
Question Answering on Knowledge Bases and Text using Universal Schema and Memory Networks
來源: ACL2017短文
關鍵詞:imaging captioning; attention mechanism
原文
# Motivation
mermaid
graph LR
QA---KBQA(knowledge based)
QA---raw_text(raw text)
KBQA(knowledge based)---基於符號表示
KBQA(knowledge based)---基於深度學習
KBQA的效能會受到知識圖譜不完整的影響,text的資訊更多,但是非結構化的。
這個問題的難點在於如何將將兩個不同來源的資訊轉換成統一的編碼。
作者想到了使用Universal schema
Given a question q with words w1 , w2 , … , wn , where these words contain one blank and at least one entity, our goal is to fill in this blank with an answer entity q a using a knowledge base K and text T .
Method
Memory
對於知識庫,設(s,r,o)為KB中的一個triple,key:由
Question Encoder

Attention over cells
這裡採用點積模型計算注意力。
為了實現更新複雜的計算,我們可以讓主網路和外部記憶進行多輪互動,即多跳(Multi-Hop)操作。在第 k 輪互動中,主網路根據上次從外部記憶中讀取的資訊,產生新的查詢向量。

Experiments
該部分開始有對各類問答資料集的介紹,可以參考。
A limitation of this dataset is that it contains only the sentences that have entities connected by at least one relation in Freebase, making it skewed towards Freebase as we will see (§ 4.4).
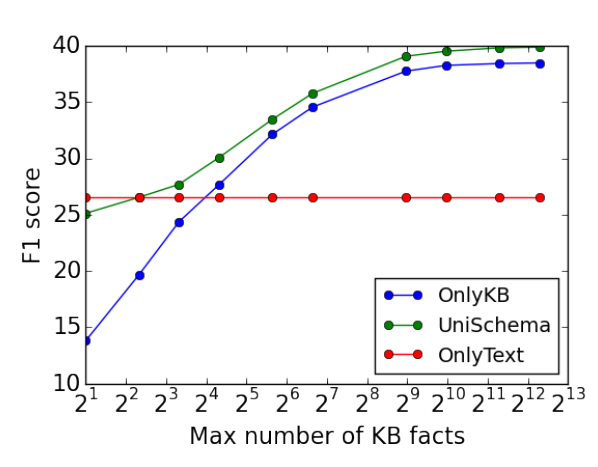
結論與思考
本文在幾乎不需要任何手工定義的特徵(hand- crafted features),也不需要藉助詞彙對映表,詞性標註,依存樹等條件下取得了當時很好的效果。 思考:KB and text exploited together的想法很久之前就有,只不過效果一般;Our model is a key-value MemNN with universal schema as its memory,並且只提供了一個數據集上的結果。但兩者結合解決該問題是創新點,並且在某個資料集上表現最好。