per day — most of it during our 8 to 10 hour peak window. We expect these numbers to grow exponentially, mostly because this feature is currently available to only 20% of our customers (we are slowly rolling it out to all our customers).
Our Application topology is quite simplistic too. We have 10 stateless application servers fronted by a Load Balancer (round-robin routing), which eventually is fronted by Gateway. The application servers connect to Elasticsearch Cluster for feeding-in and querying-out the data. Security is baked in through and through across all the layers of Application Topology by our internal Security Tools & Libraries.
Decisions Decisions …
By the time we started looking at moving to the cloud, we had multiple options at our disposal. There was some serious back and forth within the team and a lot of thought was put into how we should arrive on a decision. Here are the guiding principles that we agreed on to determine our choice.
- Migration Simplicity
- Security
- We rather not manage the cluster if it can be done for us (Upgrades, Scaling etc.)
- Maximize Developer Productivity
- Blazing fast release cycles
Without going into the depths of the discussions that we have had (internal as well as external), AWS Elasticsearch Service came out on top — That whole “we will securely manage it for you” vibe was a perfect sell. We as a team would rather concentrate on solving customer problems. Not to mention, all of the other solutions that AWS provides to manage our application lifecycles, was just a cherry-on-top. The whole AWS ecosystem is quite a well oiled machine and there was no reason for us to shy away from it, but rather just embrace it all. That being said, we did have to make a trade off on one of our guiding principles — Migration Simplicity.
IHP → AWS
Our IHP Elasticsearch clusters were at version 5.3.0. In the 6 months we have been supporting our usecases from those clusters, there were major upgrades to Elasticsearch and as you can imagine, with major version upgrades (6.x.x) came even major breaking changes. Some of these breaking changes were important enough to address.


To be fair, we knew this was coming for some time now (Thanks to discussions we had with Shay Banon on Elasticsearch IRC channel couple of years back). So, even though 5.x.x supported multiple mapping types, and we did use it heavily, the actual mappings were kept flexible enough for us to easily port to the new world (6.x.x). But change in mappings means fully re-indexing your data. We have close to 10 TB of data with about 8 billion documents. Re-indexing wasn’t going to be easy. It needed to be thought through.
Another major huddle for us to overcome was moving away from the Elasticsearch Transport Clientand embrace the Elasticsearch Java REST Client. This waspartly because with AWS Elasticsearch, we cannot use the transport client as AWS only supports HTTP on port 80, but does not support TCP Transport (which is what Transport Client requires). This was a real bummer for us because this meant code change and just seamlessly porting over the application on the new platform wasn’t an option anymore.
Improvise. Adapt. Overcome.
The team have been going back and forth on how we can support Search in IHP and Search in AWS while having the same codebase. On one hand we didn’t want to upgrade our IHP infrastructure to 6.x considering it will be a waste of time. On the other hand, we didn’t want to move to AWS with 5.x which was already an older version and we will have to upgrade anyways. Whichever route we choose, there was code change regardless. We needed to choose the path of least resistance.


