
Solving the Kaggle Telco Customer Churn challenge in minutes with AuDaS
Solving the Kaggle Telco Customer Churn challenge in minutes using AuDaS
AuDaS is the automated Data Scientist developed by Mind Foundry which aims to allow anyone, with or without a background in Data Science to easily build and deploy quality controlled Machine Learning pipelines. AuDaS empowers Business Analysts and Data Scientists by allowing them to easily insert their domain expertise in the model building process and extract actionable insights.
In this tutorial we are going to see how we can build a classification pipeline in minutes using AuDaS. The goal is to predict Telco customer churn using data from Kaggle. In this case, a customer churns when they decide to cancel their subscription or not renew it. This is costly for Telcos because it is more expensive to acquire new customers than retain existing ones. With a predictive model, a Telco can anticipate which of its customers are most likely to churn and take the appropriate decisions to retain them.
In this tutorial we will follow the standard Data Science process:
- Data Preparation
- Pipeline Construction and tuning
- Interpretation and deployment
Data Preparation
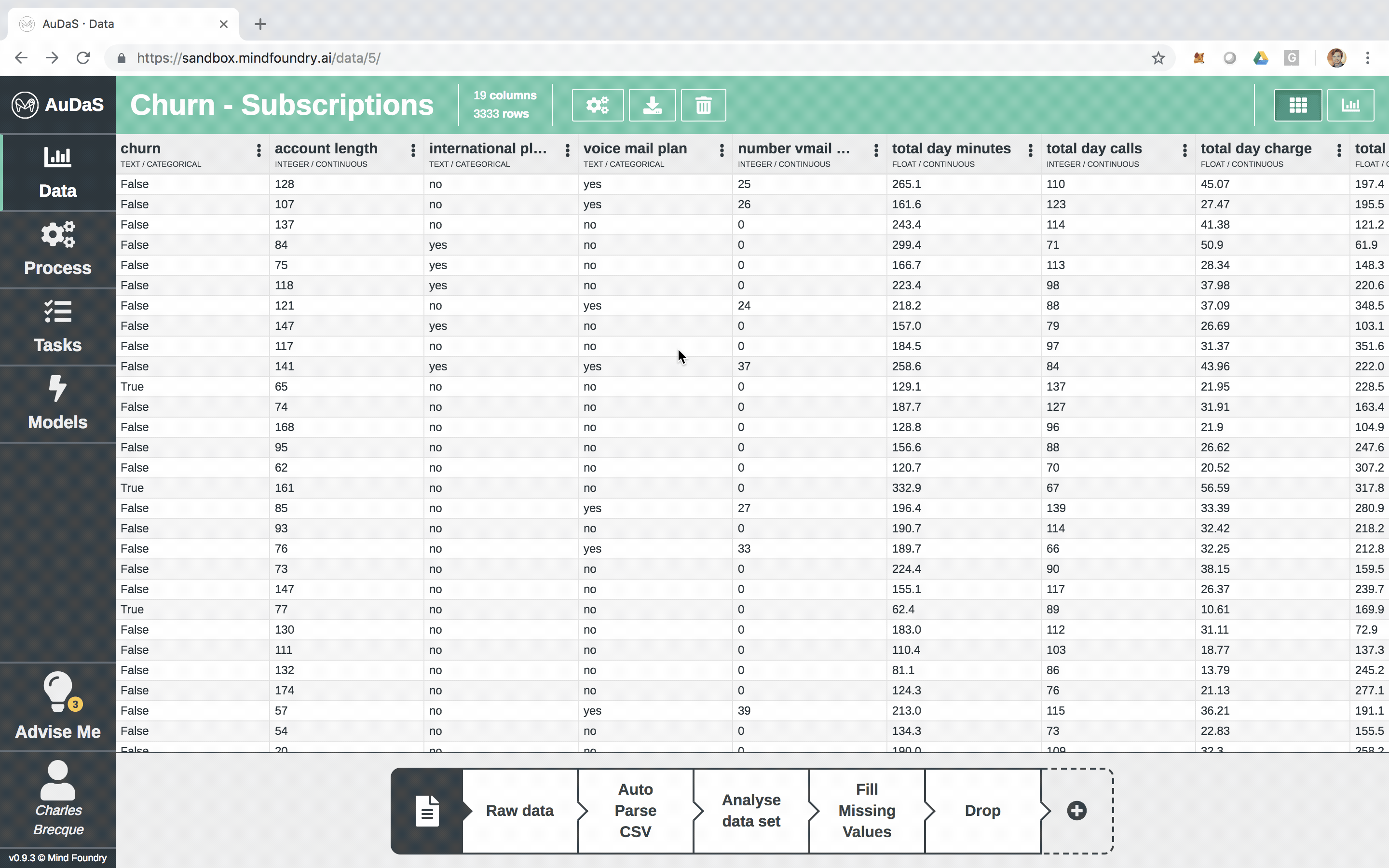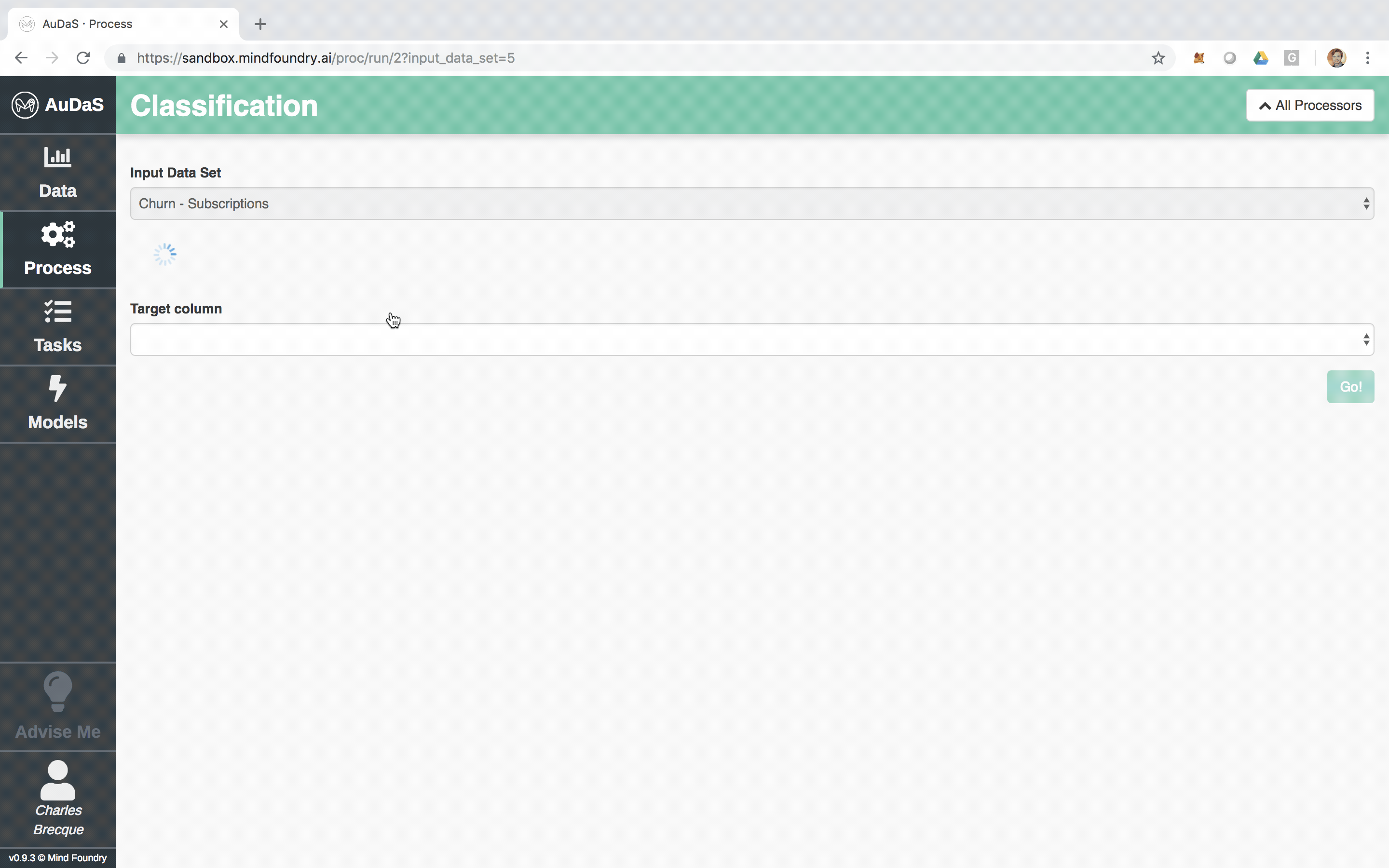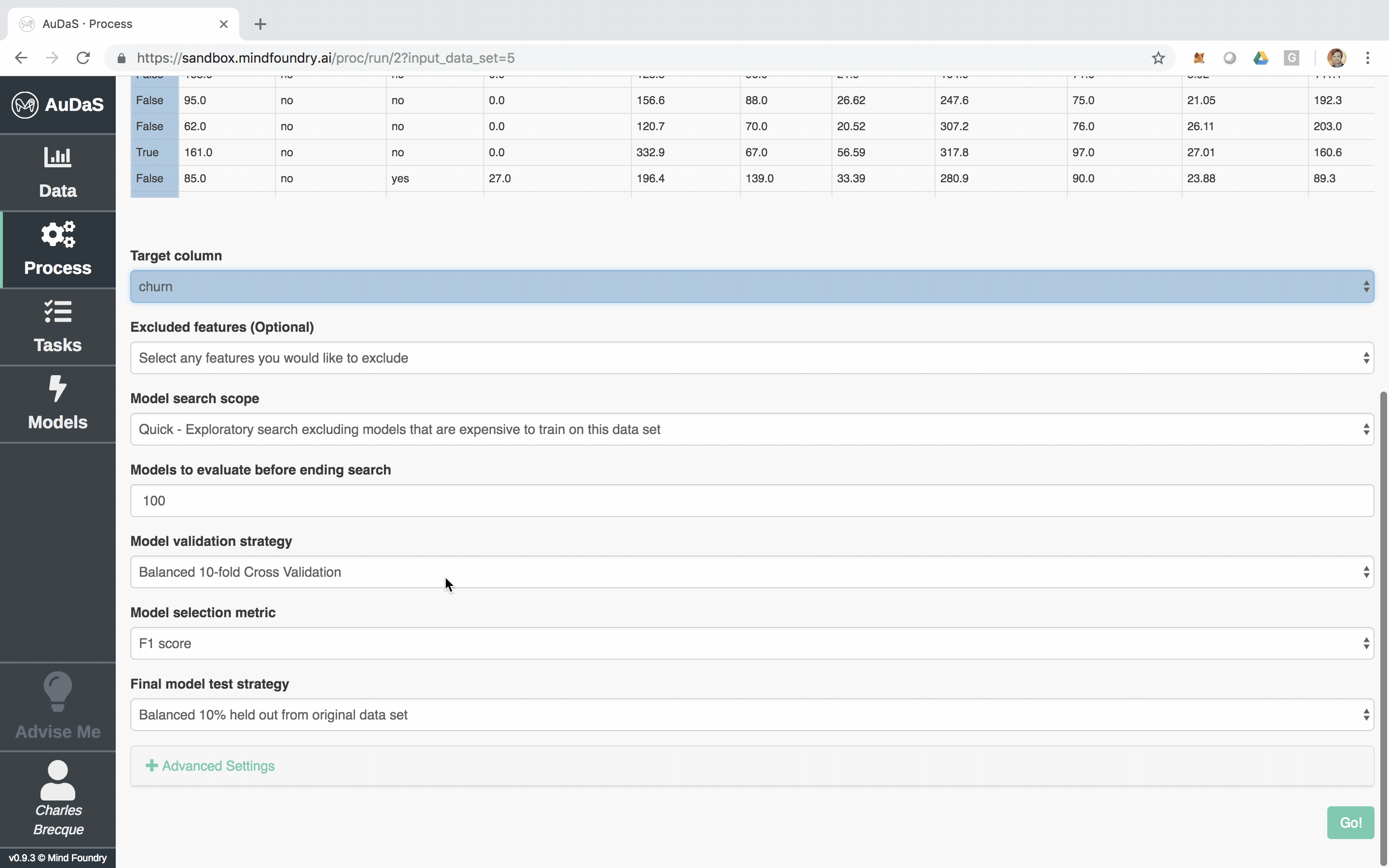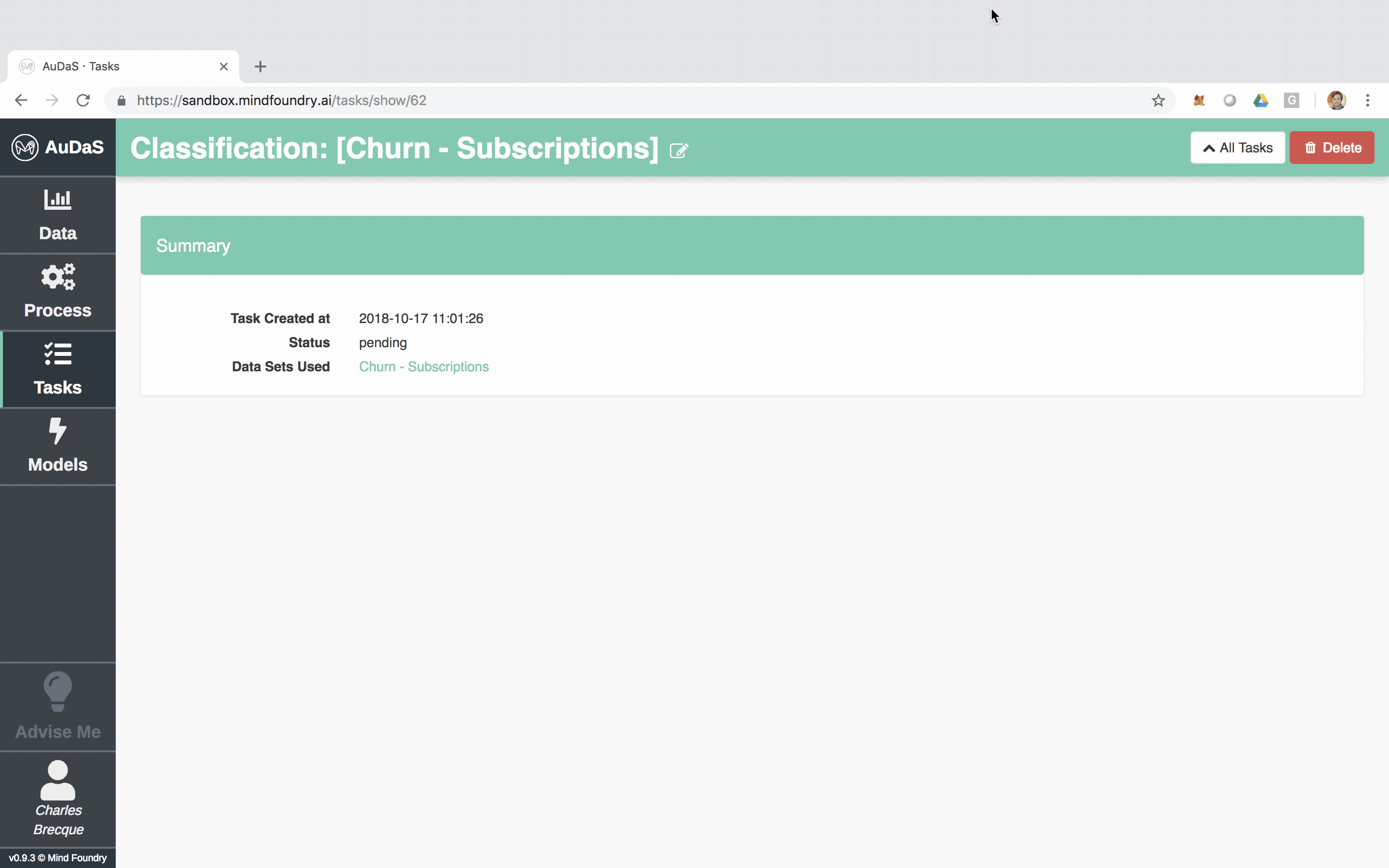
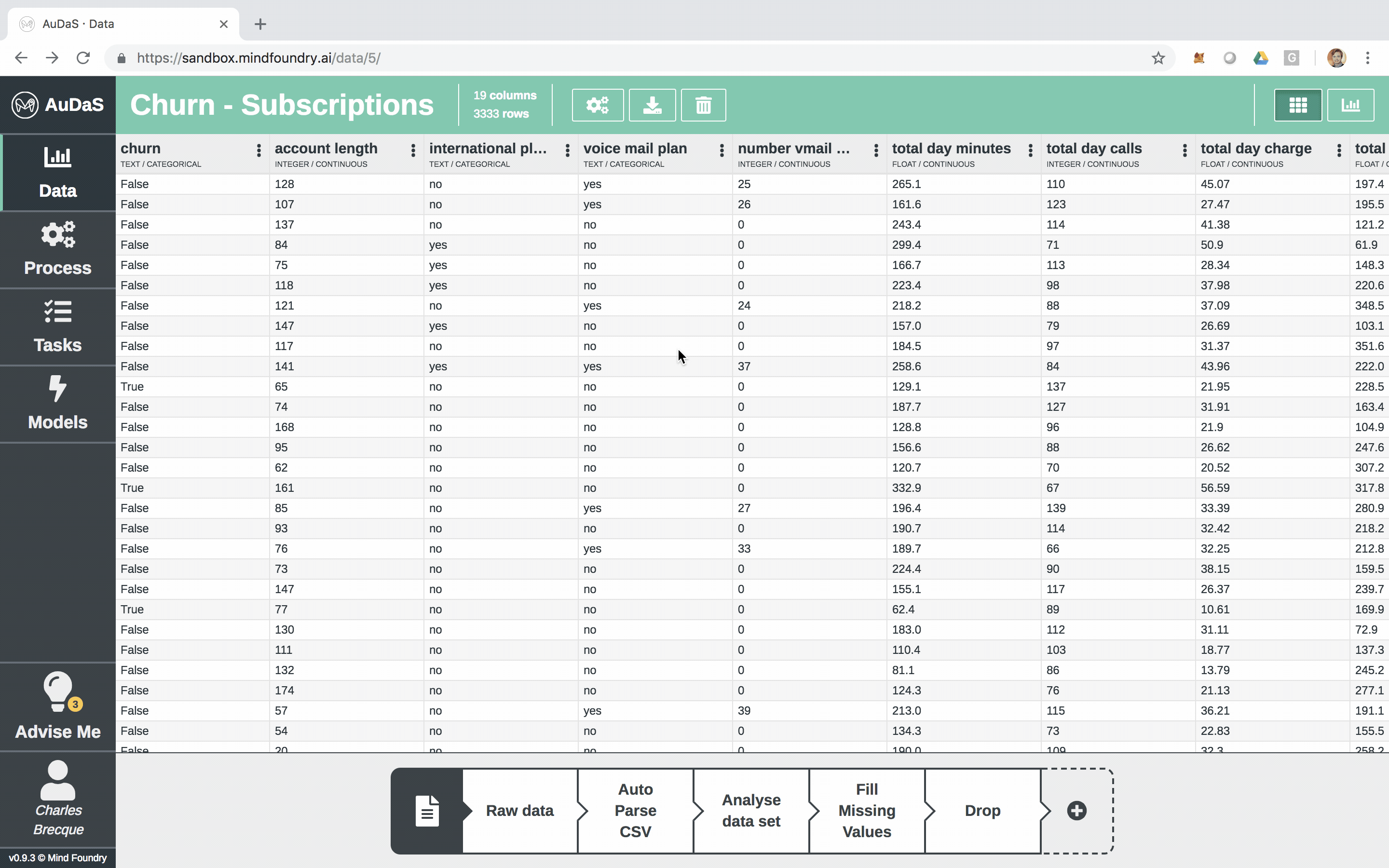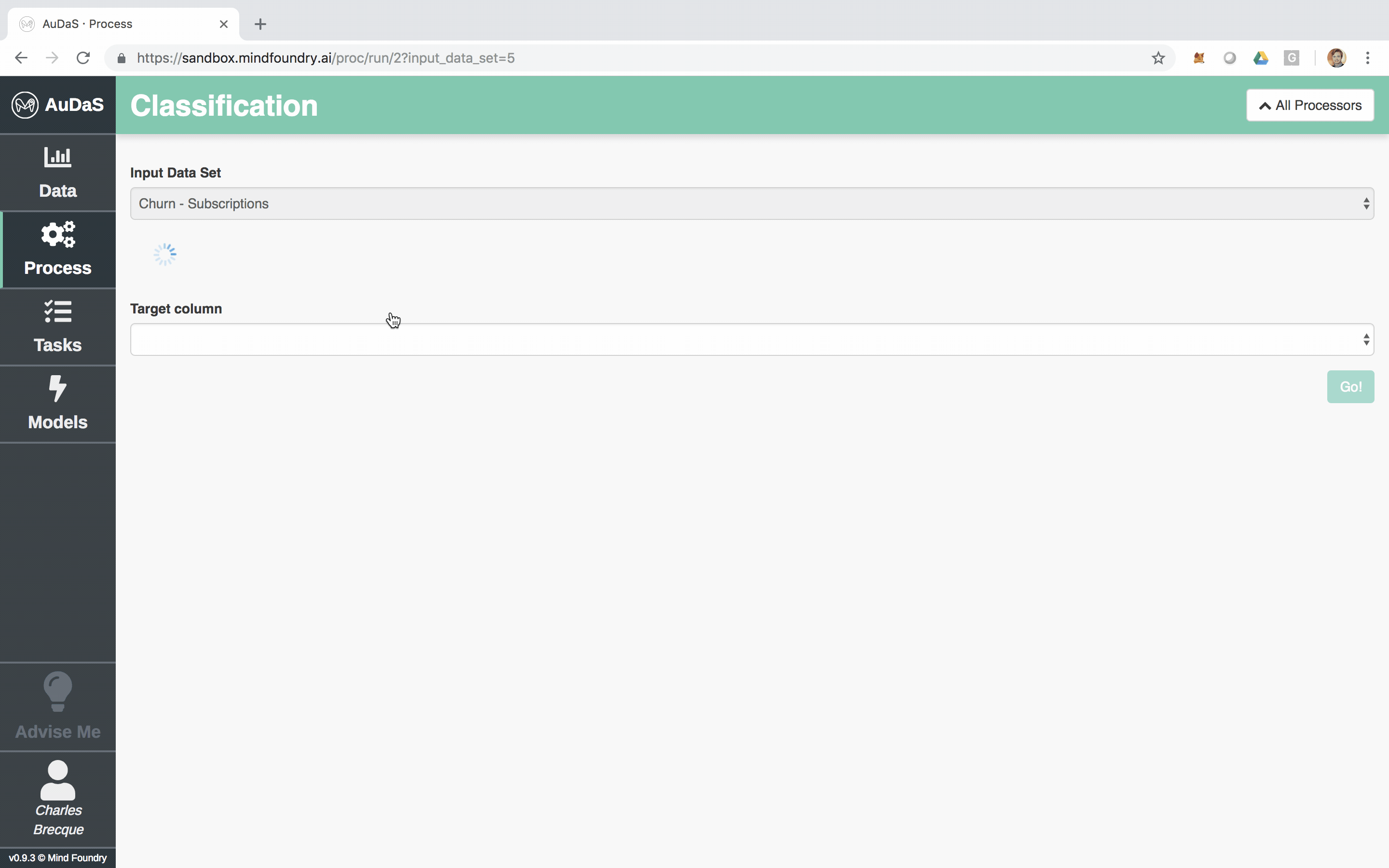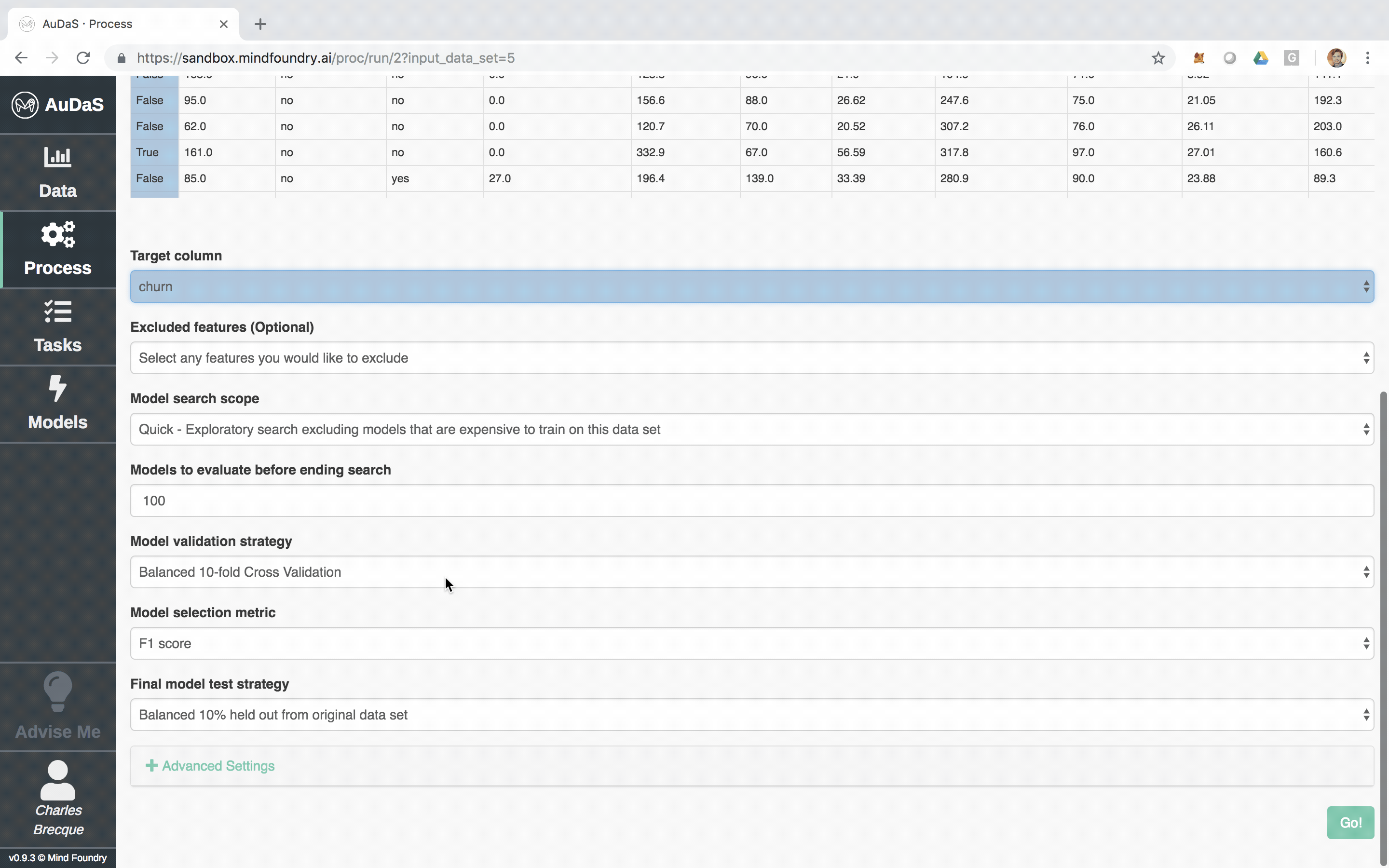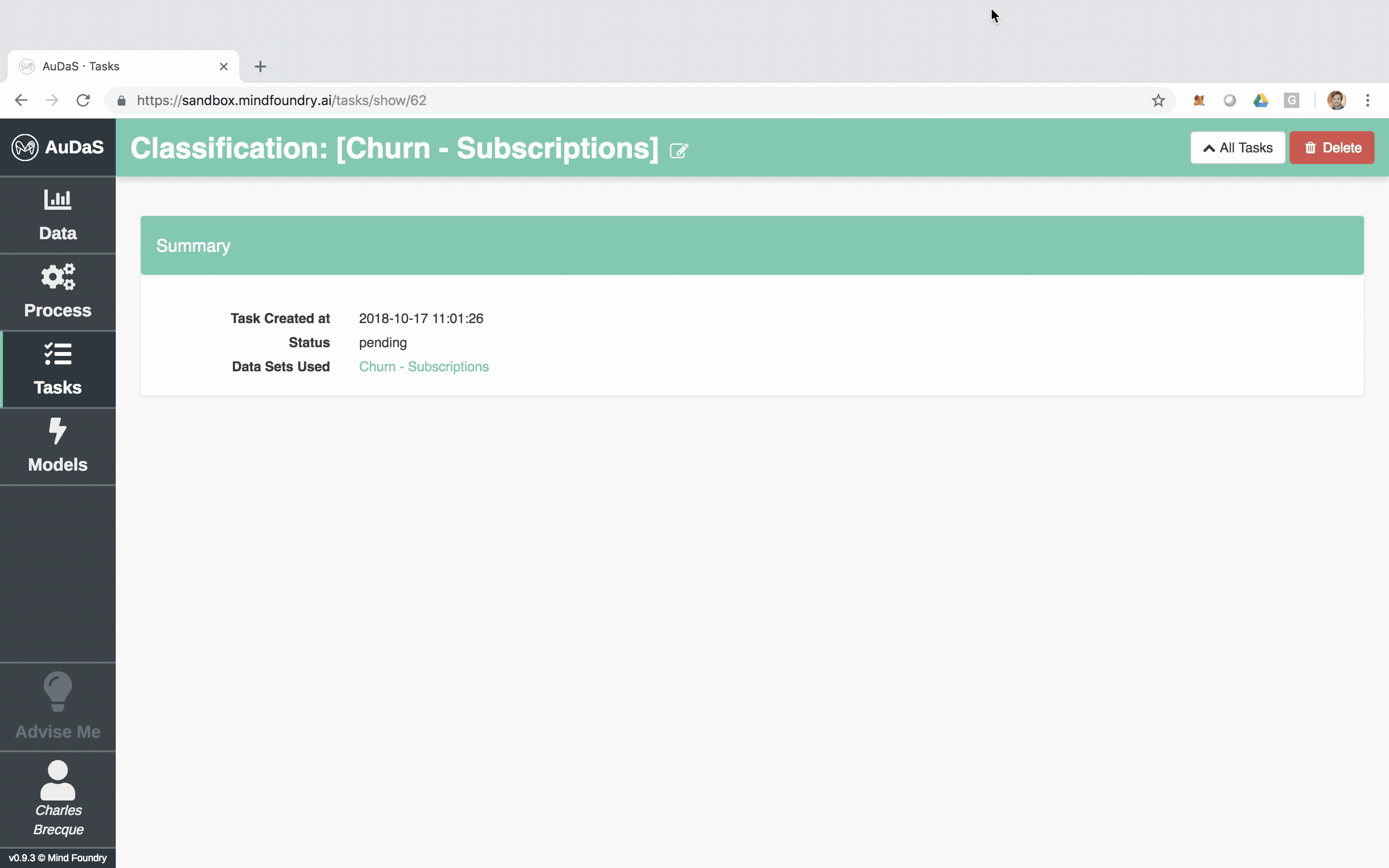
First we are going to load the data into AuDaS which in this case is a simple csv with 21 columns and 3333 rows:
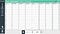
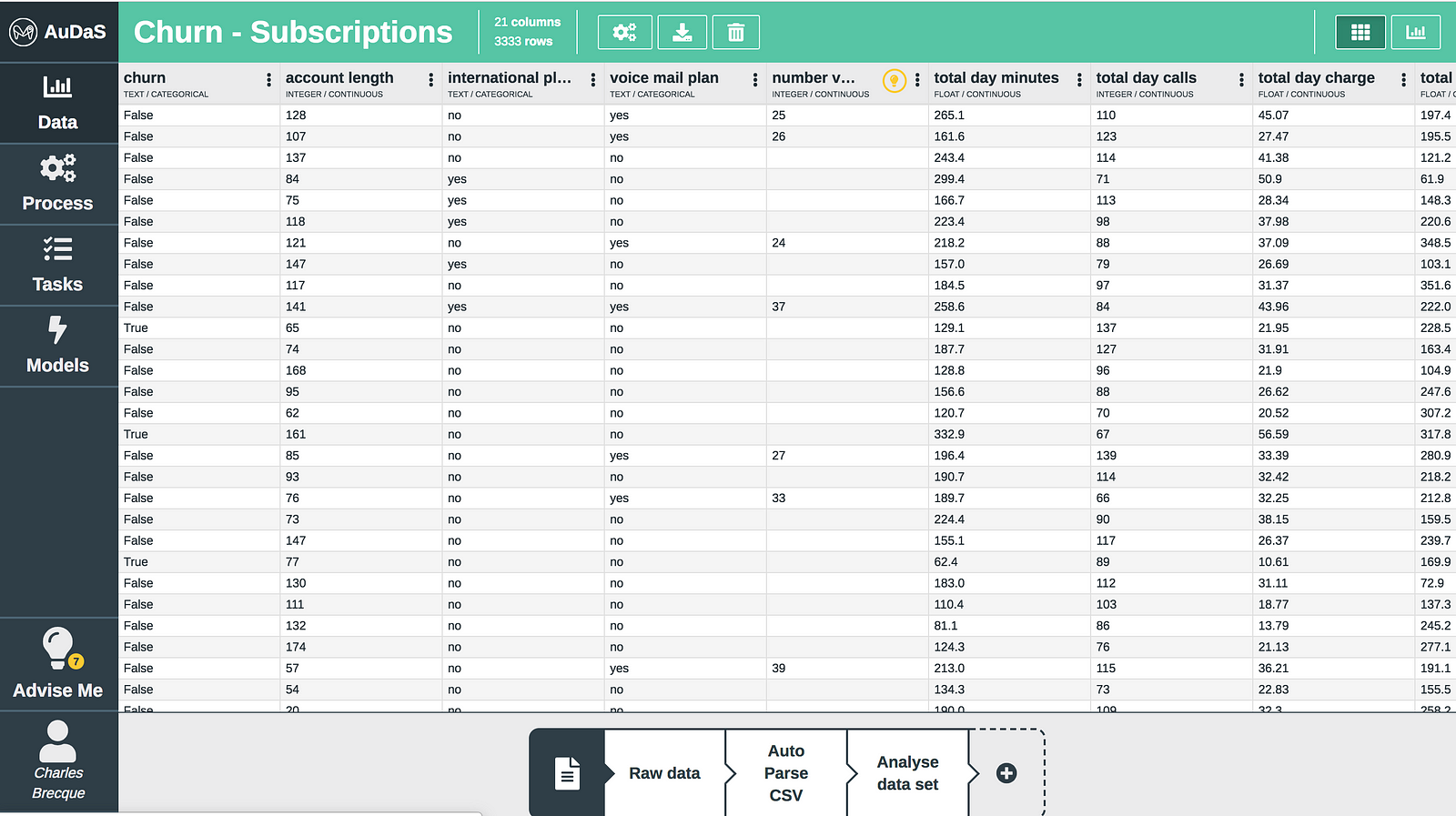
Each row represents a customer and each column an attribute which includes the number of voice mails, total minutes (day/night), total calls (day/night), etc.
