
基於SRGAN實現影象超解析度重建或復原
超解析度技術(Super-Resolution)是指從觀測到的低解析度影象重建出相應的高解析度影象,在監控裝置、衛星影象和醫學影像等領域都有重要的應用價值。SR可分為兩類:從多張低解析度影象重建出高解析度影象和從單張低解析度影象重建出高解析度影象。基於深度學習的SR,主要是基於單張低解析度的重建方法,即Single Image Super-Resolution (SISR)。
SISR是一個逆問題,對於一個低解析度影象,可能存在許多不同的高解析度影象與之對應,因此通常在求解高解析度影象時會加一個先驗資訊進行規範化約束。在傳統的方法中,這個先驗資訊可以通過若干成對出現的低-高解析度影象的例項中學到。而基於深度學習的SR通過神經網路直接學習解析度影象到高解析度影象的端到端的對映函式。
較新的基於深度學習的SR方法,包括SRCNN,DRCN, ESPCN,VESPCN和SRGAN等。 本文重點介紹SRGAN及其實現。
SRGAN (Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, arxiv, 21 Nov, 2016)將生成式對抗網路(GAN)用於SR問題。其出發點是傳統的方法一般處理的是較小的放大倍數,當影象的放大倍數在4以上時,很容易使得到的結果顯得過於平滑,而缺少一些細節上的真實感。因此SRGAN使用GAN來生成影象中的細節。
在這篇文章中,將生成對抗網路(Generative Adversarial Network, GAN)用在瞭解決超解析度問題上。文章提到,訓練網路時用均方差作為損失函式,雖然能夠獲得很高的峰值信噪比,但是恢復出來的影象通常會丟失高頻細節,使人不能有好的視覺感受。SRGAN利用感知損失(perceptual loss)和對抗損失(adversarial loss)來提升恢復出的圖片的真實感。感知損失是利用卷積神經網路提取出的特徵,通過比較生成圖片經過卷積神經網路後的特徵和目標圖片經過卷積神經網路後的特徵的差別,使生成圖片和目標圖片在語義和風格上更相似。一個GAN所要完成的工作,GAN原文舉了個例子:生成網路(G)是印假鈔的人,判別網路(D)是檢測假鈔的人。G的工作是讓自己印出來的假鈔儘量能騙過D,D則要儘可能的分辨自己拿到的鈔票是銀行中的真票票還是G印出來的假票票。開始的時候呢,G技術不過關,D能指出這個假鈔哪裡很假。G每次失敗之後都認真總結經驗,努力提升自己,每次都進步。直到最後,D無法判斷鈔票的真假……SRGAN的工作就是: G網通過低解析度的影象生成高解析度影象,由D網判斷拿到的影象是由G網生成的,還是資料庫中的原影象。當G網能成功騙過D網的時候,那我們就可以通過這個GAN完成超解析度了。
傳統的方法使用的代價函式一般是最小均方差(MSE),即
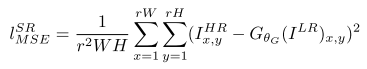
