
影象的超解析度重建SRGAN與ESRGAN
SRGAN
傳統的影象超解析度重建方法一般都是放大較小的倍數,當放大倍數在4倍以上時就會出現過度平滑的現象,使得影象出現一些非真實感。SRGAN藉助於GAN的網路架構生成影象中的細節。
訓練網路使用均方誤差(MSE)能夠獲得較高的峰值信噪比(PSNR),但是恢復出來的影象會丟失影象的高頻細節資訊,在視覺上有不好的體驗感。SRGAN利用感知損失(perceptual loss)和對抗損失(adversarial loss)來提升輸出影象的真實感。
MSE損失的計算:
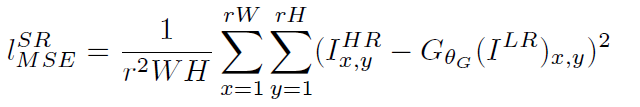 (1)
(1)
感知損失(perceptual loss)
文章中的代價函式改進為:
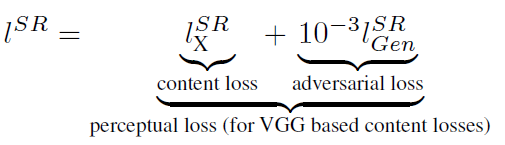 (2)
(2)
第一部分是content loss 基於內容的代價函式,第二部分值基於對抗學習的代價函式。
基於內容的代價函式除了使用基於上述逐個畫素空間的最小均方誤差(MSE)以外,還使用了一個基於特徵空間的最小均方誤差,這個特徵空間是利用VGG網路提取影象的高層次特徵,具體方法如下:
 (3)
(3)
其中i和j表示VGG19網路中第i個最大池化層(maxpooling)後的第j個卷積層得到的特徵。
也就是說內容損失可以二選一:可以是均方誤差損失MSE (公式1),也可以是基於訓練好的以ReLu為啟用函式的損失函式(公式3)
第二部分 是對抗損失,其計算公式如下:
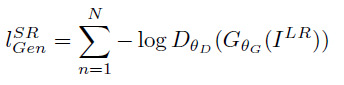 (4)
(4)
其中是一個影象屬於真實的高解析度影象的概率。
是重建的高解析度影象
訓練引數和細節
採用大資料進行訓練,LR是HR影象進行下采樣獲得的(下采樣因子r=4的雙三次核)
使用Adam優化,其beta=0.9,lr=0.0001,迭代次數為100000.
生成器網路中的殘差塊為16個。
最後,對內容損失分別設定成基於均方誤差、基於VGG模型低層特徵和基於VGG模型高層特徵三種情況作了比較
結論:在基於均方誤差的時候表現最差,基於VGG模型高層特徵比基於VGG模型低層特徵的內容損失能生成更好的紋理細節。
pytorch程式碼實現:https://github.com/aitorzip/PyTorch-SRGAN
訓練方法: 構建網路----》 找個一個較為清晰的資料集-------》對每張圖片處理得到低解析度圖片---------》低解析度資料集
用這兩個資料集(HR database + LR database)來訓練網路,實現從LR到HR的轉化。
附:訓練好的模型 https://github.com/brade31919/SRGAN-tensorflow (只能輸入.png格式的圖片)
參考部落格:(https://blog.csdn.net/gavinmiaoc/article/details/80016051 )
ESRGAN
增強型的SRGAN
一、改進點與創新點:
1、引入殘差密集塊,並且將殘差密集塊(RRDB)中的殘差作為基本的網路構建單元而不進行批量歸一化(有助於訓練更深的網路)。
使用殘差縮放(residual scaling)
2、借用相對GAN的思想,讓判別器判斷的是相對真實性而不是絕對真實度 (RaGAN)。
3、利用VGG的啟用前的特徵值改善感知損失,會使得生成的影象有更加清晰的邊緣(為亮度的一致性和紋理恢復提供更強的監控)
二 、演算法的提出
目的:提高SR的總體感知質量
網路中的G的改進:
1)去掉BN層 2)使用殘差密集塊(RRDB)代替原始基礎塊,其結合了多殘差網格和密集連線。
去掉BN層有助於增強效能和減少計算複雜度,並且當測試資料和訓練資料存在差異很大時,BN有可能會引入偽影,從而限制網路的泛化能力。
仍然使用SRGAN的高階設計架構,但是會引入基本塊RRDB。由於更多的層和更多的連線總會提高網路效能。RRDB比residual block擁有更深更復雜的結構。RRDB擁有residual-in-residual結構,殘差學習應用於不同的層。但是本次是在多殘差中使用了密集塊
同時探索了新的方式來訓練網路。1)使用殘差縮放 2)使用較小的初始化 (????這一塊不懂)

2)相對判別器RaD
相對判別器判斷真實比假圖更加真實的概率。
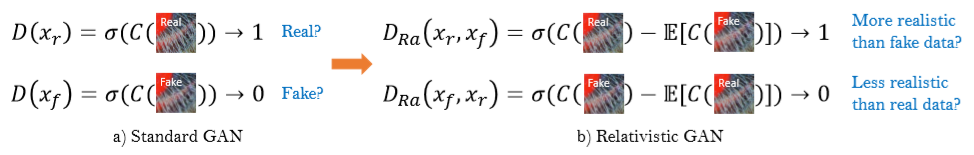
我們用相對論平均判別器RaD代替標準判別器,表示為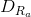
