
Part 2: Scheduling Notebooks at Netflix
Part 2: Scheduling Notebooks at Netflix
At Netflix we’ve put substantial effort into adopting notebooks as an integrated development platform. The idea started as a discussion of what development and collaboration interfaces might look like in the future. It evolved into a strategic bet on notebooks, both as an interactive UI and as the unifying foundation of our workflow scheduler. We’ve made significant strides towards this over the past year, and we’re currently in the process of migrating all 10,000
Origin Story
When thinking about the future of analytics tooling, we initially asked ourselves a few basic questions:
- What interface will a data scientist use to communicate the results of a statistical analysis to the business?
- How will a data engineer write code that a reliability engineer can help ensure runs every hour?
- How will a machine learning engineer encapsulate a model iteration their colleagues can reuse?
We also wondered: is there a single tool that can support all of these scenarios?

One tool that showed promise was the Jupyter notebook. Notebooks were already used at Netflix for data science but were increasingly being used for other types of workloads too. With its flexible nature and high extensibility, plus its large and vibrant open source community, notebooks was a compelling option. So, we took a deeper look at how we might use it as a common interface for our users.
Notebooks are, in essence, managed JSON documents with a simple interface to execute code within. They’re good at expressing iterative units of work via cells, which facilitate reporting and execution isolation with ease. Plus, with different kernels, notebooks can support a wide range of languages and execution patterns. These attributes mean that we can expose any arbitrary level of complexity for advanced users while presenting a more easily followed narrative for consumers — all within a single document. We talk about these attributes and their supporting services more in our previous post. If you haven’t read it yet, it’s a good introduction to the work we’re doing on notebooks, including our motivations and other use cases.
