
Netflix at Spark+AI Summit 2018
Netflix at Spark+AI Summit 2018
A glimpse at Spark usage for Netflix Recommendations
Apache Spark has been an immensely popular big data platform for distributed computing. Netflix has been using Spark extensively for various batch and stream-processed workloads. A substantial list of use cases for Spark computation come from the various applications in the domain of content recommendations and personalization. A majority of the machine learning pipelines for member personalization run atop large managed Spark clusters. These models form the basis of the recommender system that backs the various personalized canvases you see on the Netflix app including, title relevance ranking, row selection & sorting, and artwork personalization among others.
Spark provides the computation infrastructure to help develop the models through data preparation, feature extraction, training, and model selection. The Personalization Infrastructure team has been helping scale Spark applications in this domain for the last several years. We believe strongly in sharing our learnings with the broader Spark community and at this year’s Spark +AI Summit in San Francisco, we had the opportunity to do so via three different talks on projects using Spark at Netflix scale. This post summarizes the three talks.
Fact Store for Netflix Recommendations (Nitin Sharma, Kedar Sadekar)
The first talk cataloged our journey building training data infrastructure for personalization models — how we built a fact store for extracting features in an ever-evolving landscape of new requirements. To improve the quality of our personalized recommendations, we try an idea offline using historical data. Ideas that improve our offline metrics are then pushed as A/B tests which are measured through statistically significant improvements in core metrics such as member engagement, satisfaction, and retention. The heart of such offline analyses are historical facts (for example, viewing history of a member, videos in ‘My List’ etc) that are used to generate features required by the machine learning model. Ensuring we capture enough fact data to cover all stratification needs of various experiments and guarantee that the data we serve is temporally accurate is an important requirement.
In the talk, we presented the key requirements, evolution of our fact store design, its push-based architecture, the scaling efforts, and our learnings.

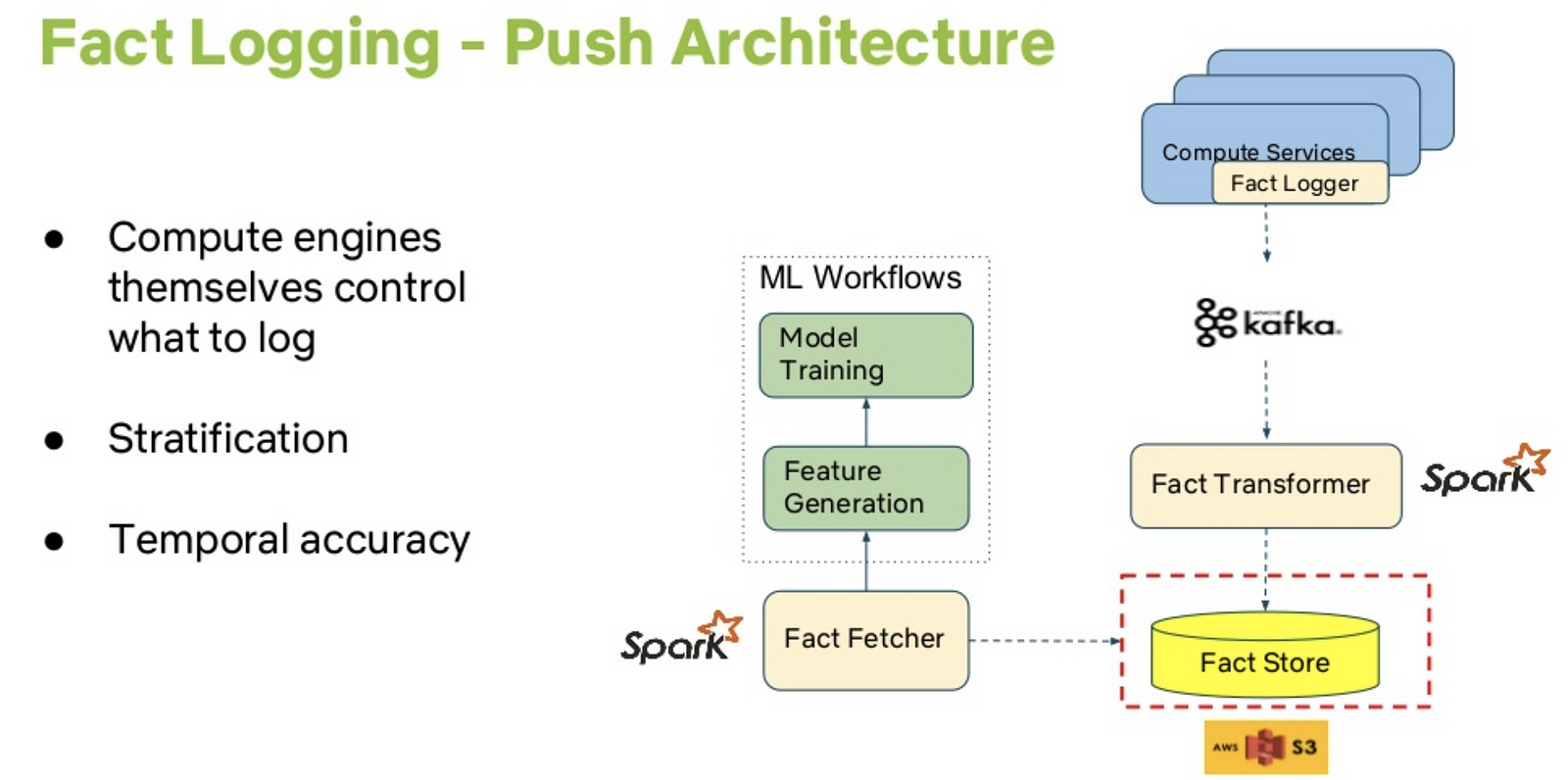
We discussed how we use Spark extensively for data processing for this fact store and delved into the design tradeoffs of fast access versus efficient storage.