該代價函式使重建結果有較高的信噪比,但是缺少了高頻資訊,出現過度平滑的紋理。SRGAN認為,應當使重建的高解析度影象與真實的高解析度影象無論是低層次的畫素值上,還是高層次的抽象特徵上,和整體概念和風格上,都應當接近。整體概念和風格如何來評估呢?可以使用一個判別器,判斷一副高解析度影象是由演算法生成的還是真實的。如果一個判別器無法區分出來,那麼由演算法生成的影象就達到了以假亂真的效果。
因此,該文章將代價函式改進為
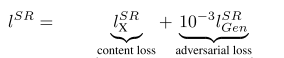 第一部分是基於內容的代價函式,第二部分是基於對抗學習的代價函式。基於內容的代價函式除了上述畫素空間的最小均方差以外,又包含了一個基於特徵空間的最小均方差,該特徵是利用VGG網路提取的影象高層次特徵:
第一部分是基於內容的代價函式,第二部分是基於對抗學習的代價函式。基於內容的代價函式除了上述畫素空間的最小均方差以外,又包含了一個基於特徵空間的最小均方差,該特徵是利用VGG網路提取的影象高層次特徵: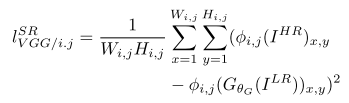 對抗學習的代價函式是基於判別器輸出的概率:
對抗學習的代價函式是基於判別器輸出的概率: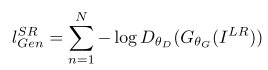
其中是一個影象屬於真實的高解析度影象的概率。
是重建的高解析度影象。SRGAN使用的生成式網路和判別式網路分別如下:
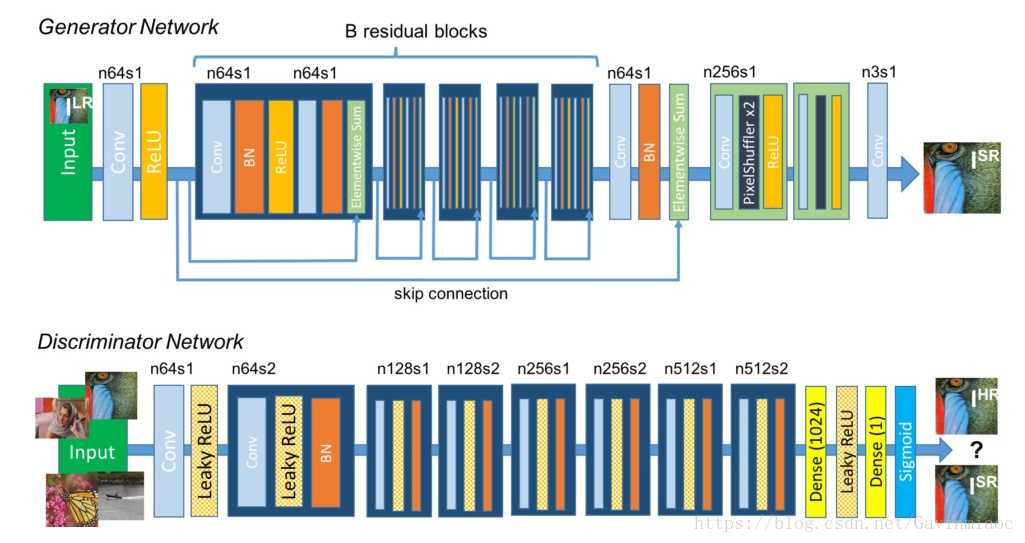
在生成網路部分(SRResNet)部分包含多個殘差塊,每個殘差塊中包含兩個3×3的卷積層,卷積層後接批規範化層(batch normalization, BN)和PReLU作為啟用函式,兩個2×亞畫素卷積層(sub-pixel convolution layers)被用來增大特徵尺寸。在判別網路部分包含8個卷積層,隨著網路層數加深,特徵個數不斷增加,特徵尺寸不斷減小,選取啟用函式為LeakyReLU,最終通過兩個全連線層和最終的sigmoid啟用函式得到預測為自然影象的概率。SRGAN的損失函式為:
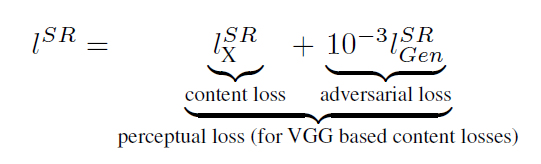
其中內容損失可以是基於均方誤差的損失的損失函式:
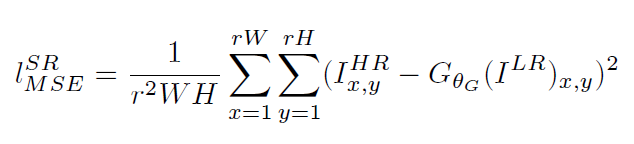
也可以是基於訓練好的以ReLU為啟用函式的VGG模型的損失函式:
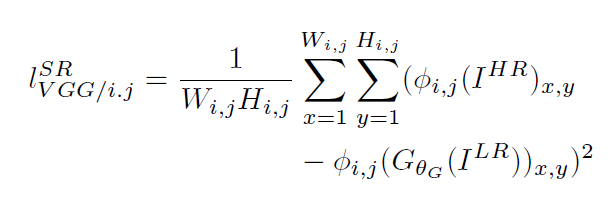
i和j表示VGG19網路中第i個最大池化層(maxpooling)後的第j個卷積層得到的特徵。對抗損失為:
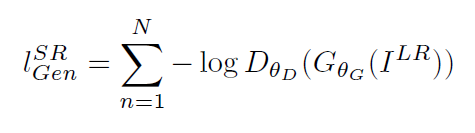
文章中的實驗結果表明,用基於均方誤差的損失函式訓練的SRResNet,得到了結果具有很高的峰值信噪比,但是會丟失一些高頻部分細節,影象比較平滑。而SRGAN得到的結果則有更好的視覺效果。其中,又對內容損失分別設定成基於均方誤差、基於VGG模型低層特徵和基於VGG模型高層特徵三種情況作了比較,在基於均方誤差的時候表現最差,基於VGG模型高層特徵比基於VGG模型低層特徵的內容損失能生成更好的紋理細節。