I remember having a distinct phone call with Akbar (our team lead) one fine evening while crawling through peak traffic of Bay Area. After discussing it for way too long, he said (and I am paraphrasing) — “Let’s just do it, man. Let’s just treat both as separate applications. We will just deprecate the application in IHP and build a new one for AWS. We will essentially just port over all the code to a new git repository. At least we will get a fresh start to do whatever we want. Let’s keep it simple”
The essence of the discussion was quite simple, yet beautiful. We will deprecate what we have in IHP, add no new features. At the same time, we will port over all the code to a new repository, experiment with some new CICD Frameworks (Intuit Templating Service — more on this in another blog) and accelerate our journey to Modern SaaS (more in another blog). We even simplified our data migration strategies. After discussing a lot with AWS Solution Architects and working through the problem, we realized that we didn’t want to invest in writing one off tools (AWS Lambdas, Kinesis Firehose). We improvised yet again and kept things simple. We decided to use the tools that we already had at our disposal, without writing any one-off tools. 2 things are for certain — 1) We needed new indices in AWS anyways because with 6.2 we cannot use mapping types. 2) Because these will be new indices with new mappings, we will have to re-index the data.So here’s how we planned our data migration
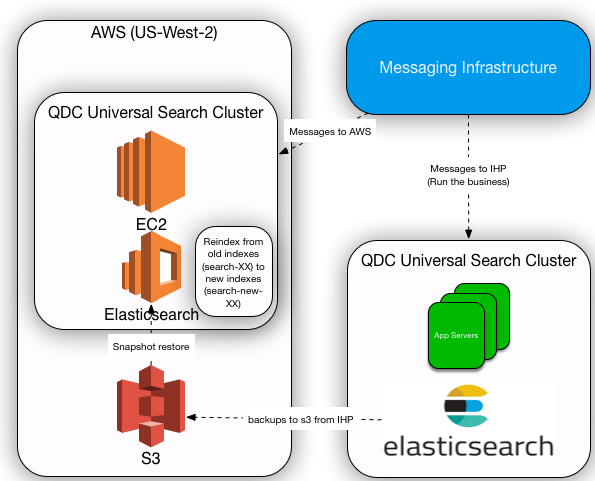
- We will deploy a fresh new Elasticsearch Cluster in AWS with 6.2. We will also deploy application code compatible with Elasticsearch 6.2.
- We will open our flood gates of active incoming messages and start indexing new data in new indices (search-new-XX).
- In the meantime, we will get the latest data snapshot backed-up from IHP to S3 with all indices (search-XX).
- Thanks to the ability of restoring snapshot from S3 (and 5.3 snapshot restore compatible with 6.2 cluster), all the old indices (search-XX) are now restored in the new AWS Elasticsearch Cluster.
- The best part? the old and new indices now co-exist in the same cluster! With this in place, now we just use the Reindex API to reindex all the documents from old indices (search-XX) to new indices (search-new-XX). We also use entity version type as external so that newer versions of documents (within the time delta of us reindexing and new data coming in through messaging) are not overwritten.
BOOM !

And just like that, Universal Search in AWS was open for business. And now it was time for experimentation & testing. We excelled at all the possible OpMechs in our new DevOps World. We have all-round monitoring, alerting, CI/CD and Testing Automations (One more Blog for another time). Our checkin → production window has reduced to under 1 hour, with all the right guard rails. I’d continue on how we marveled at our own magnificence, but I guess it’s time to move on ?.
Adios IHP

The team did grow a special bond with you. Those late night alerts of the cluster disks getting full with random audit logs. Those demanding PagerDuty notifications of clusters going RED while the team members enjoyed their long weekends at a Coffee Shop in Amsterdam or with the Kangaroos in Australia. We got special memories with you and we will cherish those for as long as we can. You will be missed ?
What’s Next
We aren’t done yet. The team is on track to fully roll out Universal Search to all customers. Because we anticipate the usage to grow exponentially, we will want to be bold yet cautious about how we onboard all customers. Being deployed in AWS has opened up a lot more options for us in terms of scalability and we would like to seize this opportunity to experiment more and fail fast if need be. We will continue to monitor Voice of Customers and User Voice channels for any feedback on how to improve the quality of universal search
Final Thoughts
Just like all other products, Universal Search had it’s ebb and flow. But the team’s Customer Obsessed culture, backed by intense desire to learn, simplify and innovate, is what really made it successful. I am extremely proud of all the team members (Akbar, Shruti, Mukesh, Chinmay, Tuan Le) who poured their hearts out getting this feature into Customers’ hands. It was one of my most memorable journeys of delivering a widely used feature with such an Awesome Team. Kudos & Thank you!
We have achieved a huge milestone, but this is just the beginning. Stay tuned for more !