AuDaS automatically scans the data, detects the type of each column and provides data preparation advice highlighted by the light bulbs. This is where the Business Analyst of Data Scientist can introduce their domain knowledge by acting on the relevant advice with the appropriate answers.

In this case, we know that the missing values in “number voice mail messages” column should actually be filled in with 0 and can be done very easily by simply clicking:

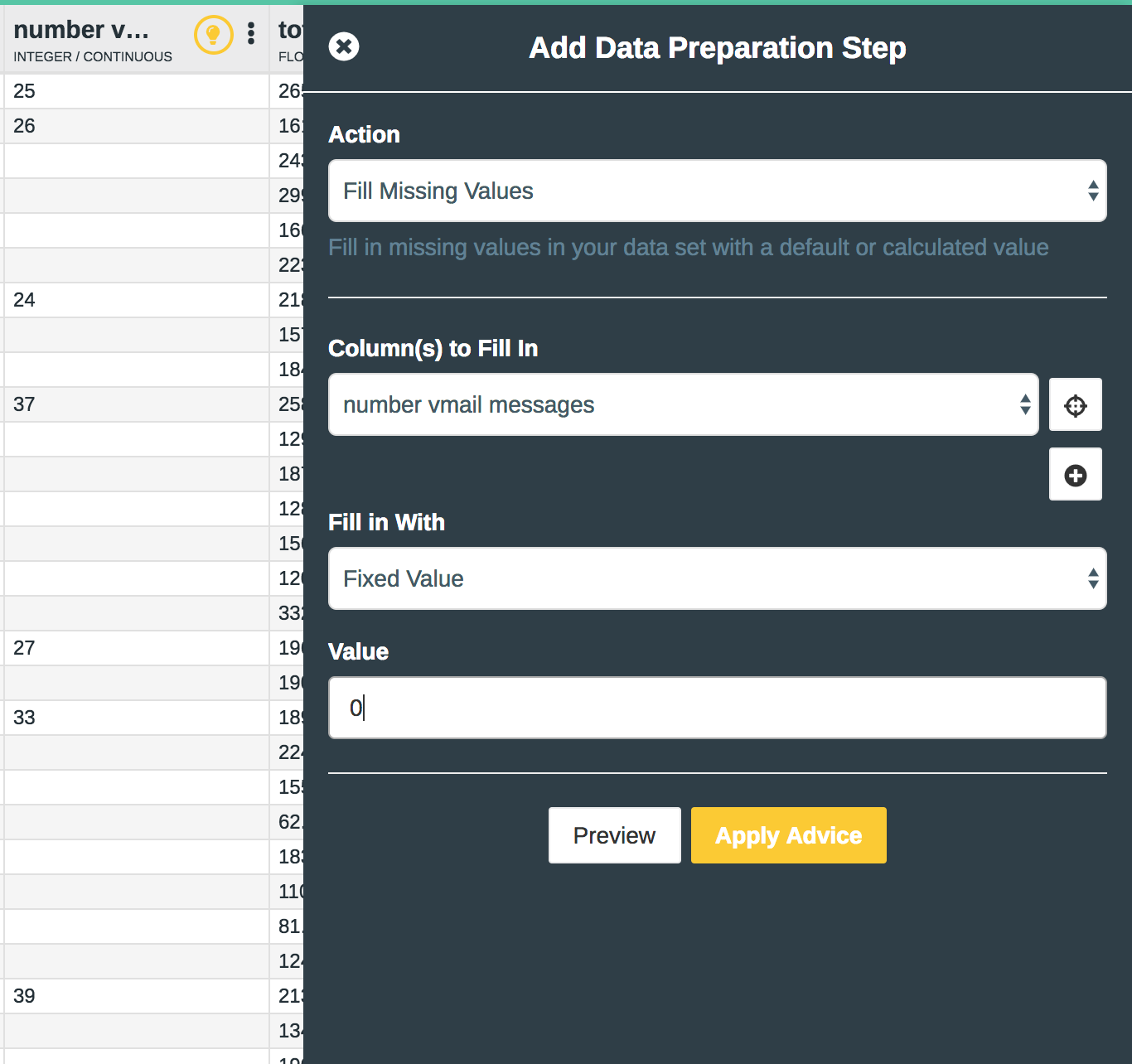
Once we have done this as well as dropped the Customer id and phone numbers which don’t contain any predictive power, we are able to get a full audit trail of all the data preparation steps. We can also easily revert to pre-prepared versions of the data if we wish to do so.