We knew that any tooling we chose we would need the ability to schedule our workloads. As the potential of Jupyter notebooks became increasingly clear, we began to look at what it would take to schedule a notebook. The properties of a notebook, while excellent for interactive work, do not readily lend to scheduled execution. If you’re already familiar with notebooks — both their strengths and weaknesses — you may even think we’re a little crazy for moving all of our etl workloads to notebooks.
Notebook Woes to Wins
On the surface, notebooks pose a lot of challenges: they’re frequently changed, their cell outputs need not match the code, they’re difficult to test, and there’s no easy way to dynamically configure their execution. Furthermore, you need a notebook server to run them, which creates architectural dependencies to facilitate execution. These issues caused some initial push-back internally at the idea. But that has changed as we’ve brought in new tools to our notebook ecosystem.
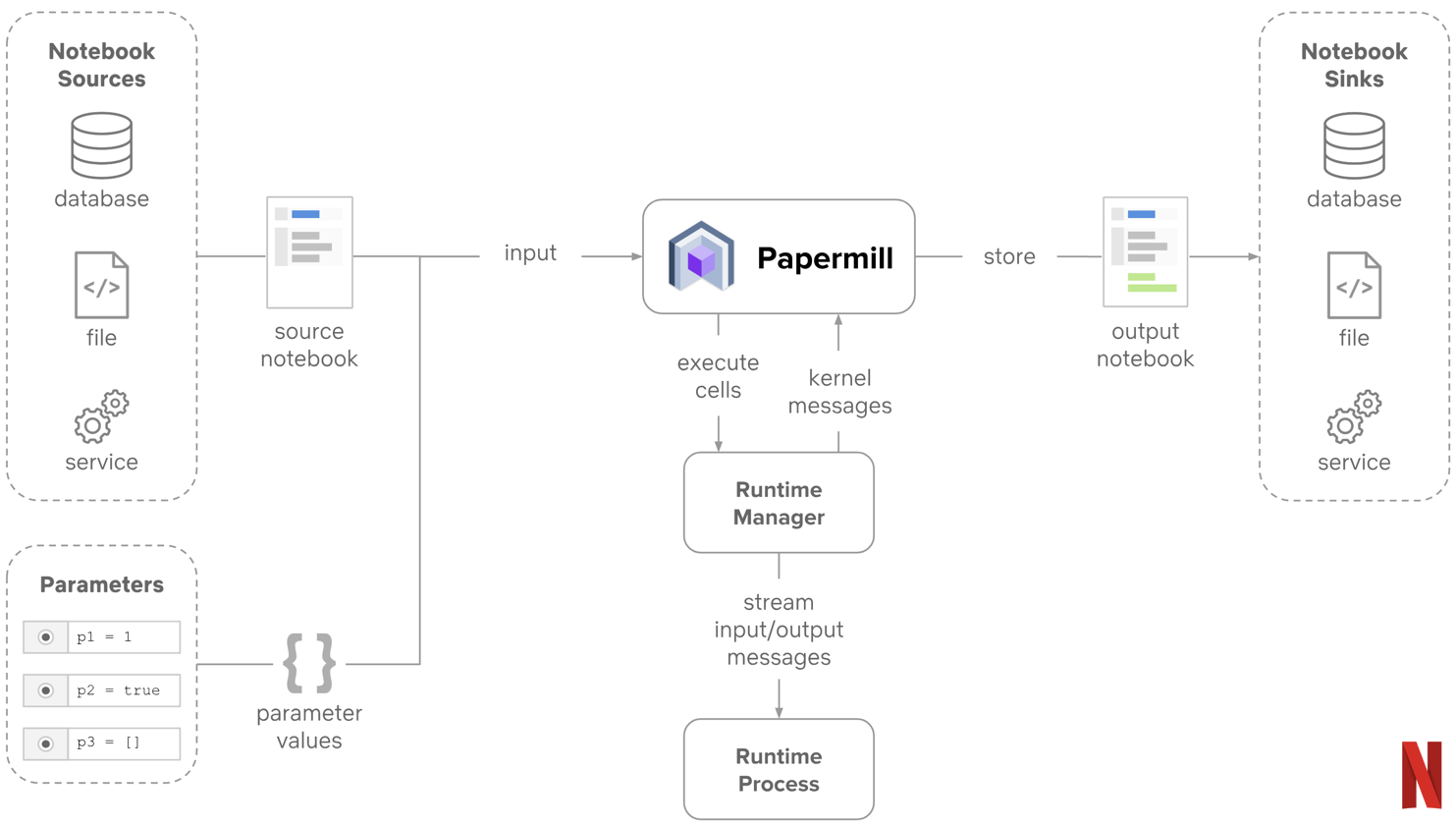
The biggest game-changer for us is Papermill. Papermill is an nteract library built for configurable and reliable execution of notebooks with production ecosystems in mind. What Papermill does is rather simple. It take a notebook path and some parameter inputs, then executes the requested notebook with the rendered input. As each cell executes, it saves the resulting artifact to an isolated output notebook.

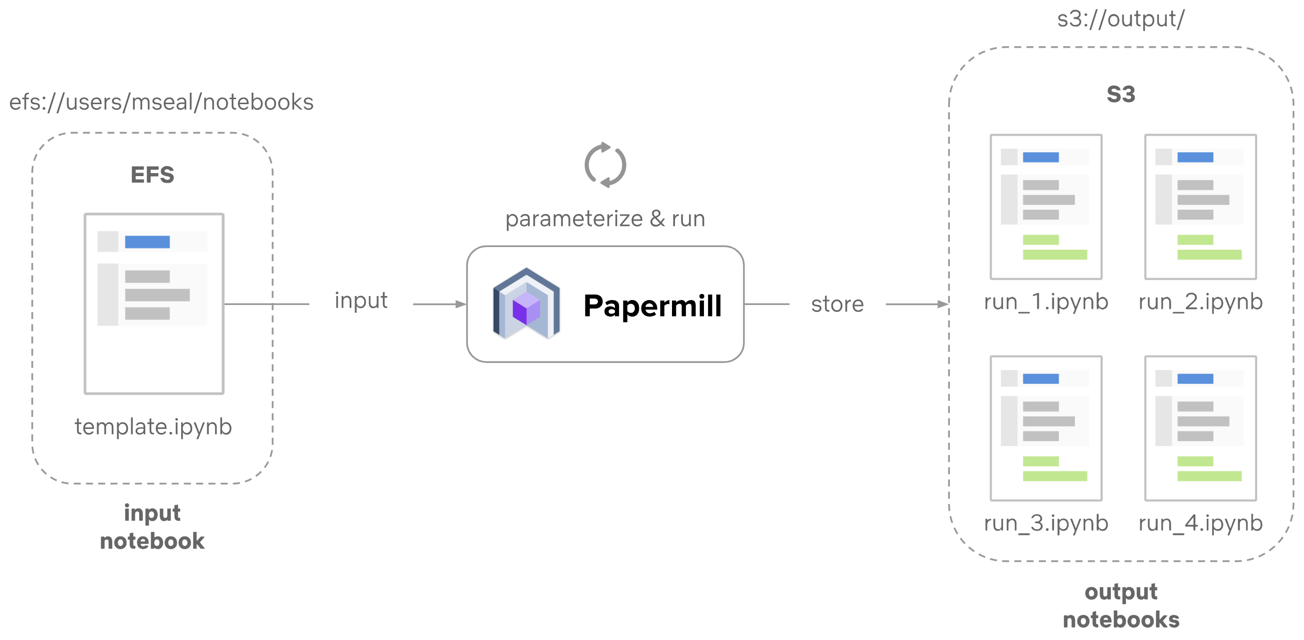
Papermill enables a paradigm change in how you work with notebook documents. Since Papermill doesn’t modify the source notebook, we get a functional property added to our definition of work — something which is normally missing in the notebook space. Our inputs, a notebook JSON document and our input parameters, are treated as immutable records for execution that produce an immutable output document. That single output document provides the executed code, the outputs and logs from each code cell, and a repeatable template which can be easily rerun at any point in the future.
Another feature of Papermill is its ability to read or write from many places. This enables us to store our output notebook somewhere with high durability and easy access in order to provide a reliable pipeline. Today we default to storing our output notebooks to an s3 bucket managed by Commuter, another nteract project which provides a read-only display of notebooks.
