
How to train Keras model x20 times faster with TPU for free
How to train Keras model x20 times faster with TPU for free


For quite some while, I feel content training my model on a single GTX 1070 graphics card which is rated around 8.18 TFlops single precision, then Google opens up their free Tesla K80 GPU on Colab which comes with 12GB RAM, and rated at slightly faster 8.73 TFlops. Until recently, the Cloud TPU option with 180 TFlops pops up in Colab’s runtime type selector. In this quick tutorial, you will learn how to take your existing Keras model, turn it into a TPU model and train on Colab x20 faster compared to training on my GTX1070 for free.
We are going to build an easy to understand yet complex enough to train Keras model so we can warm up the Cloud TPU a little bit. Training an LSTM model on the IMDB sentiment classification task could be a great example because LSTM can be more computationally expensive to train than other layers like Dense and convolutional.
An overview of the workflow,
- Build a Keras model for training in functional API with static input
batch_size. - Convert Keras model to TPU model.
- Train the TPU model with static
batch_size * 8and save the weights to file. - Build a Keras model for inference with the same structure but variable batch input size.
- Load the model weights.
- Predict with the inferencing model.
You can play with the Colab Jupyter notebook — Keras_LSTM_TPU.ipynb while reading on.
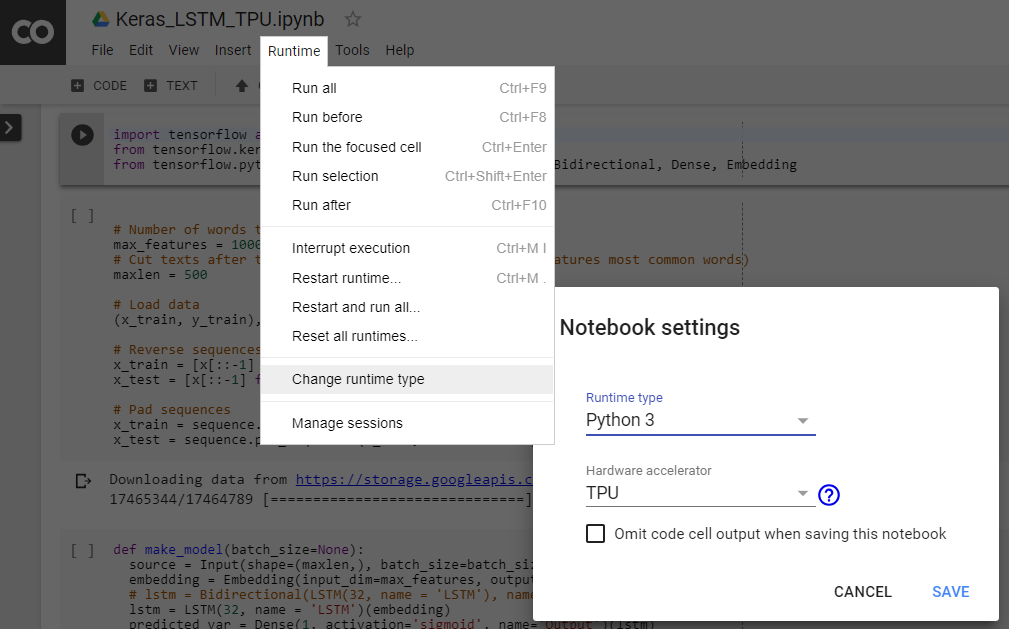
Firstly, Follow the instruction in the image below to activate the TPU in the Colab runtime.
Static input Batch size
Input pipelines running on CPU and GPU are mostly free from the static shape requirement, while in the XLA/TPU environment, static shapes and batch size is imposed.
The Could TPU contains 8 TPU cores, which operate as independent processing units. The TPU is not fully utilized unless all eight cores are used. To fully speed up the training with vectorization, we can choose a larger batch size compared to training the same model on a single GPU. A total batch size of 1024 (128 per core) is generally a good starting point.
In case you are going to train a larger model where the batch size is too large, try slowly reduce the batch size until it fits in TPU memory, just making sure that the total batch size is a multiple of 64 (the per-core batch size should be a multiple of 8).
It is also worth to mention when training with larger batch size; it is generally safe to increase the learning rate of the optimizer to allow even faster convergence. You can find a reference in this paper — “Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour”.
In Keras, to define a static batch size, we use its functional API and then specify the batch_size parameter for the Input layer. Notice that the model builds in a function which takes a batch_size parameter so we can come back later to make another model for inferencing runs on CPU or GPU which takes variable batch size inputs.
Also, use tf.train.Optimizer instead of a standard Keras optimizer since Keras optimizer support is still experimental for TPU.
Convert Keras model to TPU model
The tf.contrib.tpu.keras_to_tpu_model function converts a tf.keras model to an equivalent TPU version.
We then use the standard Keras methods to train, save the weights and evaluate the model. Notice that the batch_size is set to eight times of the model input batch_size since the input samples are evenly distributed to run on 8 TPU cores.
I set up an experiment to compare the training speed between a single GTX1070 running locally on my Windows PC and TPU on Colab, here is the result.
Both GPU and TPU takes the input batch size of 128,
GPU: 179 seconds per epoch. 20 epochs reach 76.9% validation accuracy, total 3600 seconds.
TPU: 5 seconds per epoch except for the very first epoch which takes 49 seconds. 20 epochs reach 95.2% validation accuracy, total 150 seconds.
The validation accuracy for TPU after 20 epochs are higher than GPU may be caused by training 8 batches of the mini-batch size of 128 samples at a time.
Inferencing on CPU
Once we have the model weights, we can load it as usual and make predictions on another device like CPU or GPU. We also want the inferencing model to accept flexible input batch size, that can be done with the previous make_model() function.
You can see the inferencing model now takes variable input samples,
_________________________________________________________________Layer (type) Output Shape Param # =================================================================Input (InputLayer) (None, 500) 0 _________________________________________________________________Embedding (Embedding) (None, 500, 128) 1280000 _________________________________________________________________LSTM (LSTM) (None, 32) 20608 _________________________________________________________________Output (Dense) (None, 1) 33 =================================================================
Then you can use the standard fit(), evaluate() functions with the inferencing model.
Conclusion and further reading
This quick tutorial shows you how to train a Keras model faster leveraging the free Cloud TPU resource on Google Colab.