AuDaS also automatically generates nice visualisations of the data for you.
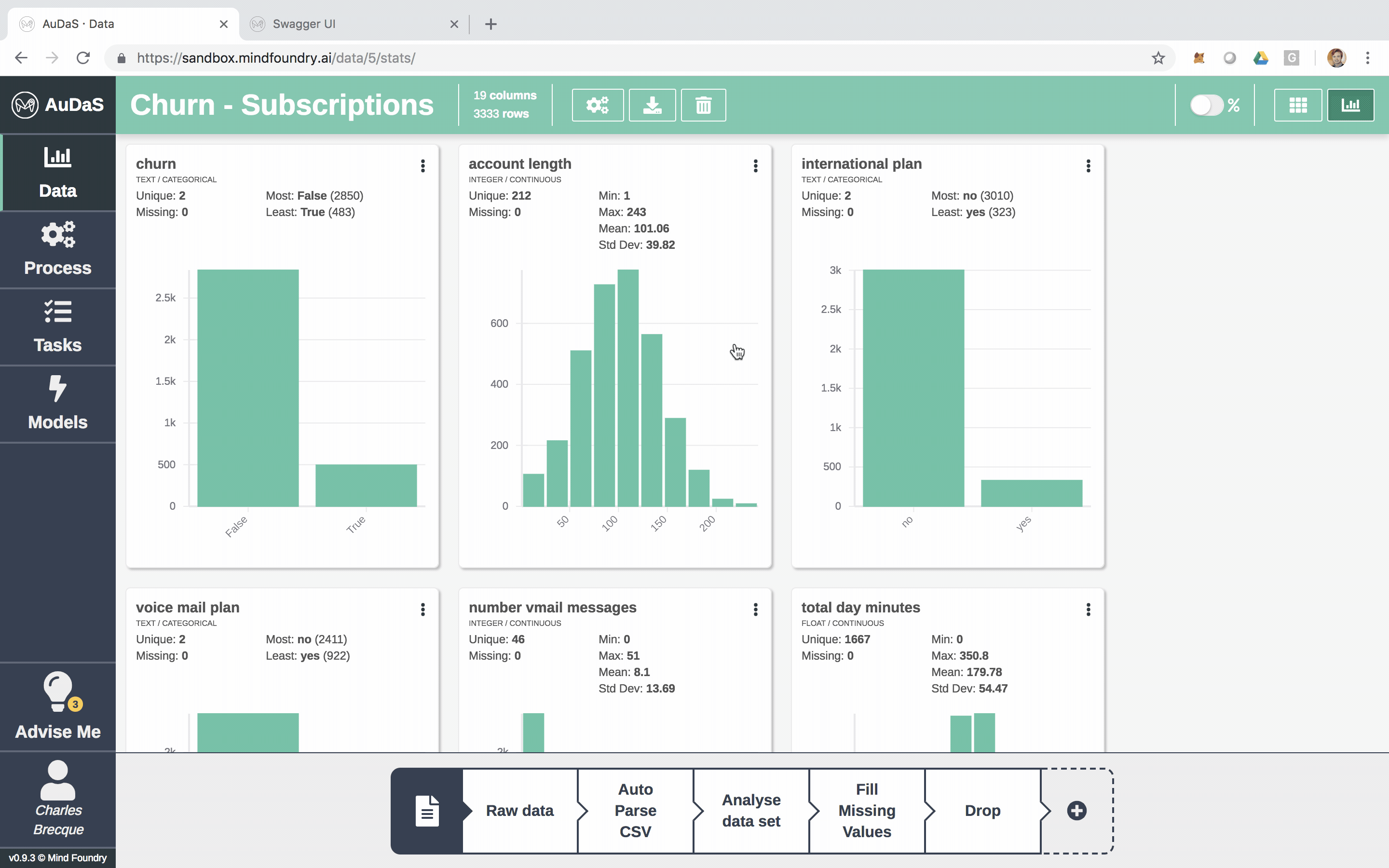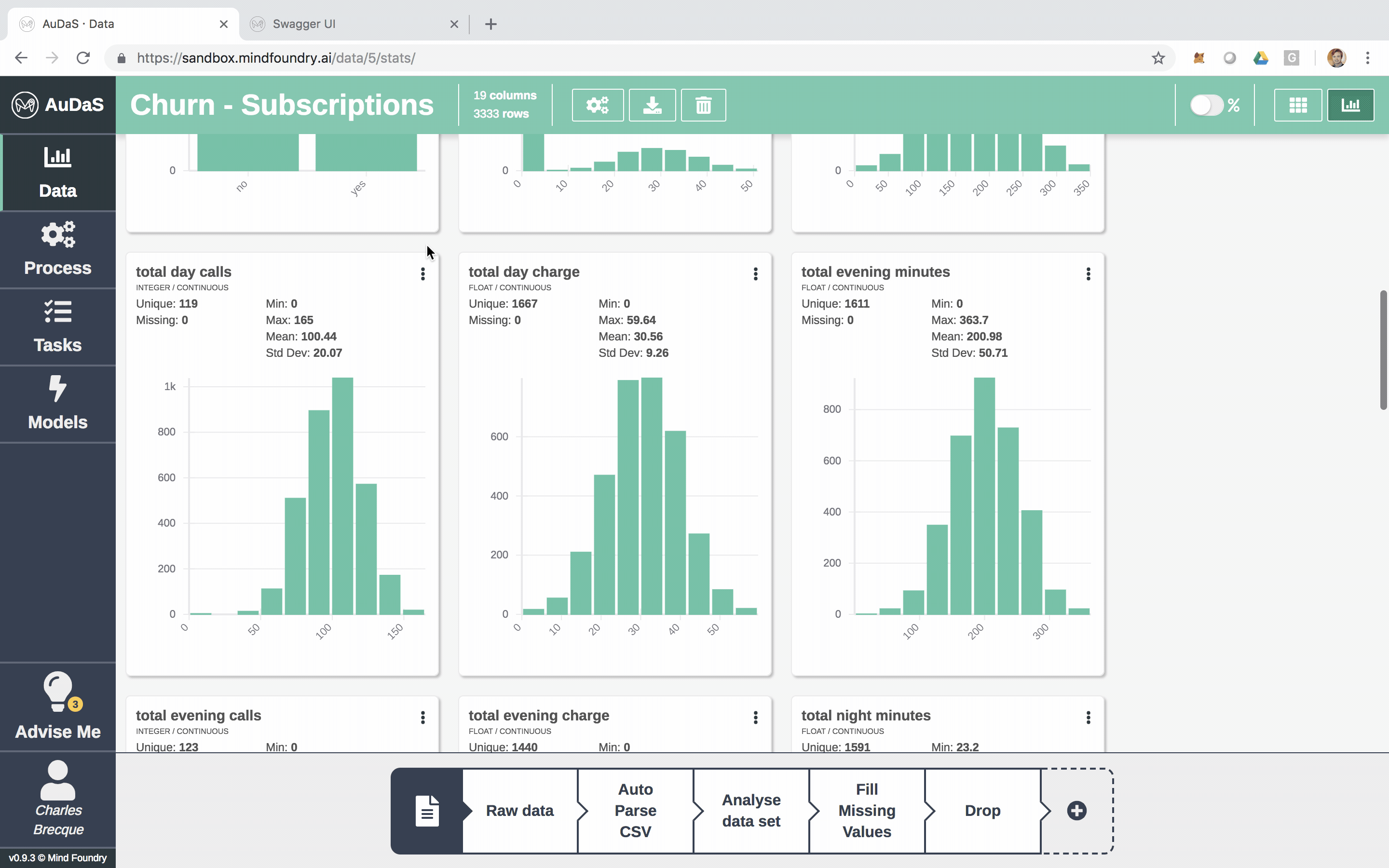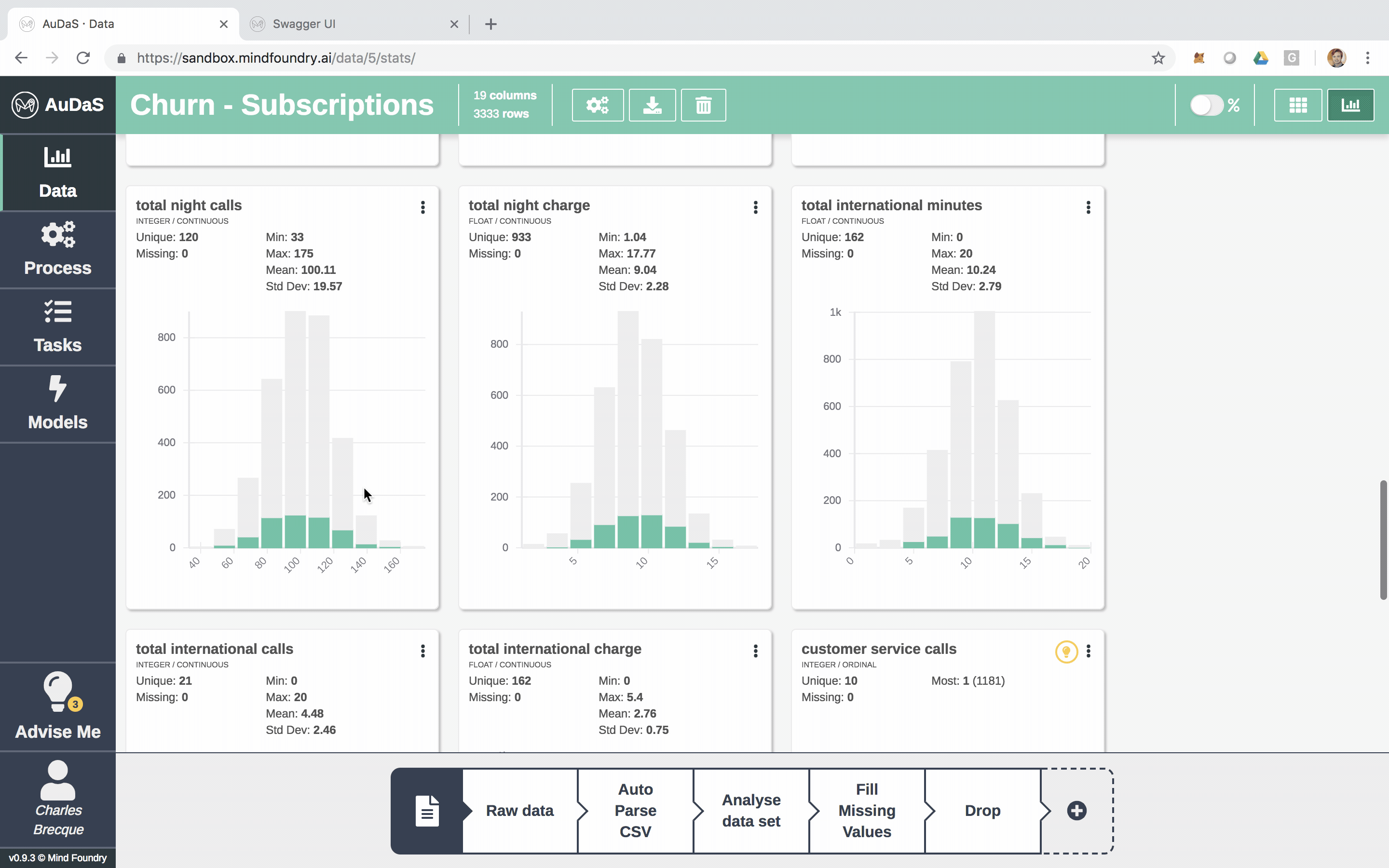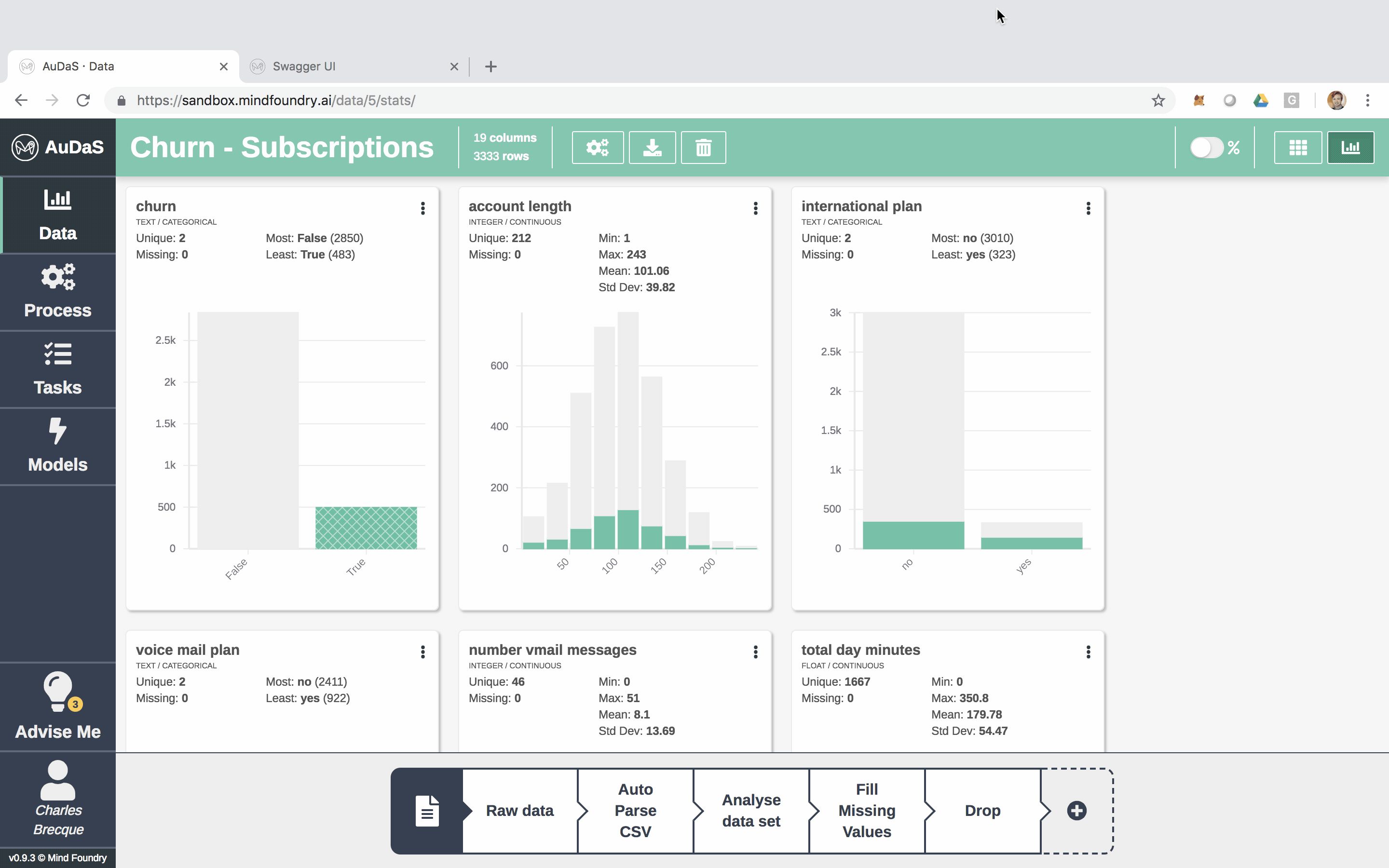
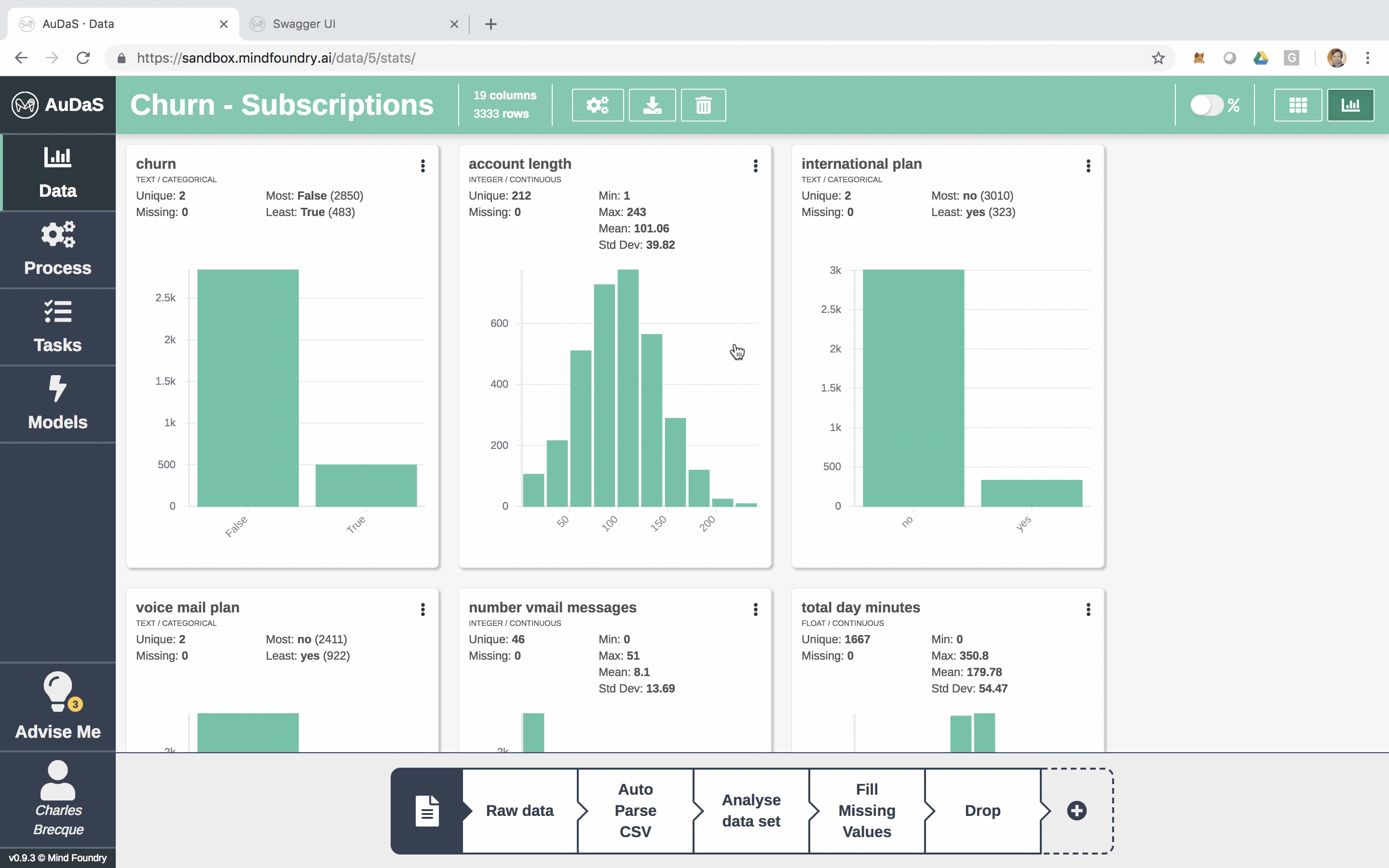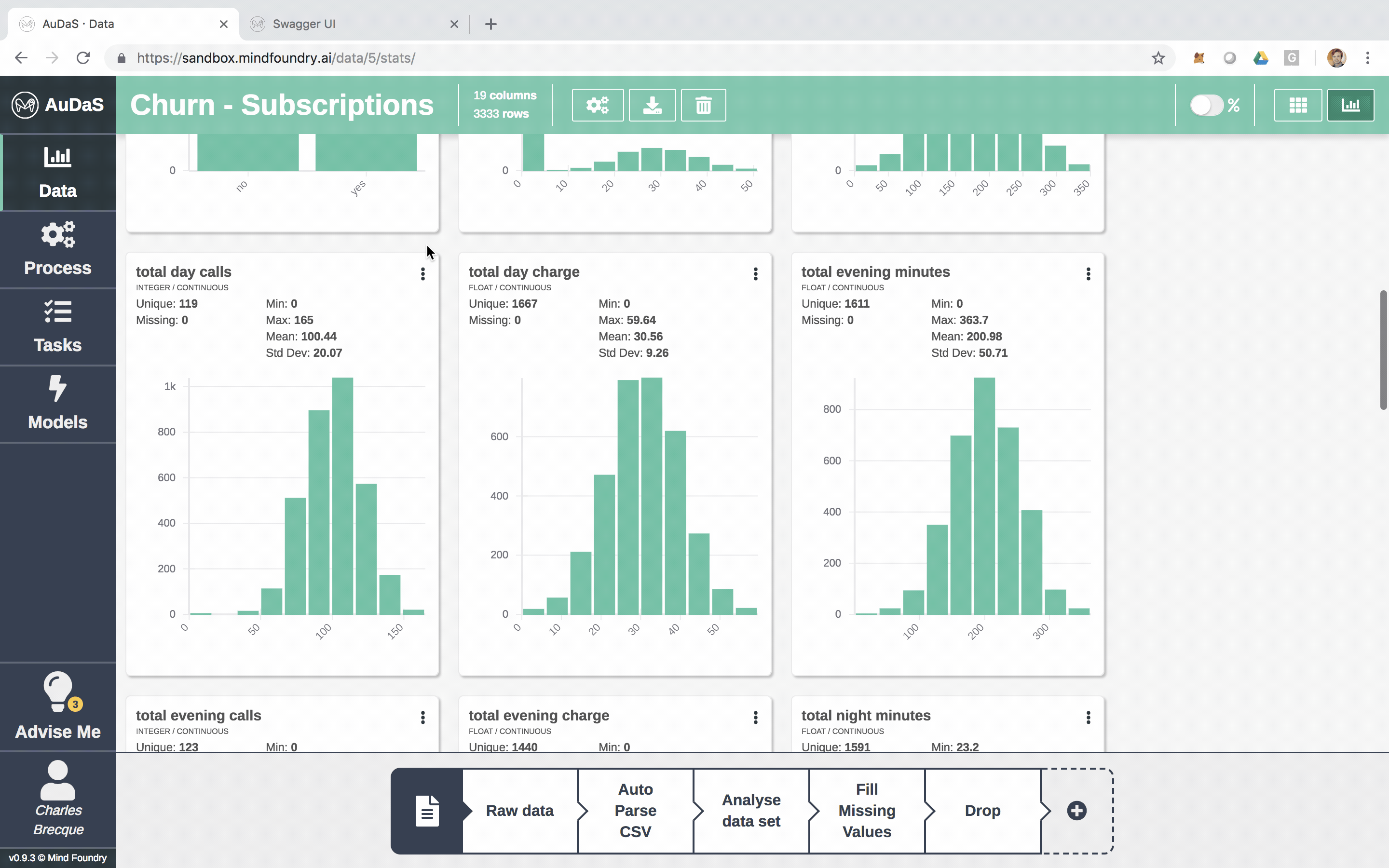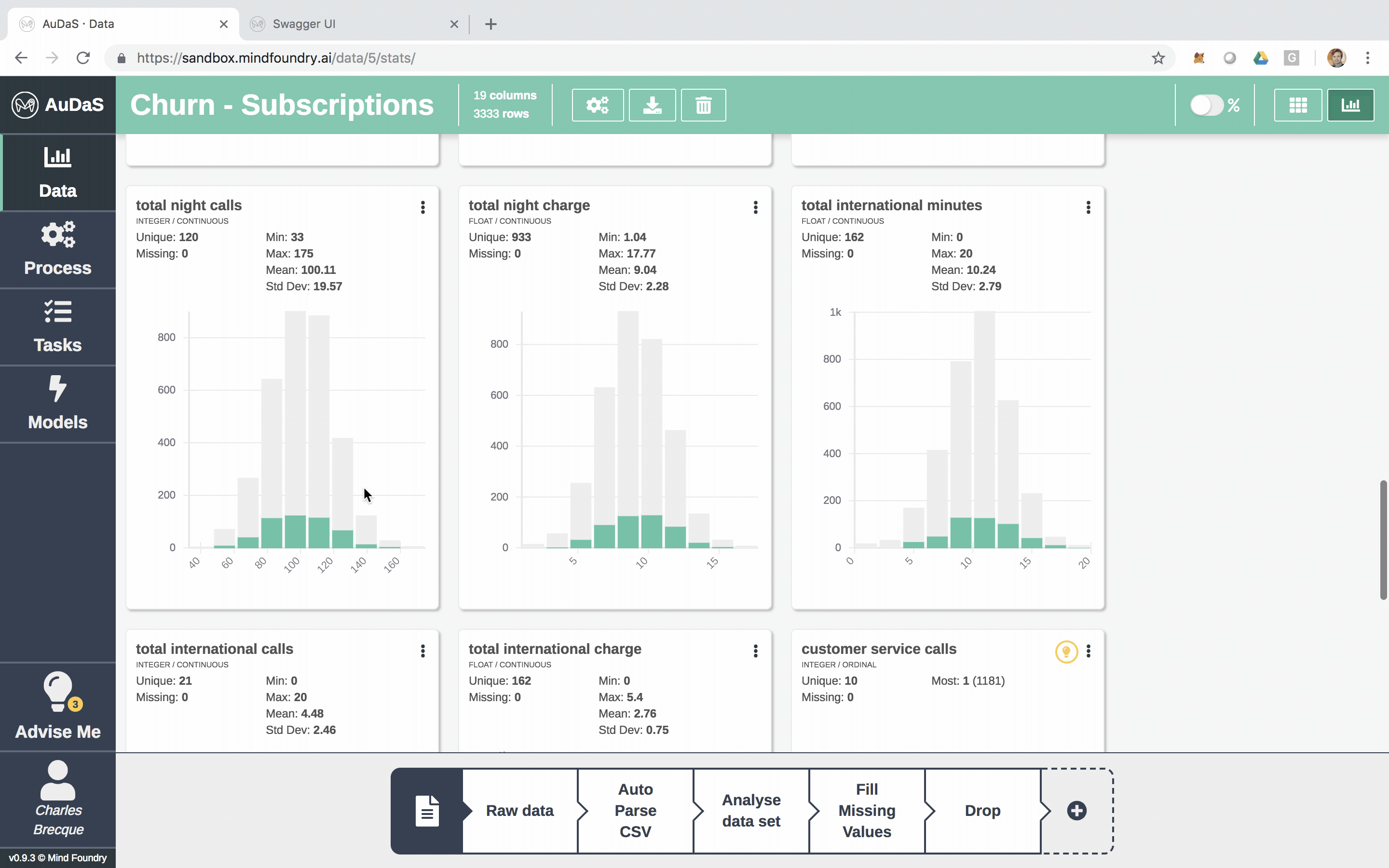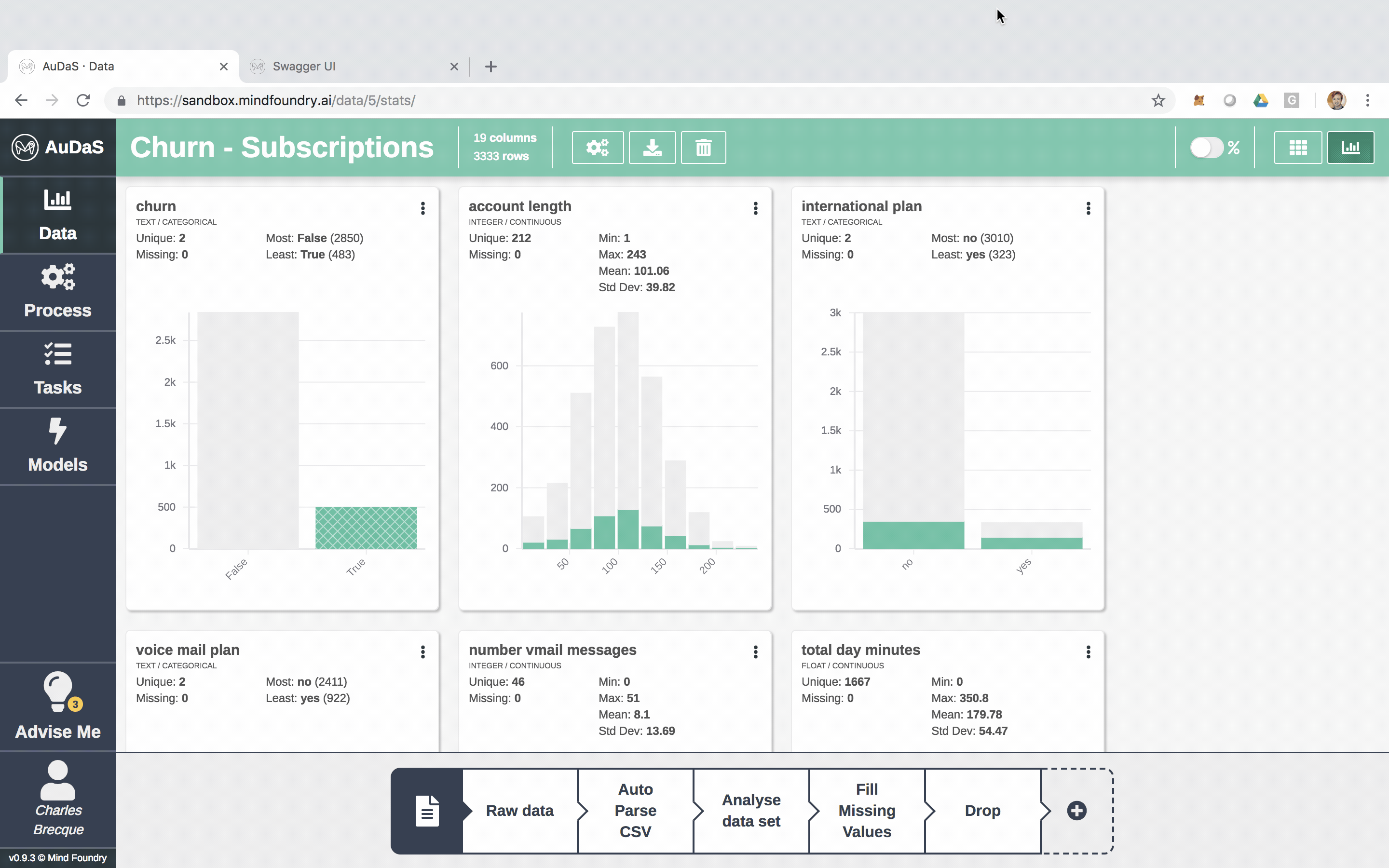
You can also enrich the data set by joining other data sets (if applicable). AuDaS supports all the other data preparation steps you would normally do. Now that we are happy with the data we are going to build our Classification pipeline.