Output notebooks can thus become isolated records on whichever system best supports our users. This makes analyzing jobs or related work as easy as linking to a service or S3 prefix. Users can take those links and use them to debug issues, check on outcomes, and create new templates without impacting the original workflows.
Additionally, since Papermill controls its own runtime processes, we don’t need any notebook server or other infrastructure to execute against notebook kernels. This eliminates some of the complexities that come with hosted notebook services as we’re executing in a simpler context.

To further improve notebook reliability, we push our notebooks into git and only promote them to production services after we run tests against those notebooks using Papermill. If a notebook becomes too complex to easily test, we have the local repository into which we can consolidate code in a more traditional package. This allows us to gain the benefits of normal CI tooling in promoting notebooks as traditional code, but still allow us to explore and iterate with notebooks as an integration tool.
Our notebooks thus became versioned, pushed as immutable records to a reliable data store before and after execution, tested before they’re made available, and made parameterizable for specialization at runtime. The user-friendly-but-unreliable notebook format is now made reliable for our data pipelines, and we’ve gained a key improvement over a non-notebook execution pattern: our input and outputs are complete documents, wholly executable and shareable in the same interface.
Scheduling Notebooks
Even with a platform supporting the testing, versioning, and presentation of notebooks we were still missing a key component to enable users to run work on a periodic basis with triggered executions — or more concisely, we needed a scheduling layer. Executing a notebook through a web interface is great for visual and reactive feedback for users, but once you have something working you need a tool to do that execution on your behalf.
The execution side of this equation is made easy with Papermill. We can compute runtime parameters and inject them into a notebook, run the notebook, and store the outcomes to our data warehouse. This architecture decouples parameterized notebooks from scheduling, providing flexibility in choosing a scheduler. Thus just about any cron string and/or event consuming tool can enable running the work we’ve setup so far.