Near Real-time Recommendations with Spark Streaming (Elliot Chow, Nitin Sharma)
Many recommendations for the personalization use cases at Netflix are precomputed in a batch processing fashion, but that may not be quick enough for time sensitive use cases that need to take into account member interactions, trending popularity, and new show launch promotions. With an ever-growing Netflix catalog, finding the right content for our audience in near real-time is a necessary element to providing the best personalized experience.
Our second talk delved into the realtime Spark Streaming ecosystem we have built at Netflix to provide this near-line ML Infrastructure. This talk was contextualized by a couple of product use cases using this near-real-time (NRT) infrastructure, specifically how we select the personalized video to present on the Billboard (large canvas at the top of the page), and how we select the personalized artwork for any title given the right canvas. We also reflected upon the lessons learnt while building a high volume infrastructure on top of Spark Streaming.

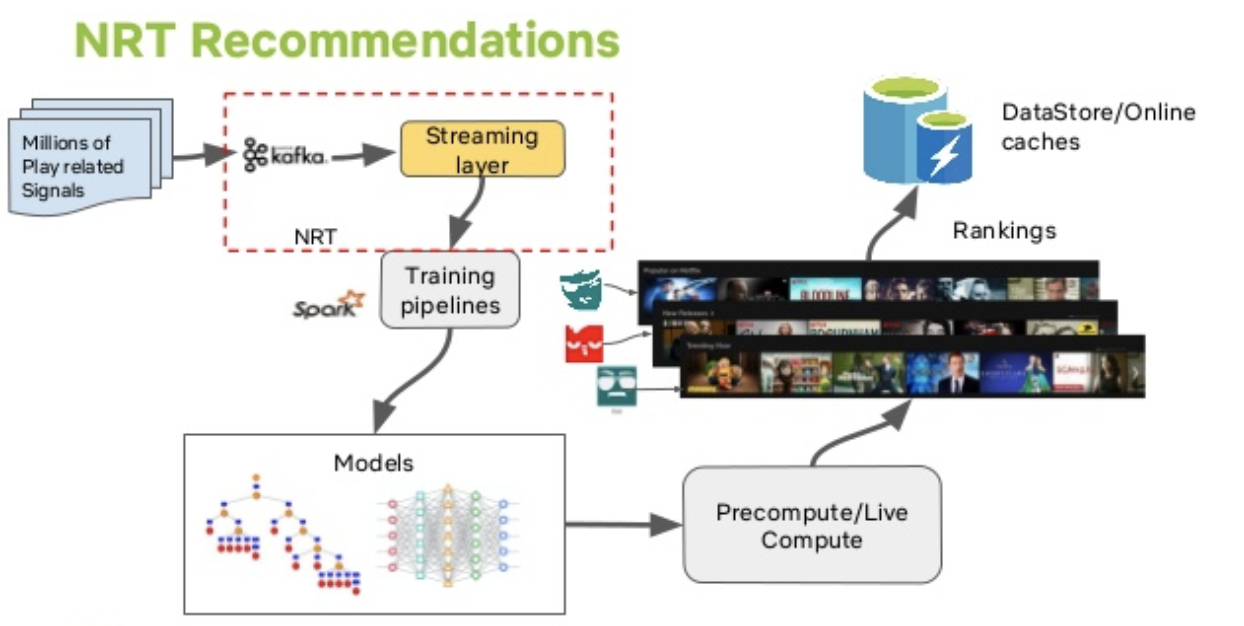
With regards to the infrastructure, we talked about:
- Scale challenges with Spark Streaming
- State management that we had to build on top of Spark
- Data persistence
- Resiliency, Metrics, and Operational Auto-remediation
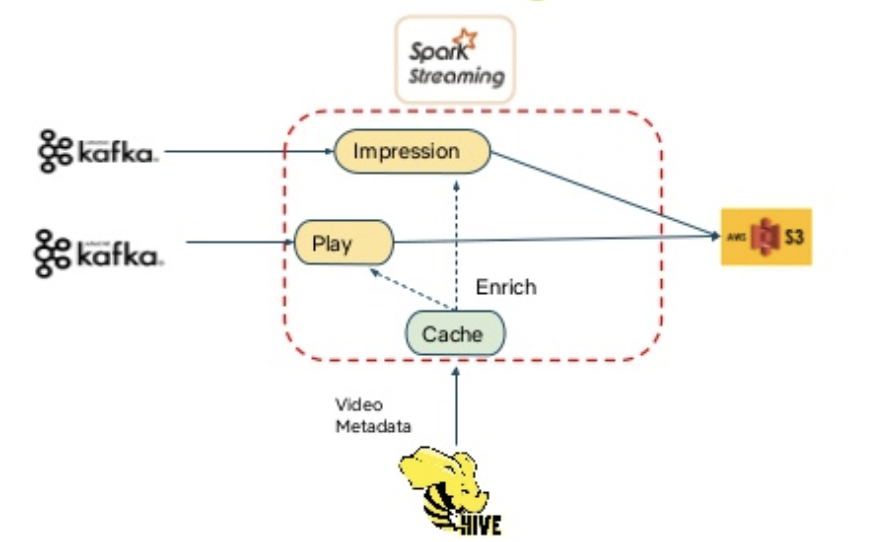
Spark-based Stratification library for ML use cases (Shiva Chaitanya)
Our last talk introduced a specific Spark based library that we built to help with stratification of the training sets used for offline machine learning workflows. This allows us to better model our users’ behaviors and provide them great personalized video recommendations.