Processing the data
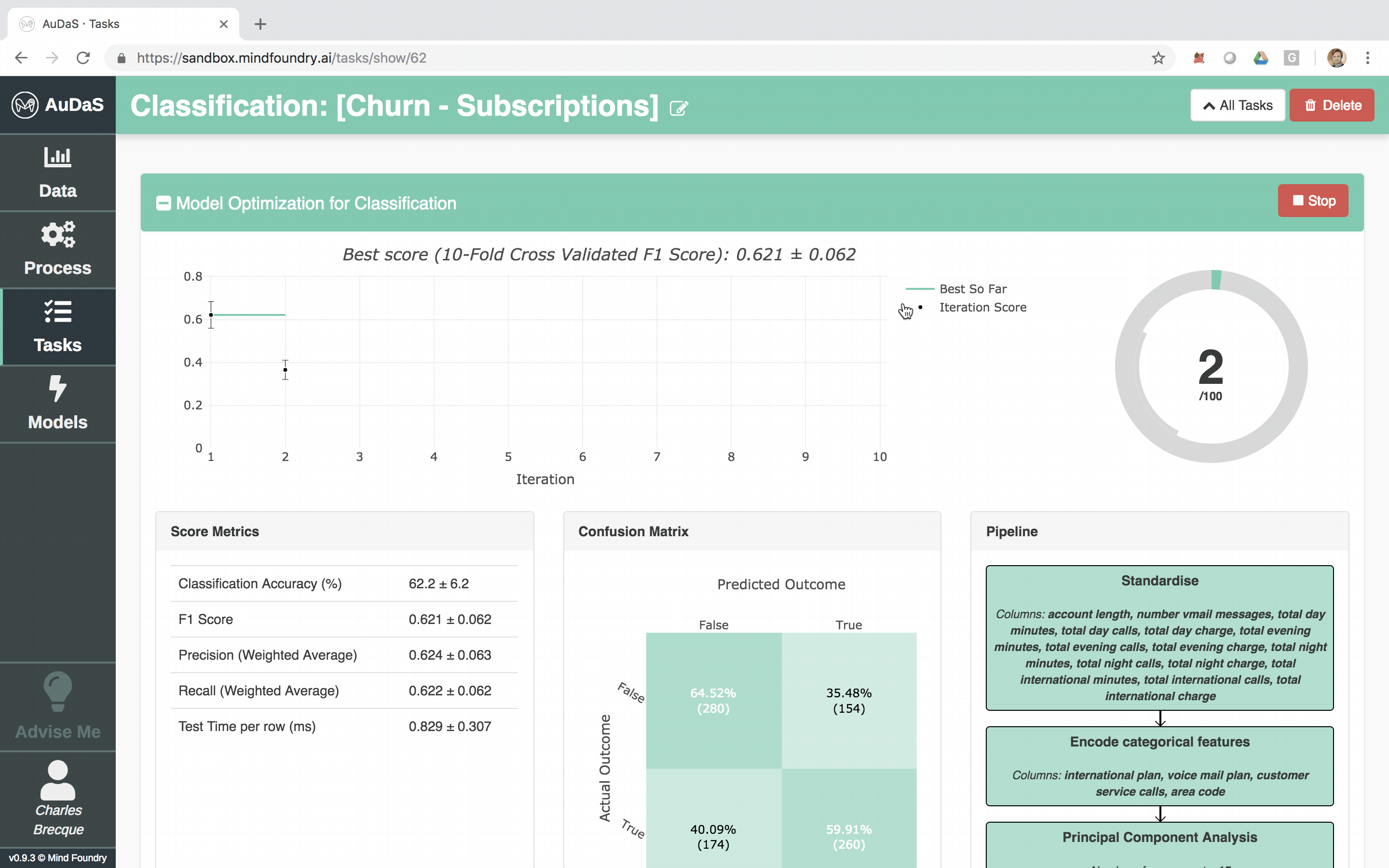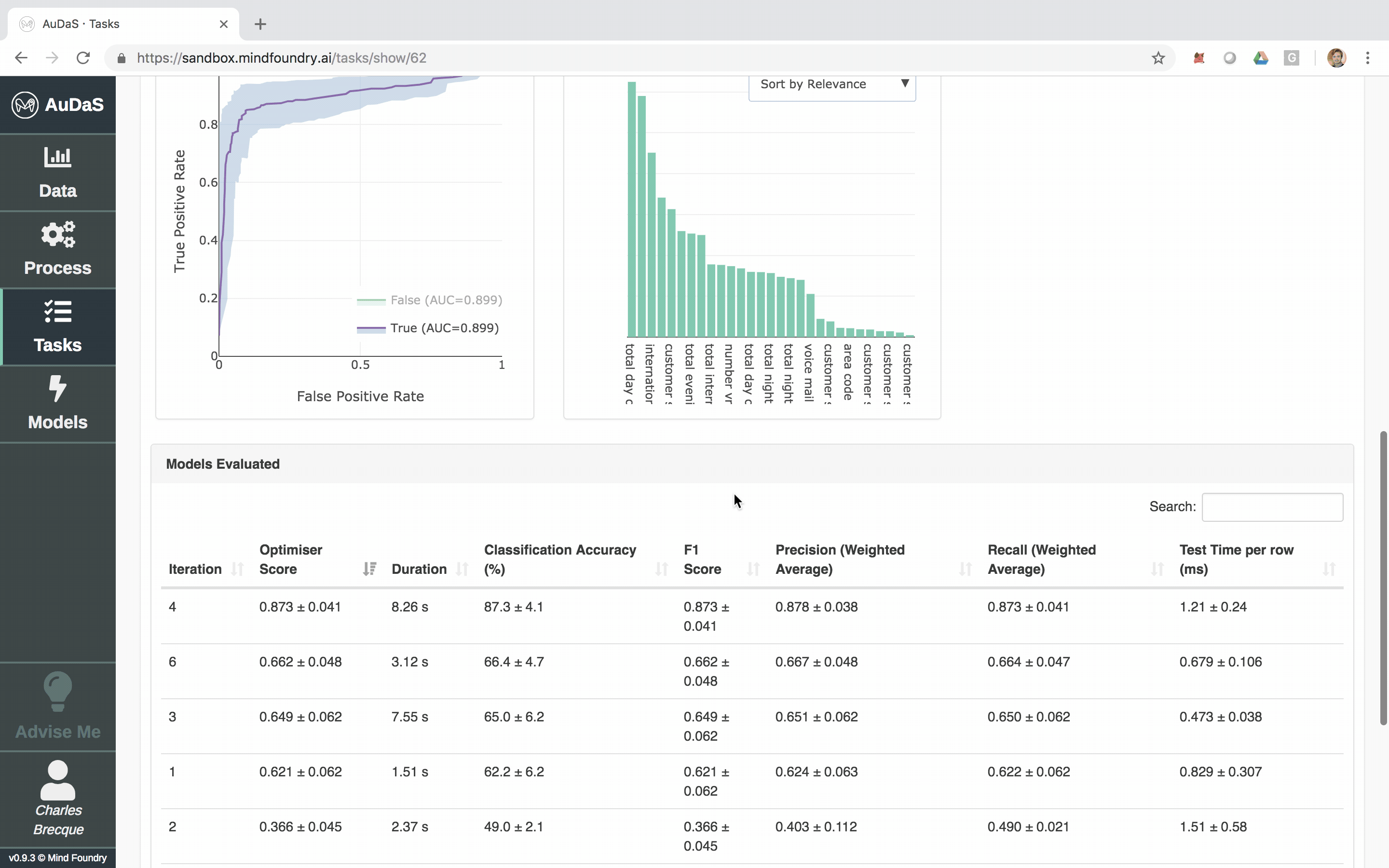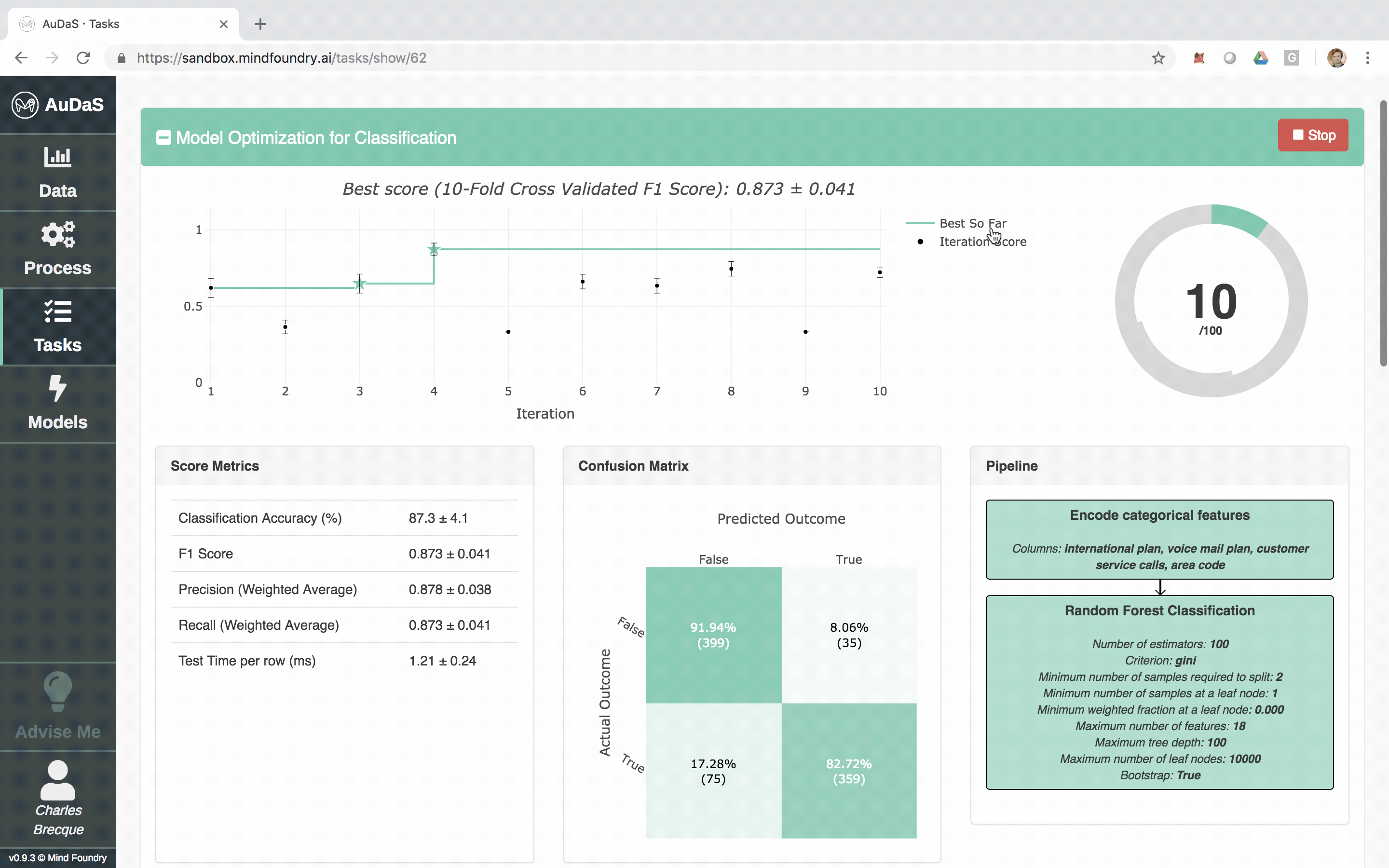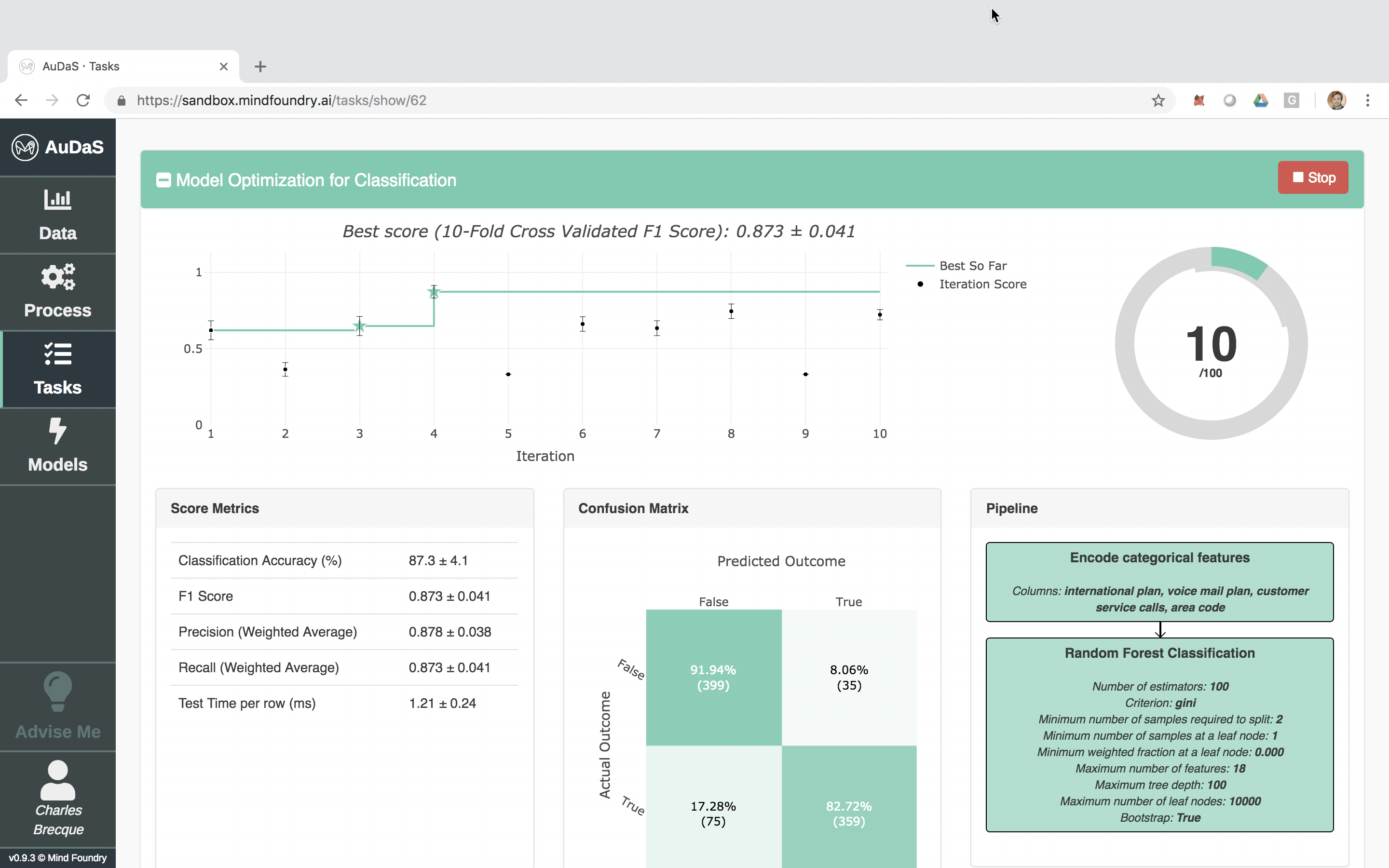
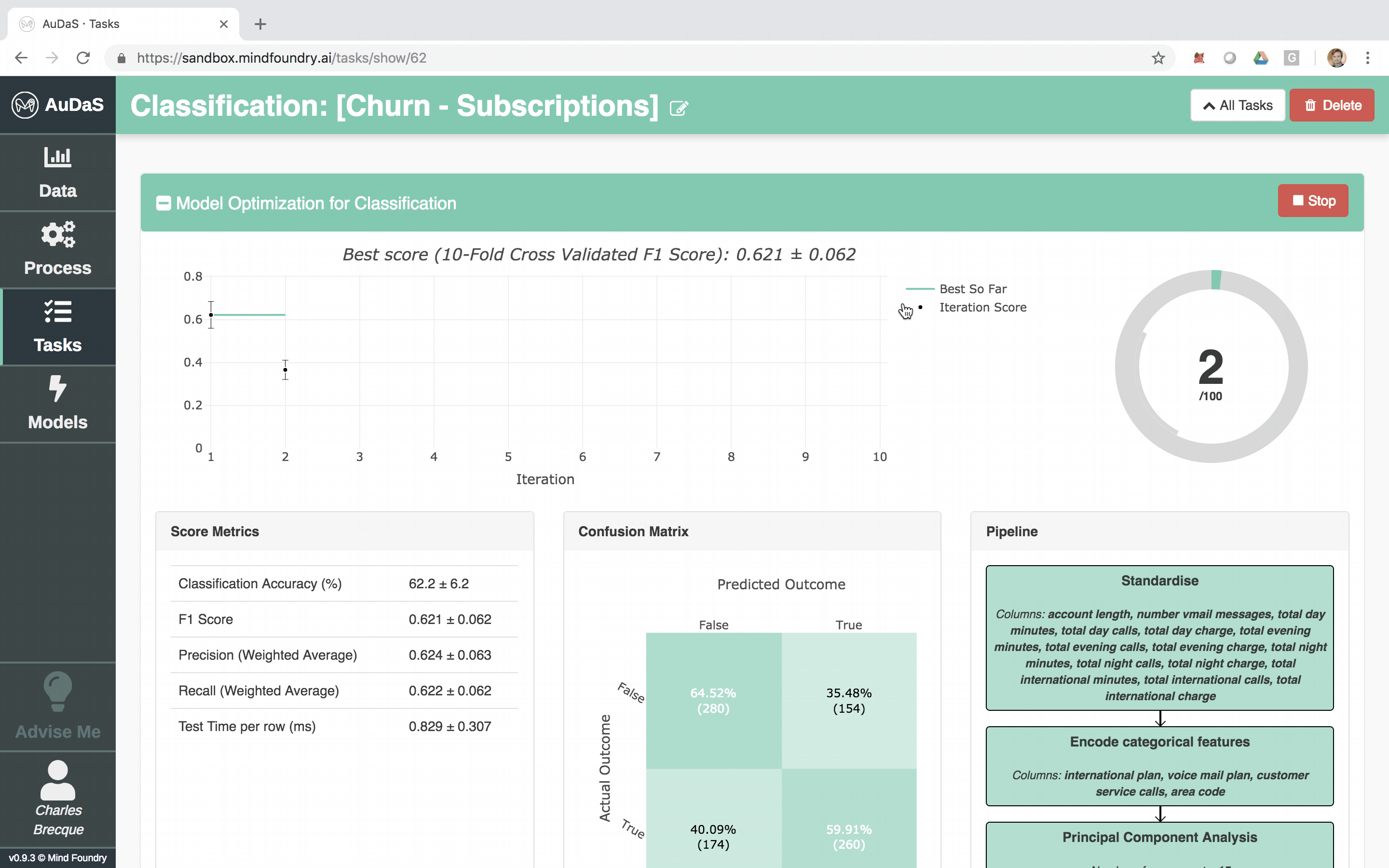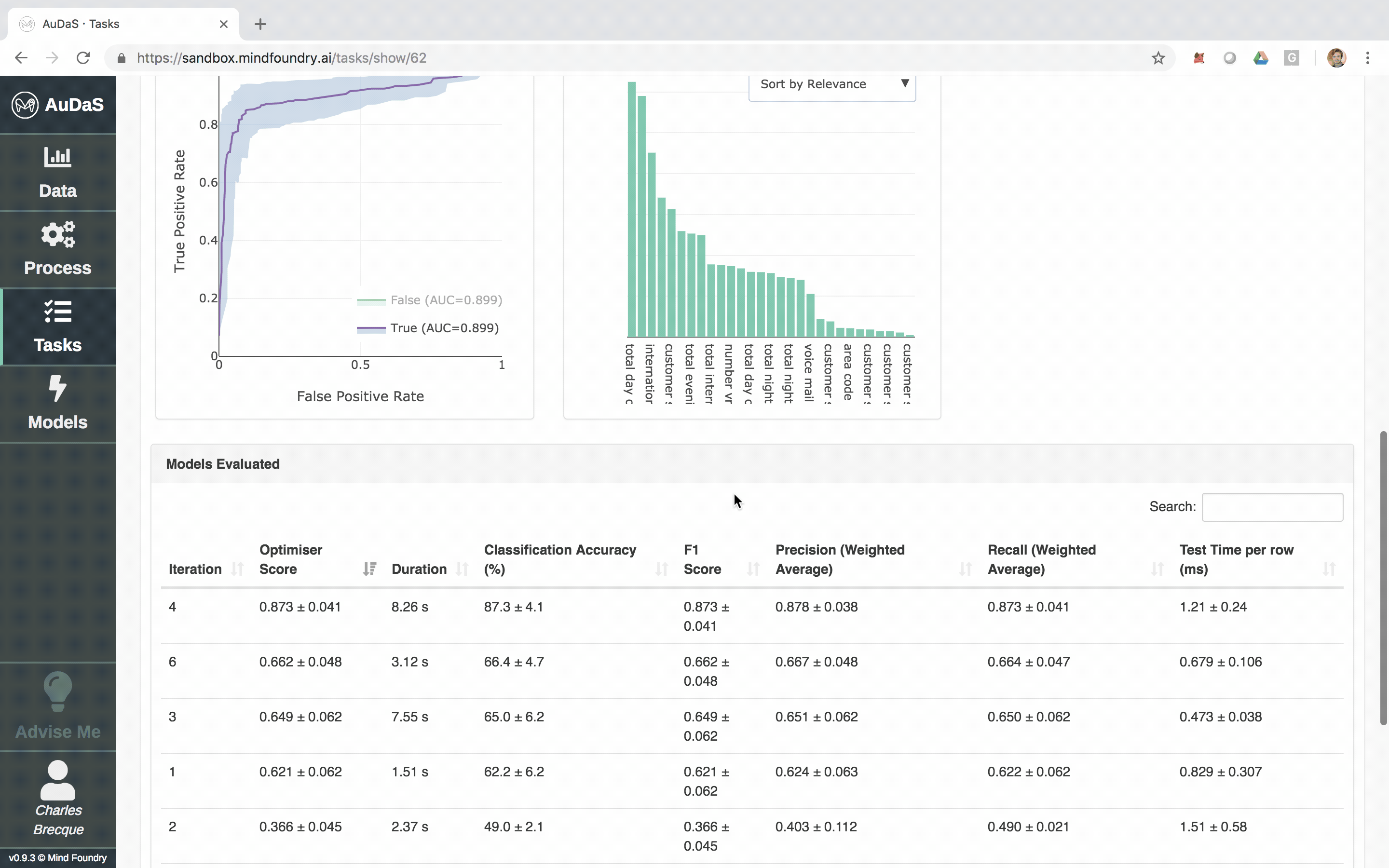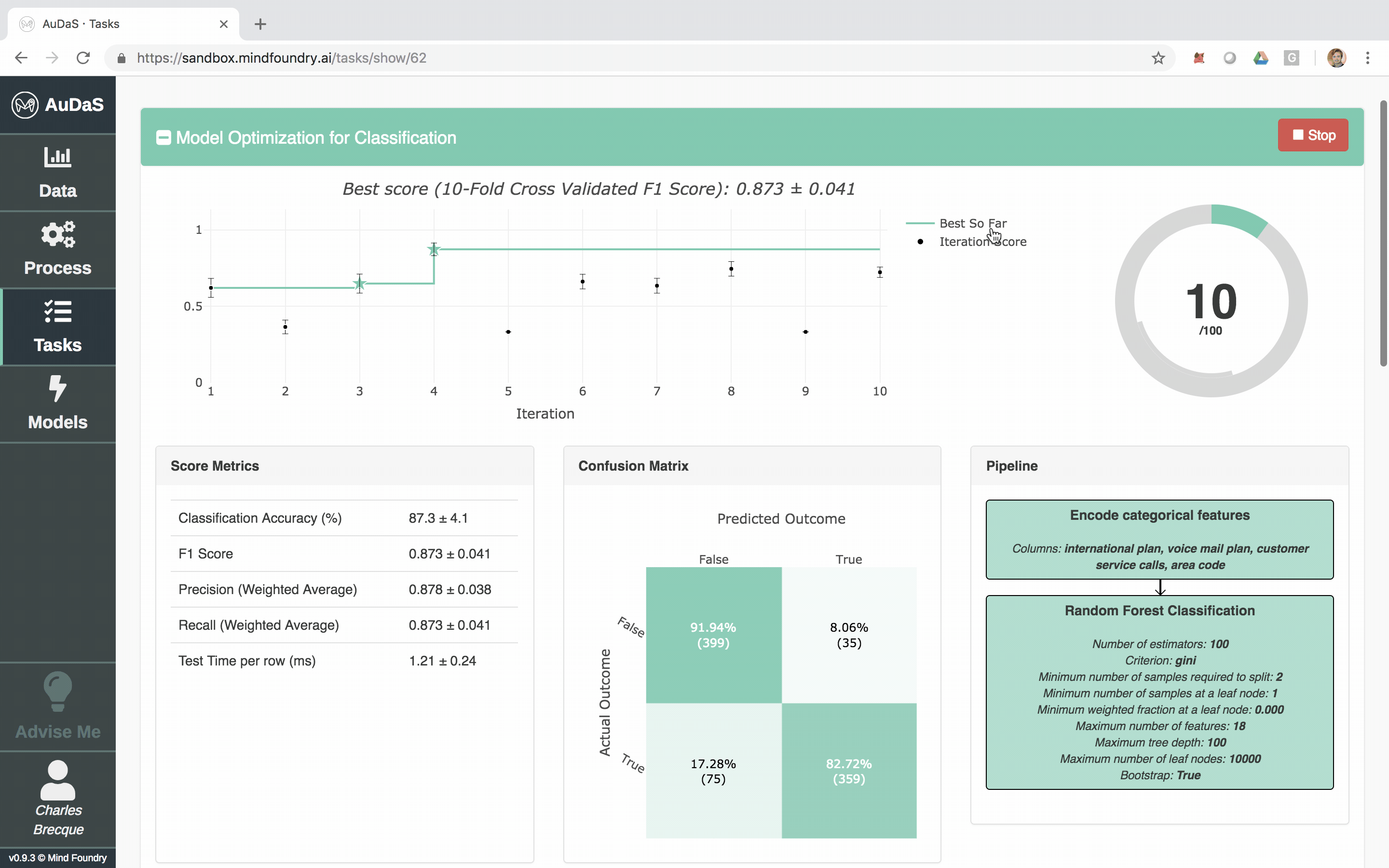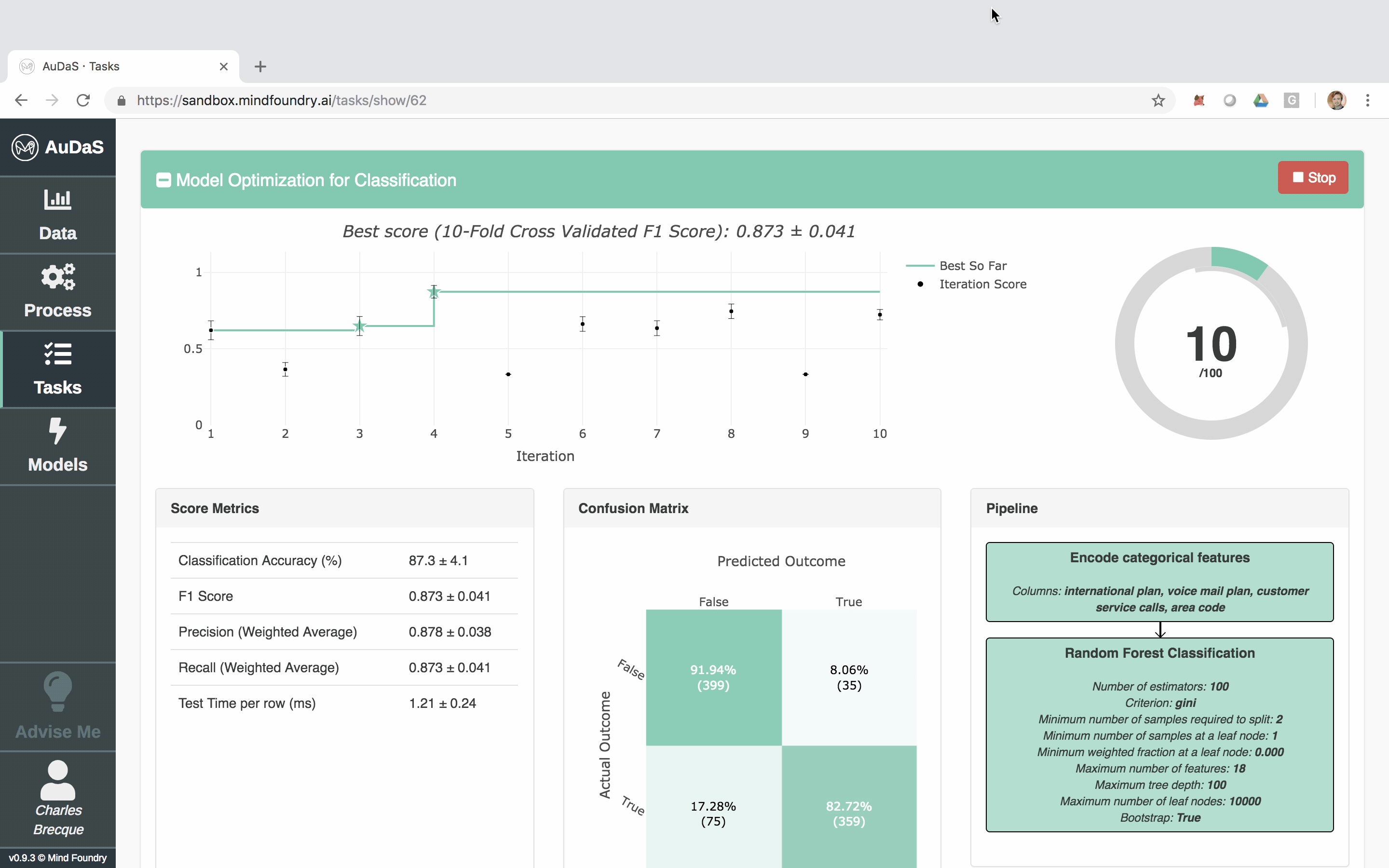
AuDaS allows you to quickly set up your classification process for which you only need to select the target column and specify the model validation framework and scoring metrics.
AuDaS then launches and searches the solution space of possible pipelines (feature engineering and machine learning models) and their associated hyper-parameters using OPTaaS, our Bayesian Optimizer. AuDaS also keeps an audit trail of all the pipelines it has evaluated which you can query if required.
I have previously written about the intuitions and advantages of using Bayesian Optimization. OPTaaS is also available as an API and you can contact me for a key.