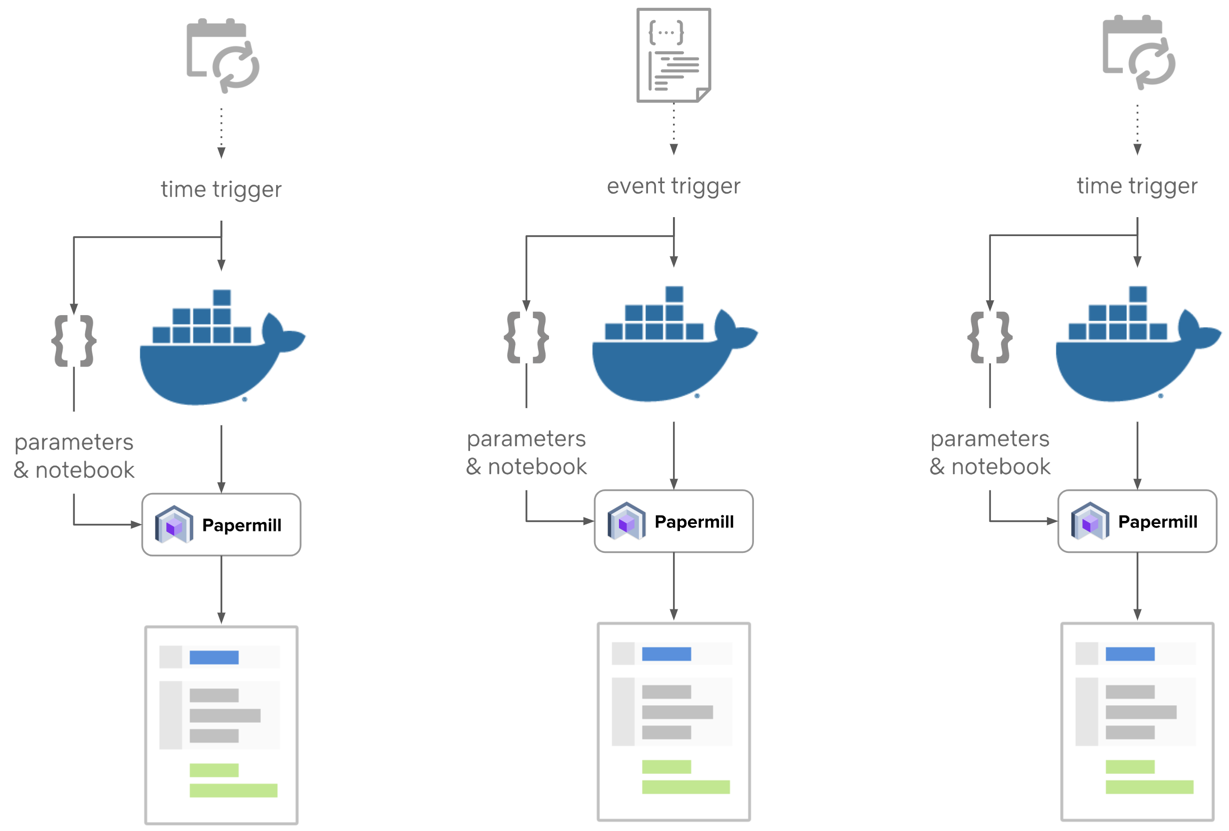
This means that so long as a few basic capabilities are present, scheduling notebooks is easy. Instead, you’ll want to spend effort here on choosing the secondary attributes of the scheduler that you care most about. You may want to reuse a tool already familiar to your team, or make a choice to satisfy other operational needs. If you don’t have a preferred scheduler or haven’t used one before, Airflow is an open source tool that can serve this role well.