This library was originally created to implement user selection algorithms in our training data snapshotting infrastructure, but it has evolved to cater to the general-purpose stratification use cases in ML pipelines. The main idea here is to be able to provide a mechanism for down-sampling the data set while still maintaining the desired constraints on the data distribution. We described the flexible stratification API on top of Spark Dataframes.

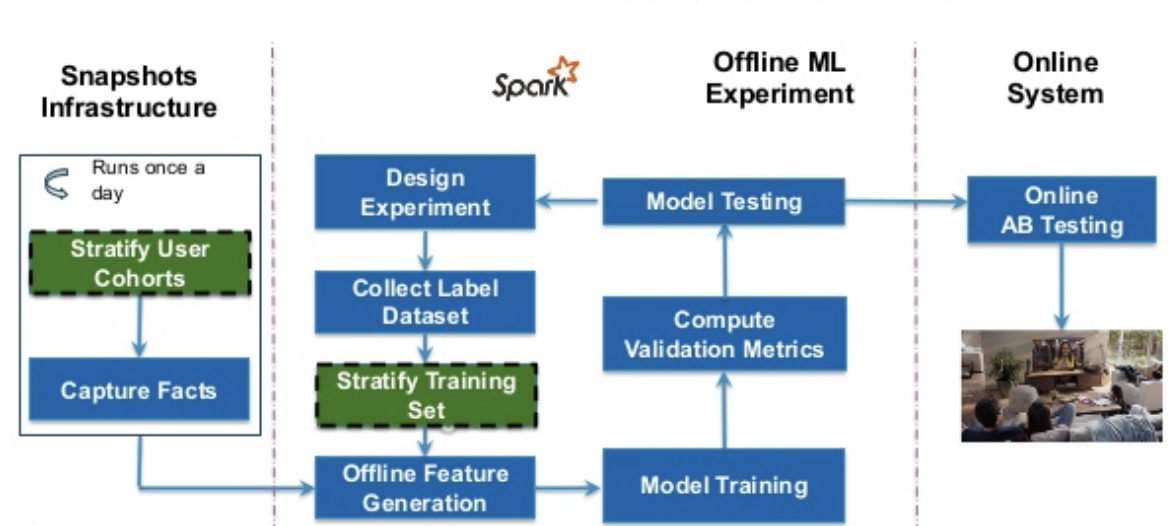
Choosing Spark+Scala gave us strong type safety in a distributed computing environment. We gave some examples of how, using the library’s DSL one can easily express complex sampling rules.


These talks presented a few glimpses of the Spark usage from the Personalization use cases at Netflix. Spark is also used for many other data processing, ETL, and analytical uses in many other different domains in Netflix. Each domain brings its unique sets of challenges. For the member-facing personalization domain, the infrastructure needs to scale at the level of member scale. That means, for our over 125 million members and each of their active profiles, we need to personalize our content and do so reasonably fast for it to be relevant and timely.
While Spark provides a great horizontally-scalable compute platform, we have found that using some of the advanced features, like code-gen for example, at our scale often poses interesting technical challenges. As Spark’s popularity grows, the project will need to continue to evolve to meet the growing hunger for truly big data sets and do a better job at providing transparency and ease of debugging for the workloads running on it.
This is where sharing lessons from one organization can help benefit the community-at-large. We are happy to share our experiences at such conferences and welcome the ongoing interchange of ideas on making Spark better for modern ML and big data infrastructure use cases.