Deploying the solution
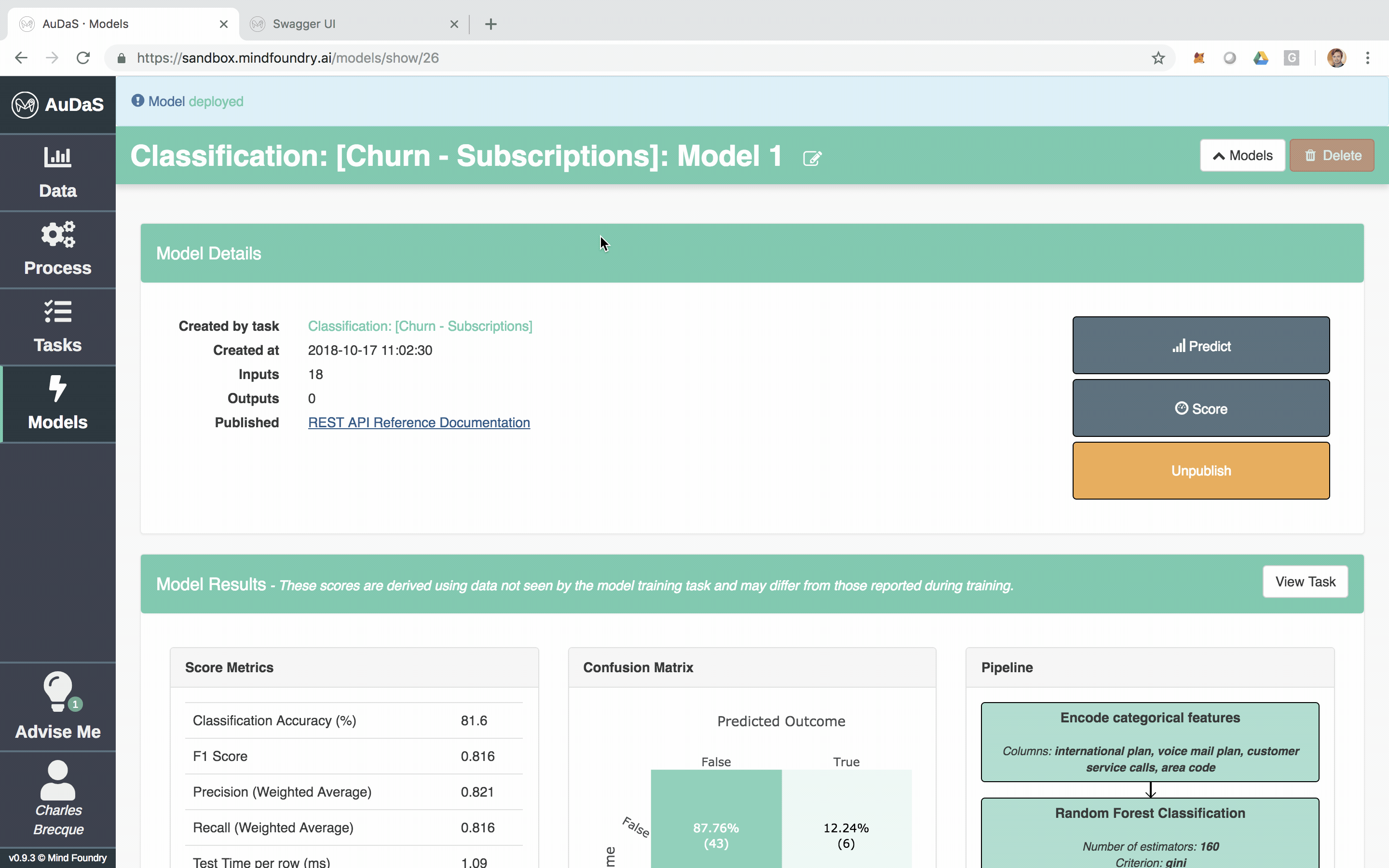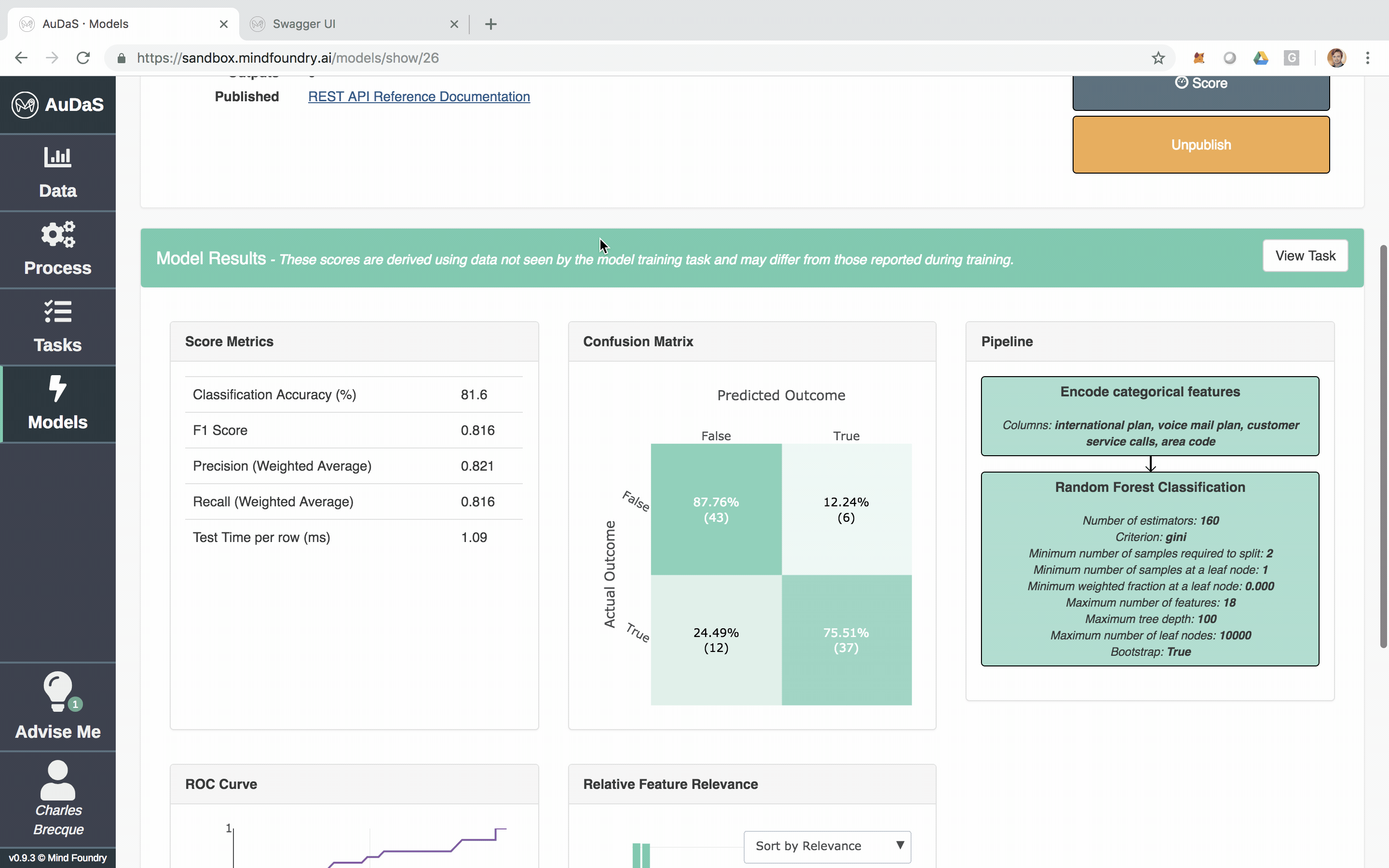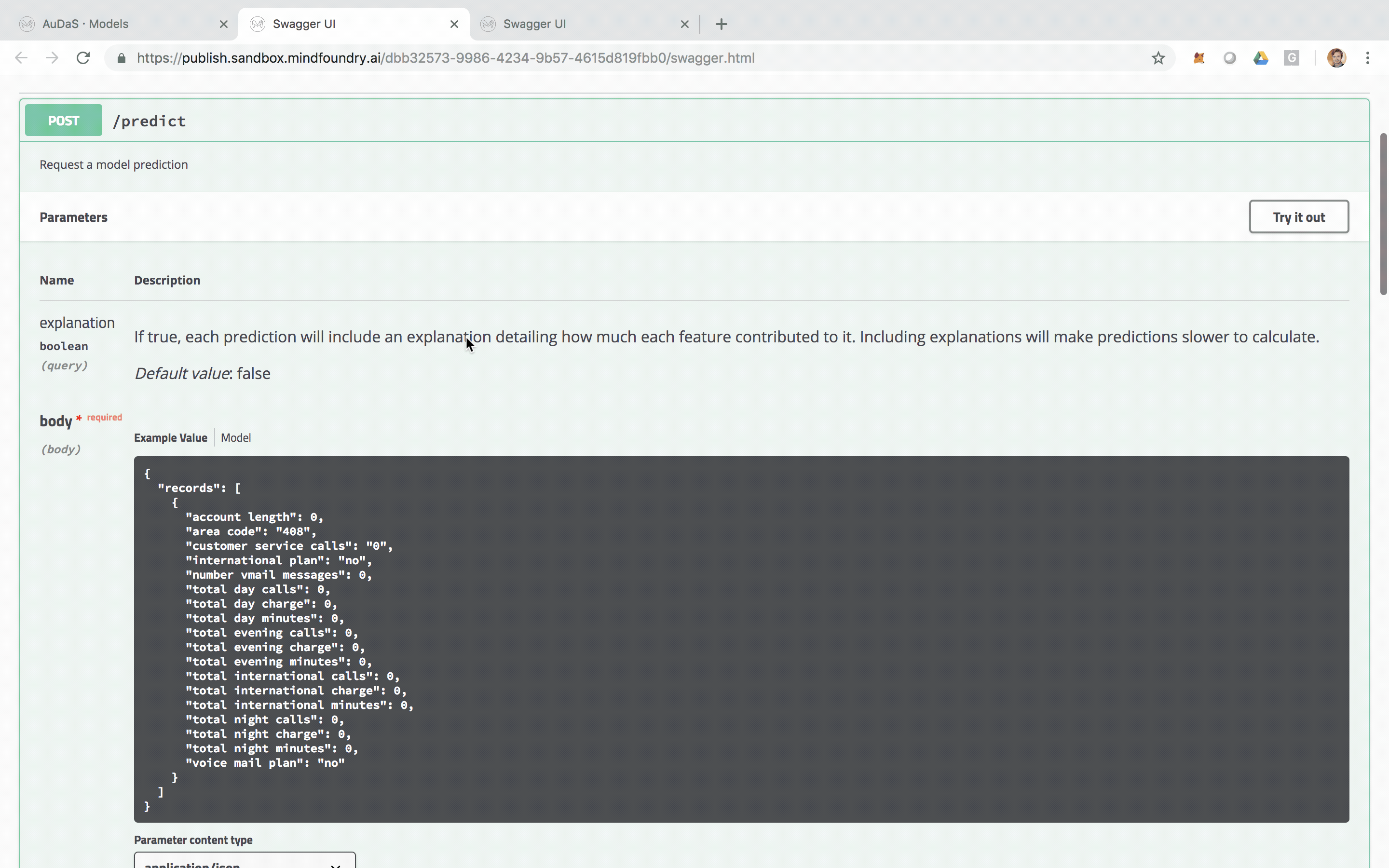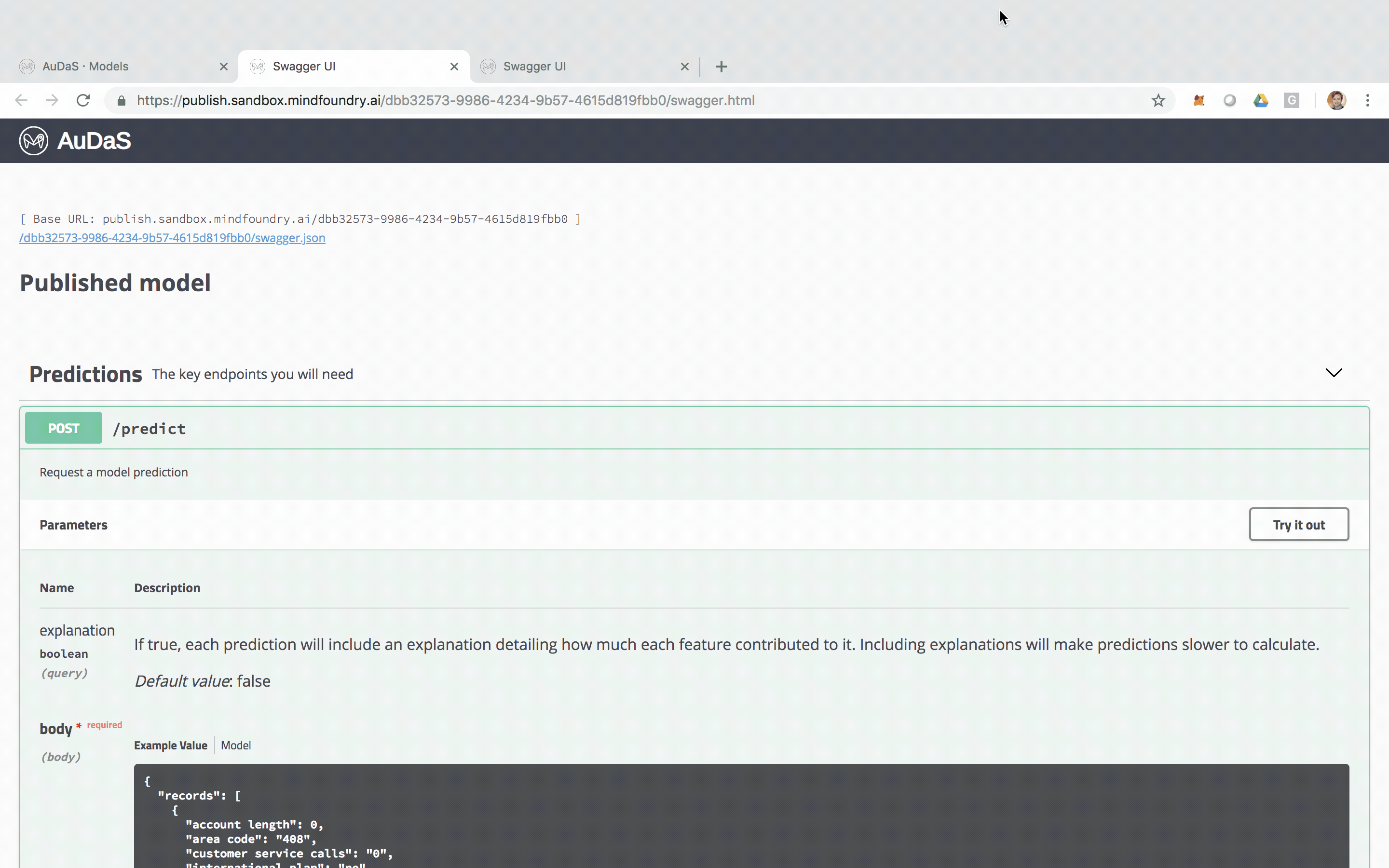
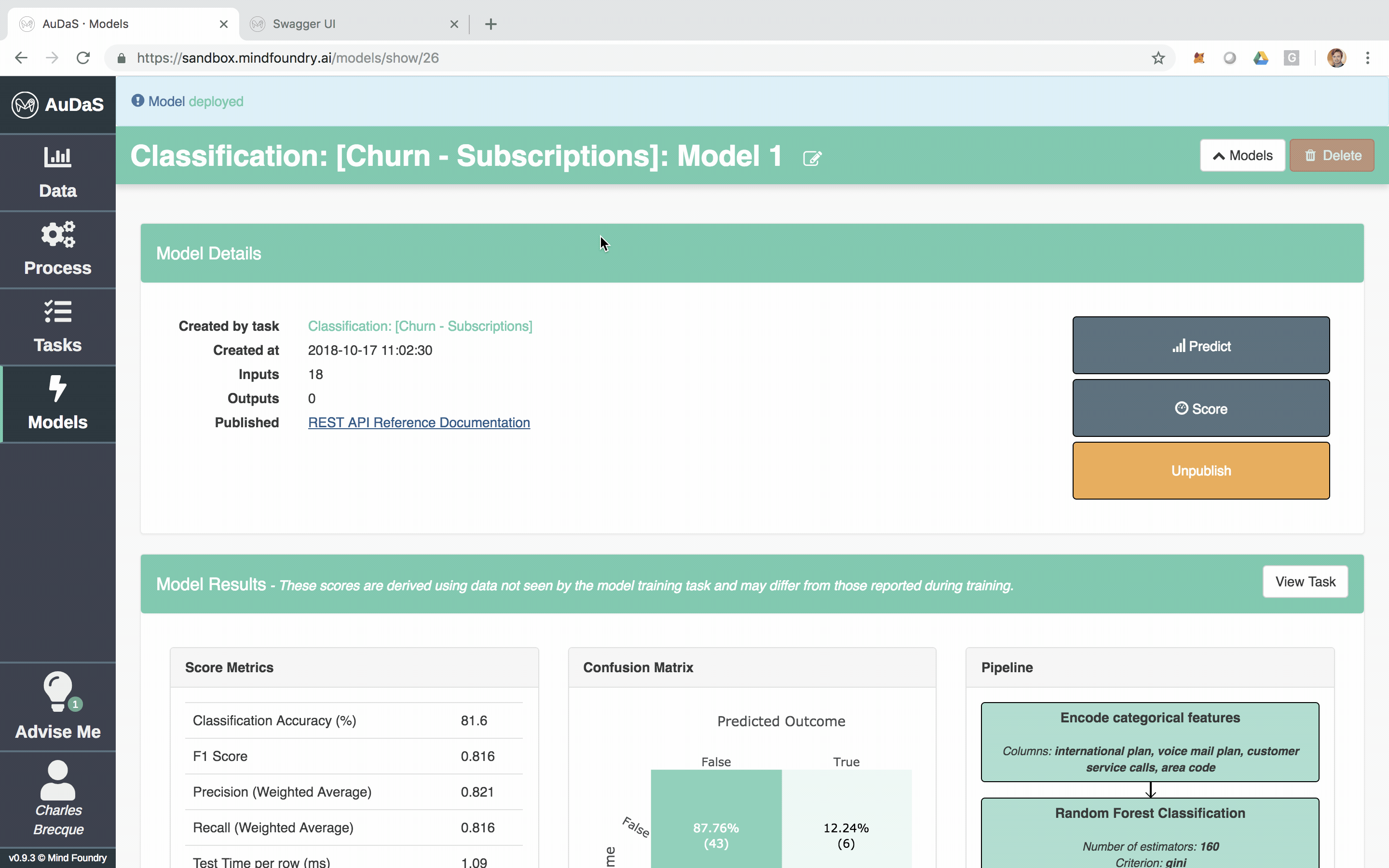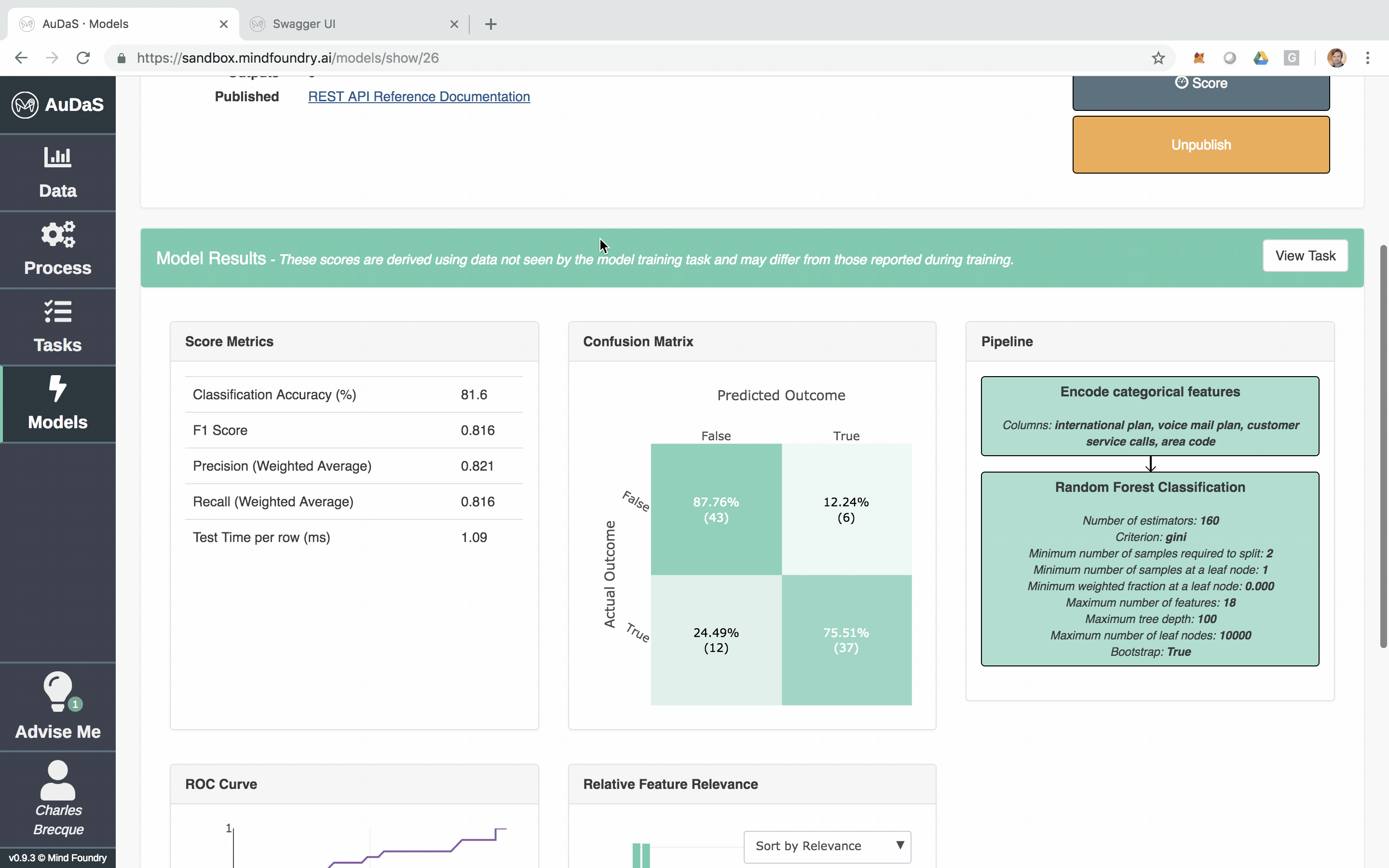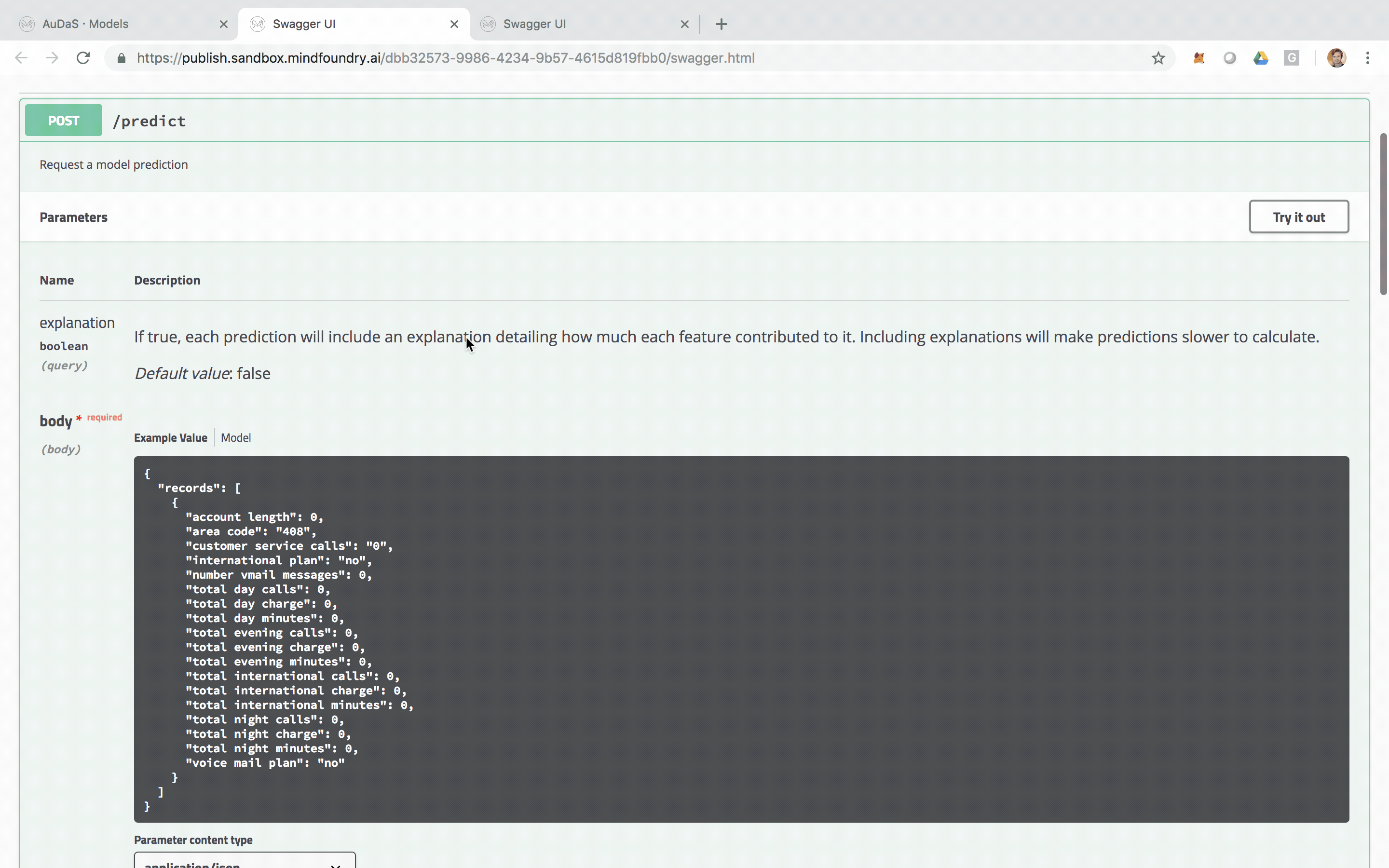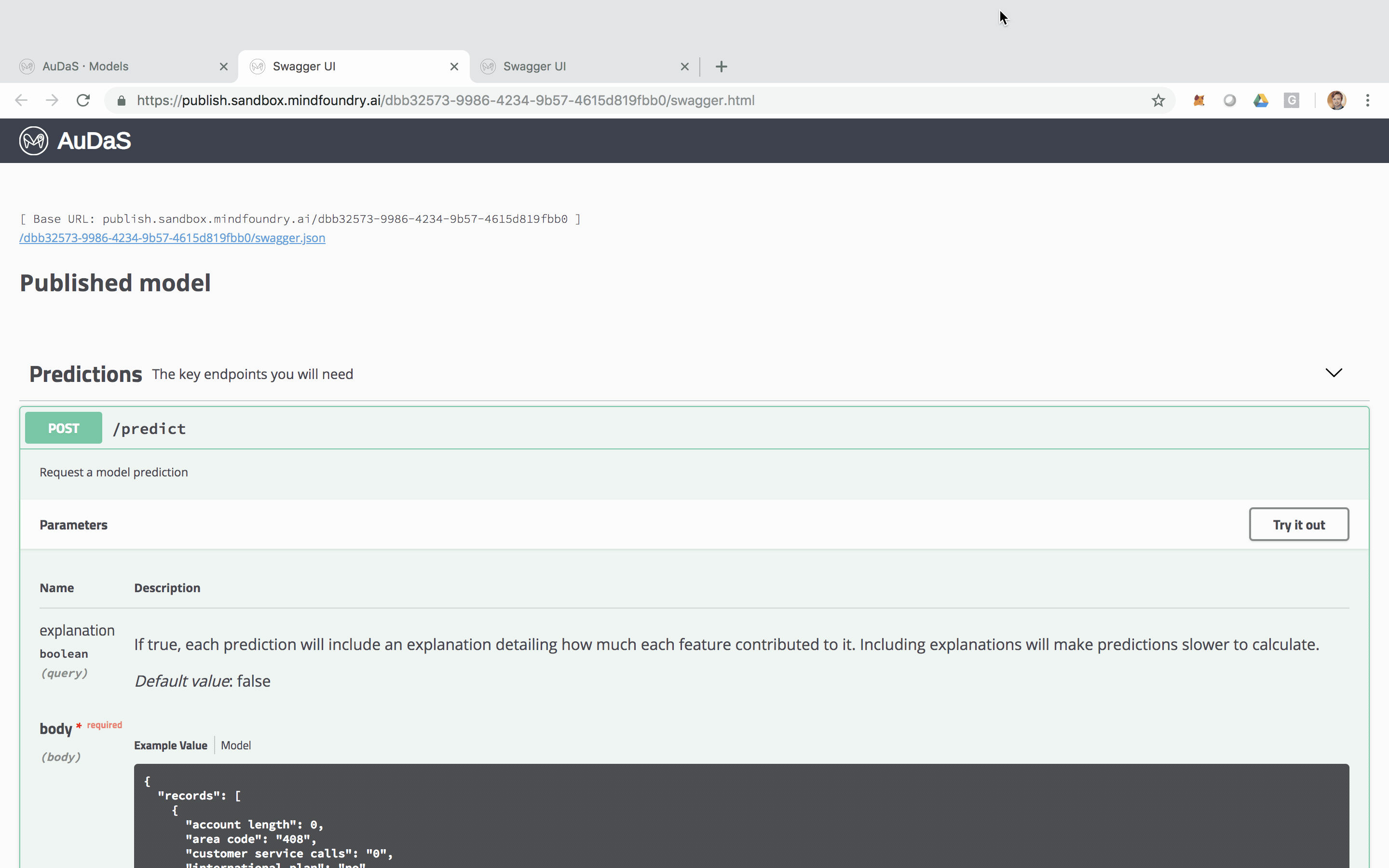
Once AuDaS has found the best pipeline, it will run final quality checks on 10% of the data which was held out right from the start and was never used during any of the model training. The performance metrics on this 10% hold out are presented at the end and AuDaS provides full transparency of the final pipeline it has chosen (feature engineering, models, hyper-parameter values).

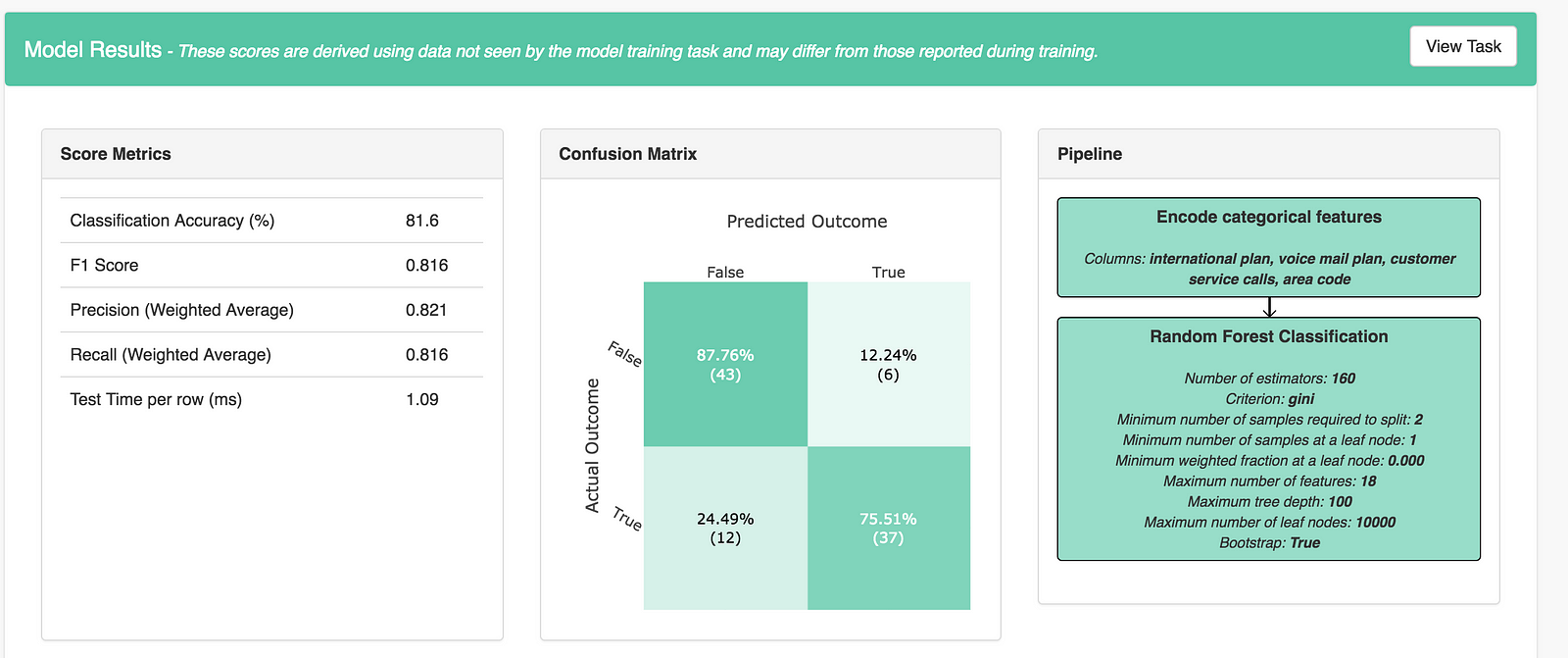

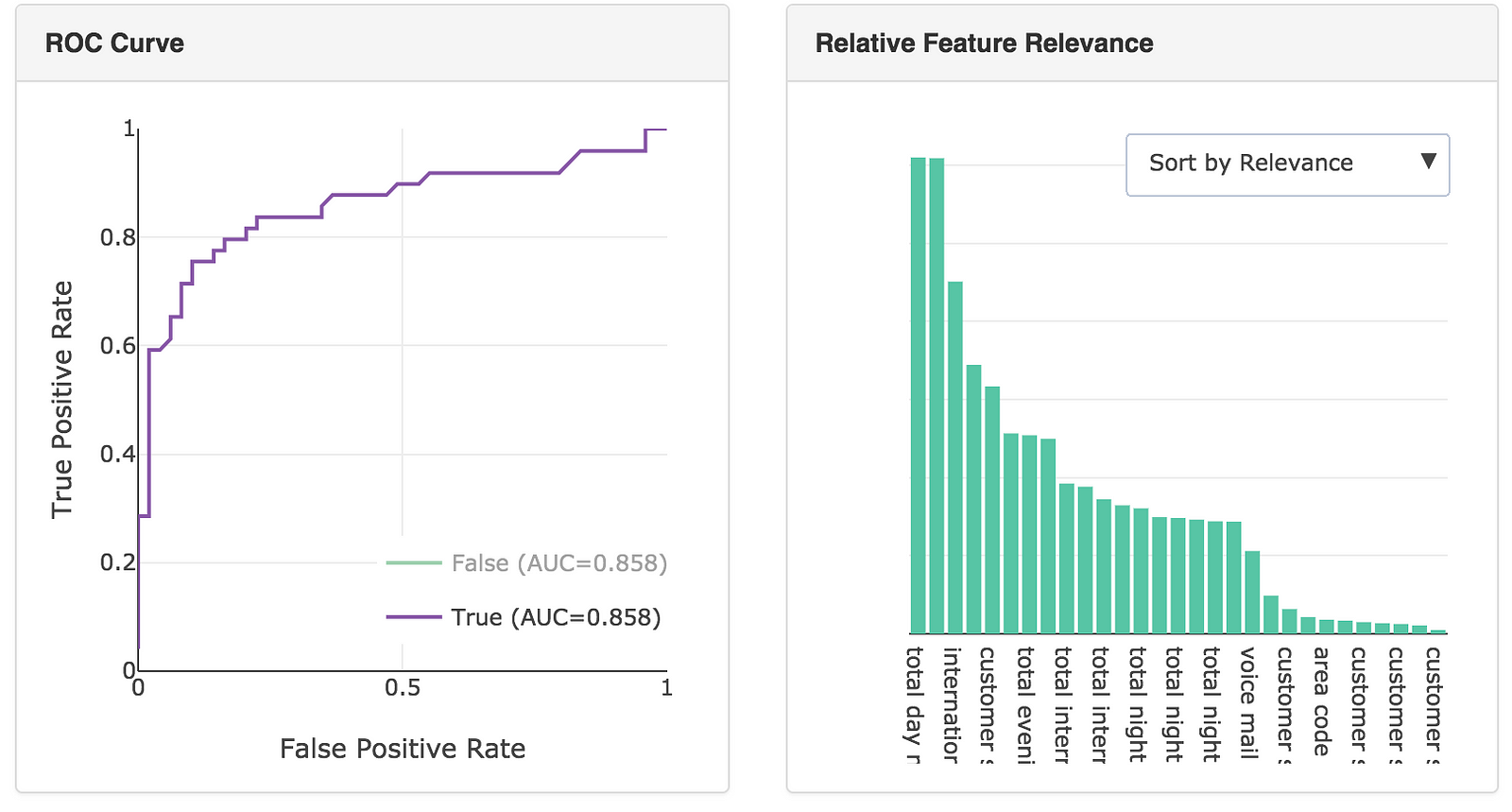
The model can then be integrated into your website, products or business process via an automatically generated RESTful API. The feature relevance is provided by LIME and for our final model, the main feature that predicts churn is the total day charge.
A more complete tutorial can be found here. If you are interested in trying AuDaS, please don’t hesitate to reach out!
Team and Resources
Mind Foundry is an Oxford University spin-out founded by Professors Stephen Roberts and Michael Osborne who have 35 person years in data analytics. The Mind Foundry team is composed of over 30 world class Machine Learning researchers and elite software engineers, many former post-docs from the University of Oxford. Moreover, Mind Foundry has a privileged access to over 30 Oxford University Machine Learning PhDs through its spin-out status. Mind Foundry is a portfolio company of the University of Oxford and its investors include Oxford Sciences Innovation, the Oxford Technology and Innovations Fund, the University of Oxford Innovation Fund and Parkwalk Advisors.