In our case, the secondary attributes we cared about were:
- Trigger or wait-for capabilities for external events
- Ability to launch inside a controlled execution environment (e.g. Docker)
- Capturing and exposing metrics on executions and failures
- Concurrency controls
- Configurability of dynamic retries
- Ability for reliability teams to intercede on behalf of users
These requirements left us with a handful of potential options to consider, including both open and closed source solutions. After thoroughly exploring our options, we chose a scheduler developed at Netflix called Meson. Meson is a general purpose workflow orchestration and scheduling framework for executing ML pipelines across heterogeneous systems. One of the major factors for us choosing Meson is its deep support for Netflix’s existing cloud-based infrastructure, including our data platform.
User Workflow
With a scheduler in place, how would this to look to a developer? Let’s explore a hypothetical data workflow. Suppose we want to aggregate video plays by device type to understand which devices our members use to watch content. Because we’re global, we need to split our aggregates by region so we can understand the most popular devices in each part of the world. And, once the results are ready each day, we want to push the updated report to our analysts.
To start, we’ll need a schedule for our workflow. Let’s say daily at 2 AM. Most schedulers accept crontab as a schedule trigger, so a single 0 2 * * * string satisfies this requirement.
Next, we need to break our work into logical units of work. We’ll want to collect our data, aggregate it, and report back to the user the results. To express this work we’ll define a DAG with each individual job represented as a node in the graph, and each edge represents the next job to run upon success.
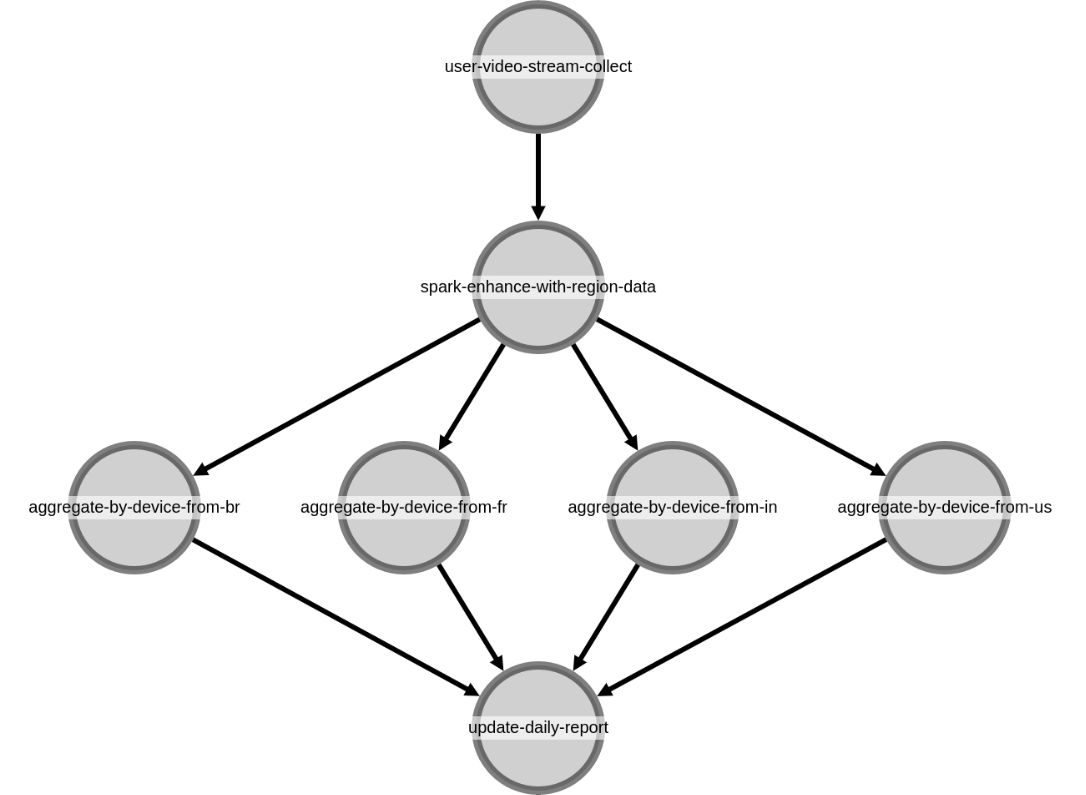
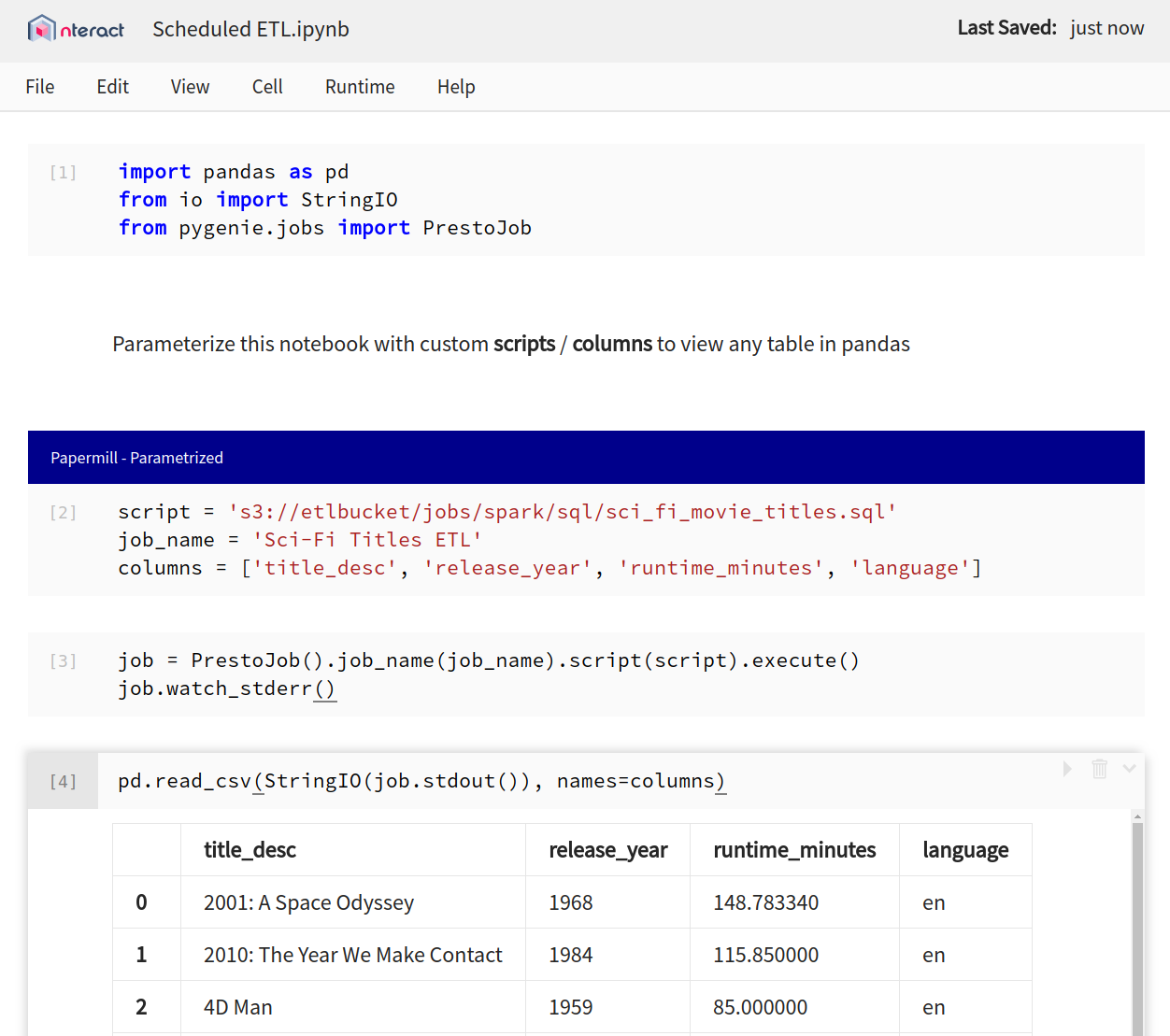
In this scenario, we would need four notebooks. One to collect our input data. One to enhance our raw data with geographical information. One to be parameterized for each region. And one to push our results to a report. Our aggregate notebook, for example, might have a parameterized execution such as:
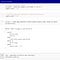

We have a few lines of code to execute a simple SQL statement. You can see that in cell [4] we have our injected parameters from Papermill overwriting the default region_code. The run_date is already what we want, so we’ll keep the default instead of overwriting it.
