
呼叫百度OCR API過程小記
阿新 • • 發佈:2018-12-28
呼叫百度OCR API過程小記
【標籤】 OCR API Python
data:2018-10-19 author:怡寶2號
【總起】通過url對百度文字識別API進行呼叫,語言為python2
1. 在百度雲控制檯建立API應用
- 整理流程:
- 登陸百度雲
- 建立API呼叫的應用
- 獲取access_token
- 讀取自己的圖片,呼叫API進行識別
登陸百度雲
百度百度雲,可以用百度貼吧、百度雲的賬號登陸
建立應用
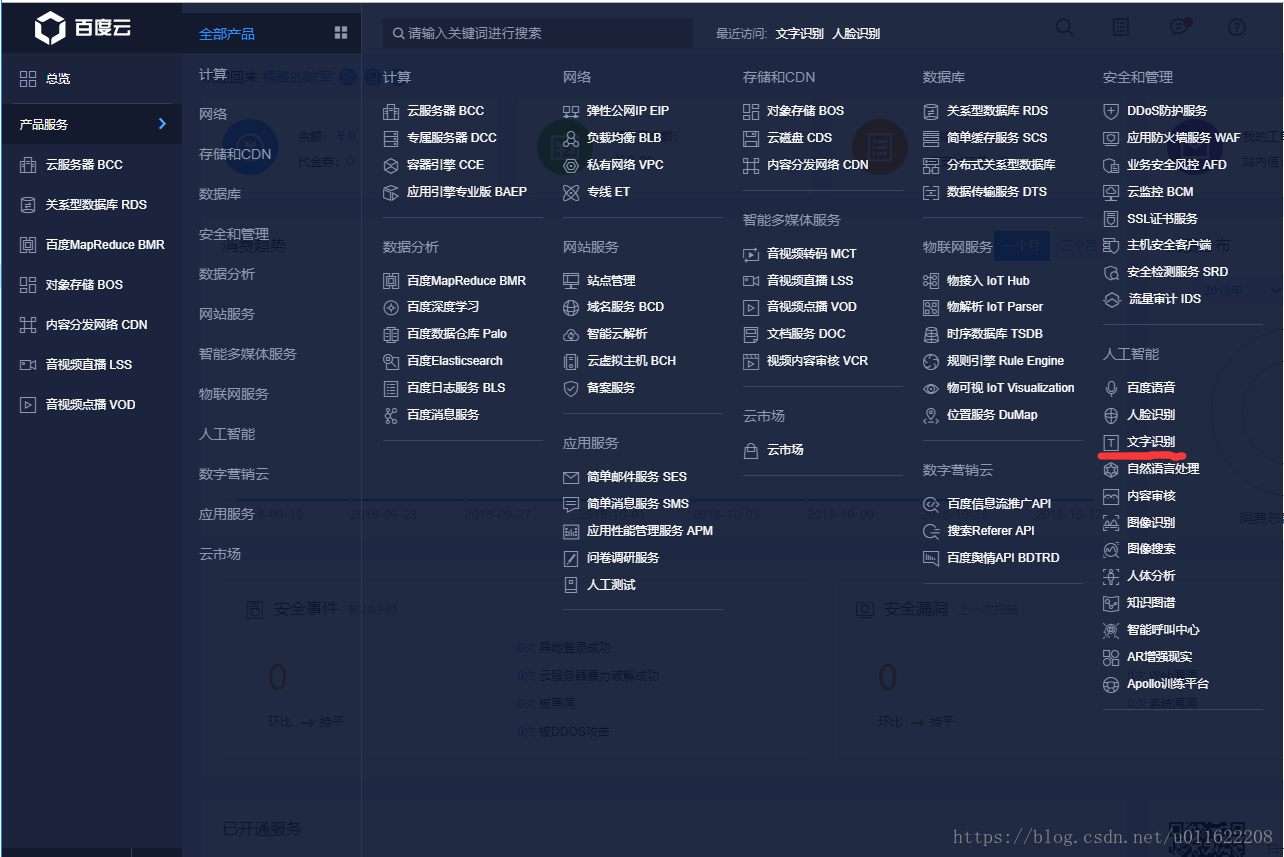
在百度雲控制檯的左側,選擇文字識別
獲取access_token
相當於進行使用者驗證,具體可看百度官網的API文件
文字識別中獲取access_token示例程式碼
import urllib, urllib2, sys import ssl # client_id 為官網獲取的AK, client_secret 為官網獲取的SK host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【官網獲取的AK】&client_secret=【官網獲取的SK】' request = urllib2.Request(host) request.add_header('Content-Type', 'application/json; charset=UTF-8') response = urllib2.urlopen(request) content = response.read() if (content): print(content)
注意修改1. 應用的url;2. client_id; 3. client_secret
讀取自己的圖片,呼叫API進行識別
閱讀官網的API文件,改變示例程式碼中的相關引數
官網通用文字識別(含位置資訊版)的示例程式碼
# coding:utf-8 import urllib, urllib2, base64 access_token = '#####呼叫鑑權介面獲取的token#####' url = 'https://aip.baidubce.com/rest/2.0/ocr/v1/general?access_token=' + access_token # 二進位制方式開啟圖檔案 f = open(r'########本地檔案#######', 'rb') # 引數image:影象base64編碼 img = base64.b64encode(f.read()) params = {"image": img} params = urllib.urlencode(params) request = urllib2.Request(url, params) request.add_header('Content-Type', 'application/x-www-form-urlencoded') response = urllib2.urlopen(request) content = response.read() if (content): print content
總結
百度雲開放了API、SDK等呼叫方式,且每天都有一定量的免費使用次數,可以:
- 實際體驗不用應用的實際效果
- 用最快的速度將不同的應用拼接起來
- 專案方案可行性的快速驗證。比如:專案中要用到OCR識別,則先可以呼叫百度的API,快速完成演示demo
- 加快標註的速度。實際專案在實現過程中都是針對具體場景,一般都會涉及資料標註,這個時候就可以呼叫百度API,雖然有一定的錯誤,但是可以加快標註的速度
reference
[1] 百度API文件中心