
五分鐘輕鬆瞭解Hbase面向列的儲存
行式儲存
傳統的資料庫是關係型的,且是按行來儲存的。如下圖:
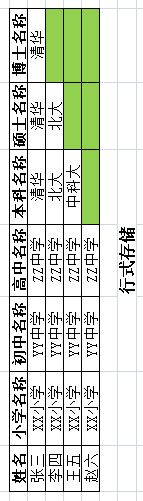
其中只有張三把一行資料填滿了,李四王五趙六的行都沒有填滿。因為這裡的行結構是固定的,每一行都一樣,即使你不用,也必須空到那裡,而不能沒有。來一張形象的圖:

不管你坐或不坐,座位都在那裡,不離不棄。
列式儲存
為了與傳統的區別,新型資料庫叫做非關係型資料庫,是按列來儲存的。如下圖:
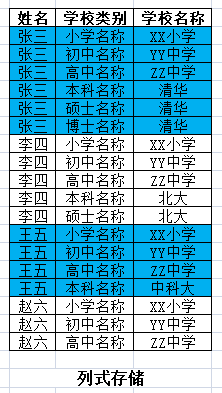
初次看列式儲存稍微有點懵,下面給出行存與列存的轉換:
原來張三的一列(單元格)資料對應現在張三的一行資料。原來張三的六列資料變成了現在的六行。
原來的六列資料是在一行,所以共用一個主鍵(即張三)。現在變成了六行,每行都需要一個主鍵(不然不知道這行資料是誰的),所以原來的主鍵(即張三)重複了六次。
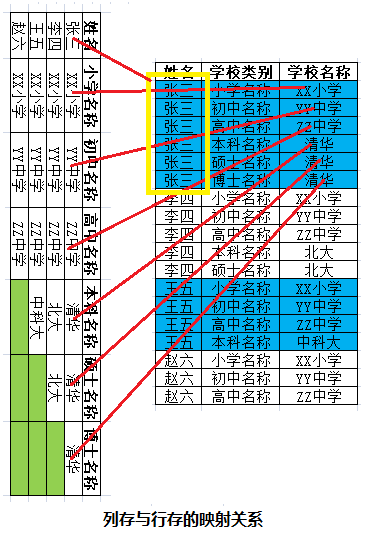
由於原來的列變為了現在的行,有需要就加一行,沒需要就不加,不會造成空間浪費。來一張形象的圖:

(擺渡車內部就是一個大平板)
你要站便站,我給你空間,你不站便不站,還給我空間。
行列對比
① 行式儲存傾向於結構固定,列式儲存傾向於結構弱化。
(行式儲存相當於套餐,即使一個人來了也給你上八菜一湯,造成浪費;列式儲存相等於自助餐,按需自取,人少了也不浪費)
② 行式儲存一行資料只需一份主鍵,列式儲存一行資料需要多份主鍵。
③ 行式儲存存的都是業務資料,列式儲存除了業務資料外,還要儲存列名。
④ 行式儲存更像一個Java Bean,所有欄位都提前定義好,且不能改變;列式儲存更像一個Map,不提前定義,隨意往裡新增key/value。
官方介紹
Apache Hbase是Hadoop資料庫,一個分散式、可擴充套件、大資料儲存。
當你需要隨機地實時讀寫大資料時使用Hbase。它的目標是管理超級大表-數十億行X數百萬列。
Hbase是一個開源的、分散式的、帶版本的、非關係型資料庫,模仿谷歌的BigTable。BigTable使用Google File System作為分散式資料儲存,同理Hbase使用HDFS。
Hbase世界
Hbase雖然弱化了結構,但並不等於放任不管。傳統關係型資料庫在插入資料前表結構(即所有列和列的資料型別)已經是嚴格確定的。
Hbase的表在放入資料前也有需要確定下來的東西,那就是Column Family
一個家庭的成員之間具有血緣關係,所以一個列族的多個列之間通常也具有某種關係,比如相似或同種類別。所以列族可以看作是某種分類(歸類)。
一個非常常見的例子,去面試的時候,一般前臺MM都會讓填一張表,通常資訊很多,每個公司又不盡相同。但大致可以分三類:人員基本資訊,教育經歷資訊,工作經歷資訊,這三個類別其實就相當於三個列族。如下圖:
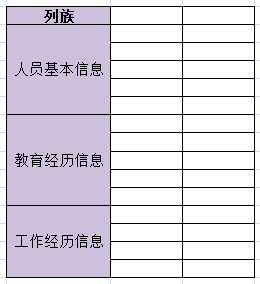
每個類別裡都會有具體的資訊,比如人員基本資訊裡有姓名、電話、出生年月等,它們就相當於一個個識別符號(變數名),在Hbase中叫做Column Qualifier(列修飾符)。列修飾符位於列族裡面用來標識一條條資料。如下圖:
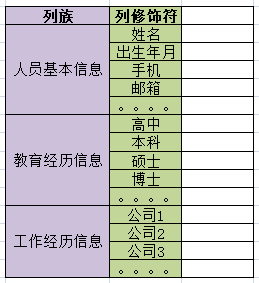
在Hbase中一個列族(Column Family)和一個列修飾符(Column Qualifier)組合起來才叫一個列(Column),使用冒號(:)分割,列族:列修飾符,如下圖:

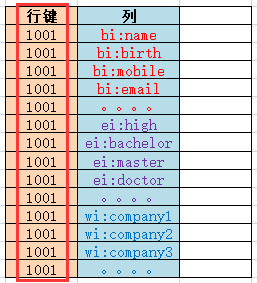
在傳統資料庫中每一行的唯一識別符號叫做主鍵,在Hbase中叫做row key(行鍵)。如下圖:
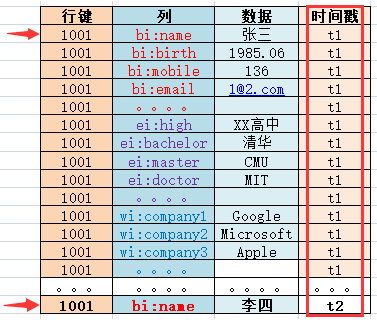
資料在進入Hbase時都會被打上一個時間戳,這個時間戳可以作為版本號來使用。
在t1時間我存入一個人的基本資訊,之後發現姓名錯了,在t2時間又更新了姓名,此時並不會去更新原來的那條資料,而是又插入了一條新資料且打上新的時間戳。
此時去查詢獲取的是新資料,彷彿是更新了,但其實只是預設返回了最新版本的資料而已。如下圖:
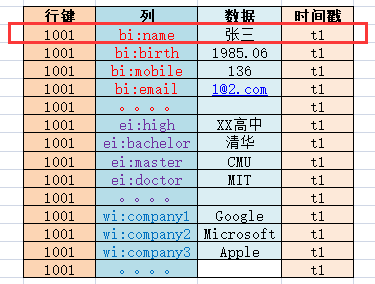
一個行鍵、列族、列修飾符、資料和時間戳組合起來叫做一個單元格(Cell)。這裡的行鍵、列族、列修飾符和時間戳其實可以看作是定位屬性(類似座標),最終確定了一個數據。下圖中的一行相等於Hbase中的一個單元格:
一個行鍵、一到多列(包括資料)組合起來叫做一行(Row)。下圖中所有1001的資料合起來相當於Hbase中的一行,1002的相當於另一行:
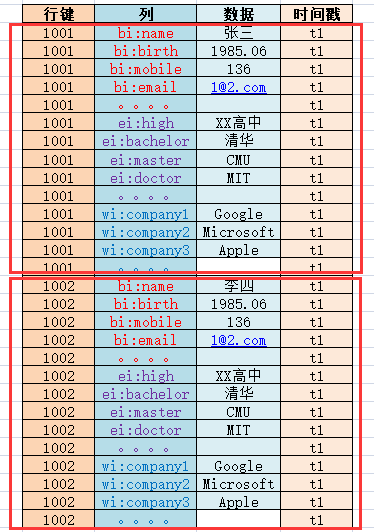
在Hbase中,只要確定了列族(具體的列不用管),表(Table)就確定了。如下圖:

官方文件中提醒:把傳統資料庫中的表/行/列的概念用在Hbase中不是一個有幫助的類比。相反可以把Hbase的表想象成一個多(兩)維Map(Map套Map)。列族是第一維,列修飾符是第二維。
說明:任何細微的差別在大數量時都會被無限放大,那麼列族和列修飾符的名字起的短一些能夠節省可觀的空間。
說明:從嚴格的列式儲存的定義來看,Hbase並不屬於列式儲存,有人稱它為面向列的儲存,請各位看官注意這一點。
(完)
程式設計新說
用獨特的視角說技術
