
Generating Drake Rap Lyrics using Language Models and LSTMs
About the Model
Now, we are going to talk about the model for text generation, this is really what you are here for, it’s the real sauce - raw sauce. I’m going to start off by talking about the model design and some important elements that make lyric generation possible and then, we are going to jump into the implementation of it.
There are two main approaches to building Language Models: (1) Character-level Models and (2) Word-level models.
The main difference for each one of the models comes from what your inputs and outputs are, and I’m going to talk exactly about how each one of them works here.
Character-level model
In a case of a character-level model your input is a series of characters seed
new_char. Then you use the seed + new_char together to generate the next character and so on. Note, since your network input must always be of the same shape, we are actually going to lose one character from the seed on every iteration of this process. Here is a simple visualization:

At every iteration, the model is basically making a prediction what is the next most likely character given the seed characters, or using conditional probability, this can be described like finding the maximum P(new_char|seed) , where new_char is any character from the alphabet. In our case, the alphabet is a set of all english letters, and a space character.(Note, your alphabet can be very different and can contain any characters that you want, depends on language that you are building the model for)
Word-level model
Word level model is almost the same as the character one, but it generates the next word instead of the next character. Here is a simple example:

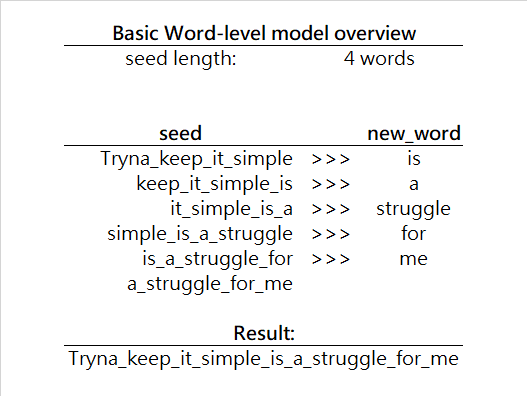
Now, in this model, we are looking ahead by one unit, but this time our unit is a word, not a character. So, we are looking for P(new_word|seed) , where new_word is any word from our vocabulary.
Notice, that now we are searching through a much larger set than before. With alphabet, we searched through approximately 30 items, now we are searching through many more items at every iteration, hence the word-level algorithm is slower on every iteration, but since we are generating a whole word instead of a single character, it is actually not that bad at all. As a final note on our Word-level model, we can have a very diverse vocabulary and we usually develop it by finding all unique words from our dataset (usually done in data preprocessing stage). Since vocabularies can get infinitely large, there are many techniques that improve the efficiency of algorithm, such as Word-Embeddings, but that is for a later article.
For the purposes of this article, I’m going to focus on the character level model because it is simpler in its implementation and understanding of Character-level model can be easily transferred to a more complex Word-level model later. As, I’m writing this, I have also built a Word-level model and will attach a link to it as soon as I’m done the write up [here] (or you can follow me to stay updated ?)