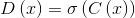
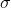
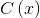
![D_{R_{a}}\left ( x_{r} \right ,x_{f})=\sigma \left ( C\left ( x_{r} \right )-IE_{x_{f}}\left [ C\left ( x_{f} \right ) \right ] \right )](https://img-blog.csdnimg.cn/20181223210000725%5Cleft%20%28%20x_%7Br%7D%20%5Cright%20%2Cx_%7Bf%7D%29%3D%5Csigma%20%5Cleft%20%28%20C%5Cleft%20%28%20x_%7Br%7D%20%5Cright%20%29-IE_%7Bx_%7Bf%7D%7D%5Cleft%20%5B%20C%5Cleft%20%28%20x_%7Bf%7D%20%5Cright%20%29%20%5Cright%20%5D%20%5Cright%20%29)
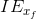
判別器的損失可以定義為:
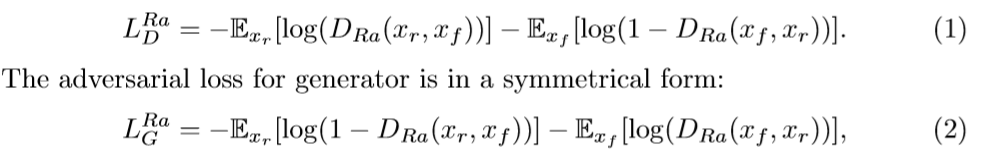
其中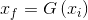
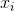
和
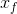
因此,我們的生成器優勢適合於對抗訓練中生成的資料和實際資料的漸變
3)感知損失
一種更有效的感知損失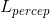
感知損失首先是Johnson et al提出的,並且在SRGAN中擴充套件,感知損失先前定義在預先訓練好的網路的啟用層上,其中,兩個啟用特徵之間的距離被最小化。
本文提出使用的是啟用層前的特性,優點在於:a、被啟用的特徵是非常稀疏的,如baboon的啟用神經元的百分率在VGG19-54層後僅為11.17%。其中54表示最大池化層之前通過第4個卷積所獲得的特徵,表示高階特徵,,類似地,22表示低維特徵。
稀疏啟用提供的弱監督會使得效能變差;;使用啟用後的特徵也會使得影象的亮度和真實影象不一樣。
完整的損失函式表示:
![]()
其中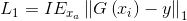
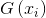
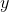
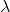
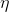
4)網路插值 (不懂)
目的:去掉GAN-based中的不愉快的噪聲,保證生成圖片的質量更好。
先訓練一個基於PSNR值的網路G_snr ,然後通過微調基於GAN的網路獲得G_gan,然後對這兩個網路進行插值計算,得到一個插值模型G_interp,其引數可以表示為:
其中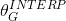
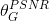
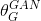
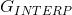
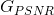
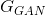
![\alpha \in \left [ 0,1 \right ]](https://img-blog.csdnimg.cn/2018122321000145)
優點:
a) 在不引入偽影的情況下對任何可行的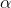
b) 在不重新訓練模型的情況下,持續地平衡感知質量和感覺。
程式碼地址:https://github.com/xinntao/ESRGAN
論文地址:https://arxiv.org/abs/1809.00219