The scheduler then executes a simple command to run the notebook.
papermill s3://etlbucket/jobs/templates/vid_agg.ipynb s3://etlbucket/jobs/outputs/${timestamp}_vid_agg_fr.ipynb -p region_code frDone! Pretty easy, isn’t it? Now, this is a contrived example and may not reflect how our data engineers would actually go about this work, but it does help demonstrate how everything fits together in a workflow.
Self Service Debugging
Another important aspect to consider when bringing new technologies to a platform is the ability to debug and support its users. With notebooks, this is probably the most beneficial aspect of our scheduler system.
Let’s dig into how we would deal with a failure. Say something went wrong in our example notebook from earlier. How might we debug and fix the issue? The first place we’d want to look is the notebook output. It will have a stack trace, and ultimately any output information related to an error.

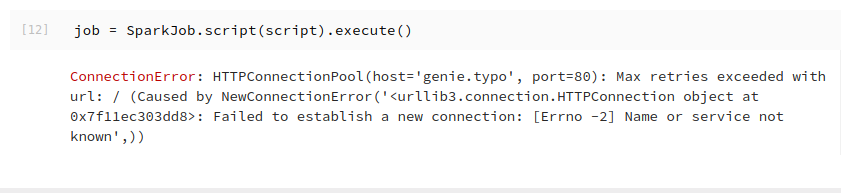
Here we see that our job couldn’t find the ‘genie.typo’ hostname. That’s probably not a user input error, so we’ll likely need to change the template to have the correct hostname. In a traditional scheduler situation, you’d need to either create a mock of the job execution environment or try making changes and resubmitting a similar job. Here instead we simply take the output notebook with our exact failed runtime parameterizations and load it into a notebook server.
With a few iterations and looking at our job library methods, we can quickly find a fix for the failure.

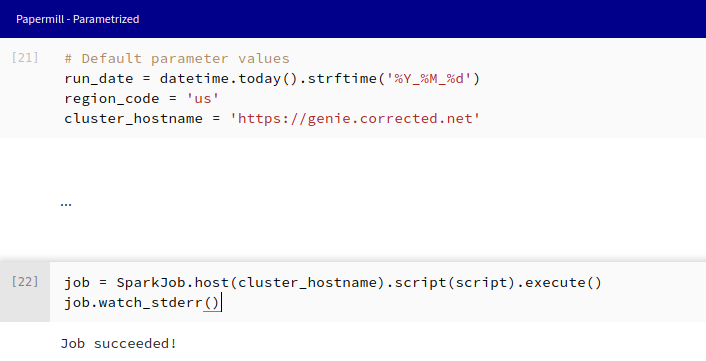
Now that it’s fixed, this template can be pushed to the source notebook path. Any future executions, including retrying the failed job, will pick up and run the updated template.
Integrating Notebooks
At Netflix we’ve adopted notebooks as an integration tool, not as a library replacement. This means we needed to adopt good integration testing to ensure our notebooks execute smoothly and don’t frequently run into bugs. Since we already have a pattern for parameterizing our execution templates, we repeat these interactions with dummy inputs as a test of linear code paths.