論文介紹到此。下面介紹SRGAN的tensorflow實現。
先看一組圖:

訓練方法大致就是構建好網路後,找一個高清圖片資料集,對每個圖片做處理得到低解析度的圖片,從而得到低解析度圖片資料集。用這兩個資料集來訓練網路,實現低解析度到高解析度圖片的轉化。
具體程式碼這裡就不一一貼了,原始碼拿下來後基本上是能跑到,如果要訓練或預測自己到資料集,請先製作好資料集。如果你對這個實驗感興趣,也可以自己來嘗試一下。在Github可以搜到很多TensorFlow下的開原始碼,如果自己機器顯示卡夠強的話可以自己按照說明訓練,如果顯示卡不行也沒關係,我實驗的這份原始碼作者提供了預訓練好的模型,原始碼: https://github.com/brade31919/SRGAN-tensorflow
要注意的是,這份程式碼只能輸入png圖片,如果你是jpg圖片,請先將圖片格式進行轉換。手動或者程式碼批量轉換。
下載原始碼和模型後,將模型資料夾“SRGAN_pre-trained”直接放到原始碼目錄下,建立一個你的圖片目錄,將png圖片丟進去,修改“inference_SRGAN.sh”檔案的紅框部分為你的圖片路徑:
#!/usr/bin/env bash
CUDA_VISIBLE_DEVICES=0 python main.py \
--output_dir ./result/inference/ \
--summary_dir ./result/log/ \
--mode inference \
--is_training False \
--task SRGAN \
--input_dir_LR ./data/myimages/ \ # modify the path to your image path
--num_resblock 16 \
--perceptual_mode VGG54 \
--pre_trained_model True \
--checkpoint ./SRGAN_pre-trained/model-200000然後在終端執行“inference_SRGAN.sh”檔案即可,當然IDE裡執行也是可以的,先做好引數配置,然後執行main.py即可。
也可以
Run test using pre-trained modelRun the training process
當然train自己的資料集,需要在GPU上跑的。這塊暫未測試。來看看結果:
人臉提升:

從對比來看很容易發現確實提高了解析度,至少視覺上看總覺得上邊的是略模糊的。
我們放大來看一下演算法到底做了什麼:




從放大圖中可以看到,人臉上多了很多奇怪的紋路,但是縮小後,看起來解析度確實提高了。
對於低解析度的圖,我們用原訓練的模型預測效果不是很好,需要自己重新訓練了。

分別是input,output,target.可見,output與target差距還是蠻大的。後面重新訓練模型後效果會好。