papermill s3://etlbucket/jobs/templates/vid_agg.ipynb s3://etlbucket/jobs/tests/.ipynb -p region_code luna -p run_date 2017_01_01

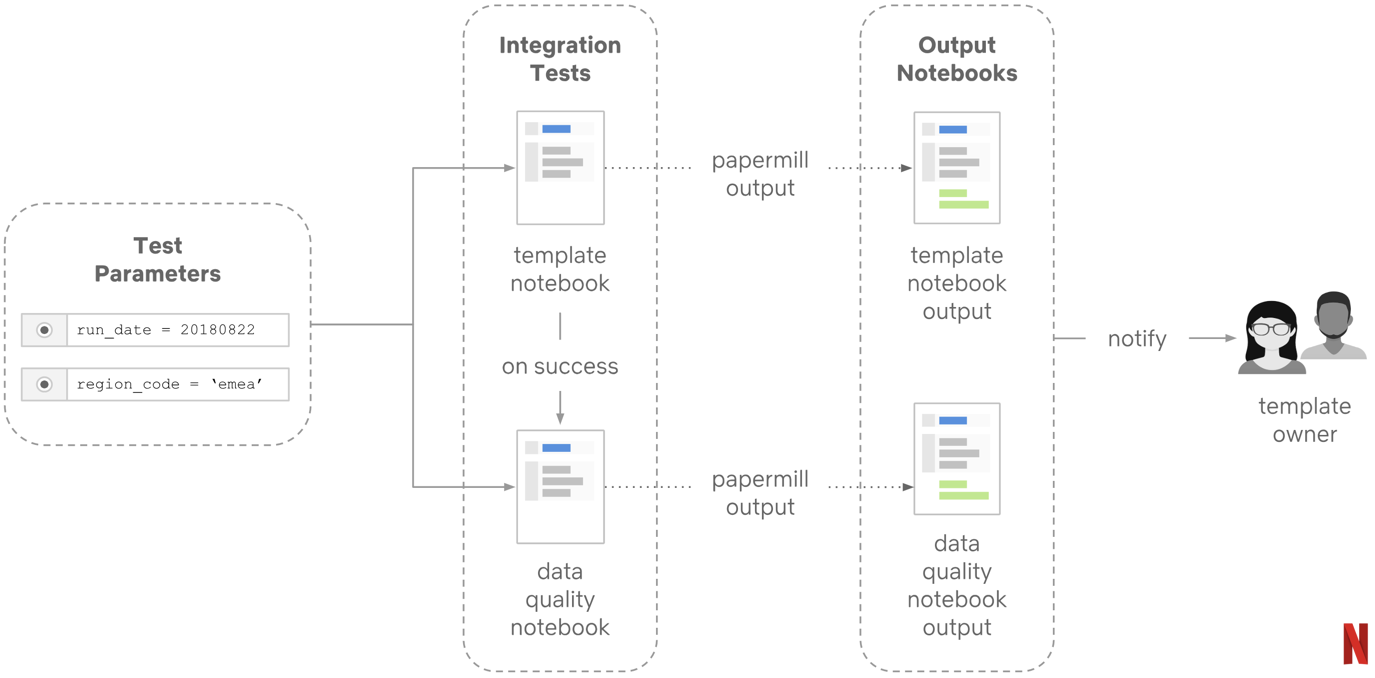
What this means is that we’re not using notebooks as code libraries and consequently aren’t pressing for unit level tests on our notebooks, as those should be encapsulated by the underlying libraries. Instead, we promote guiding principles for notebook development:
- Low Branching Factor: Keep your notebooks fairly linear. If you have many conditionals or potential execution paths, it becomes hard to ensure end-to-end tests are covering the desired use cases well.
- Library Functions in Libraries: If you do end up with complex functions which you might reuse or refactor independently, these are good candidates for a coding library rather than in a notebook. Providing your notebooks in git repositories means you can position shared unit-tested code in that same repository as your notebooks, rather than trying to unit test complex notebooks.
- Short and Simple is Better: A notebook which generates lots of useful outputs and visuals with a few simple cells is better than a ten page manual. This makes your notebooks more shareable, understandable, and maintainable.
When followed, these guidelines make it easy for us to guide and support our users across a wide spectrum of use-cases and underlying technologies.