
AI Challenger 2018 農作物病害細粒度分類-----Pytorch 深度學習實戰
AI Challenger 2018 農作物病害細粒度分類
1 前言
前言
本文以AI Challenger 2018 農作物病害細粒度分類為例,比賽詳細資訊和資料見文末,基於Pytorch 0.4.0 構建專案 其中模型訓練部分是在jupyter中完成 因此沒有將整個訓練過程封裝為可執行的py檔案,做這個比賽的初衷是熟悉一下pytorch,還有就是了解一下打比賽的整個流程,在過程中排名一度還不錯 讓自己產生了可能能拿獎的錯覺 果然還是年輕啊 第一次打比賽還想拿獎 最終acc 在0.883 如果有好心的大佬能夠告訴我這個怎麼調參調到0.89以上 十分感謝
不過通過這次比賽 讓自己學習到了很多程式設計的技巧 熟悉了流程 收穫還是很大的 有想要一起打比賽的小夥伴可以組隊呀。下面就將這次比賽的整個流程的收穫做一下總結,方便日後參考,同時也能夠作為一份真正的實戰指導,雖然做的菜 但總歸有可以借鑑的地方.
程式碼組織結構
在使用pytroch過程中可以將整個流程分為如下部分:資料分析過程(EDA), 引數定義 ,資料載入過程,資料處理 Data Augmentation和TTA(Test Time Augmentation),模型定義,訓練過程定義,驗證過程定義,測試過程定義,log定義與訓練過程視覺化 ,模型融合。 大致可以分為上述部分,每一部分在下文中做具體展開。
整體程式碼結構如下:
• code ▫CropModel.py ▫CropDataSet.py ▫utils.py ...... • config ▫config.py • data ▫trainData ▫validationData ▫testData • model ▫ResNet50 ▫2018-11-03_acc.pth • feature ▫ ResNet50 ▫ val_all_prediction.pth ▫ val_crop_prediction.pth ▫ test_all_prediction.pth ...... • log ▫ 2018-11-01 ▫ ResNet50 ▫ tensorBoardX ▫ logtxt ▫ ResNet 101 ▫ 2018-11-02 • submision: ▫ 2018-11-02
在這次比賽中我發現良好的程式碼組織以及模型組織是必不可少的,只有這樣才能更好的實現源源不斷的idea的修改,使得程式碼不至於不可控,上述程式碼組織結構是這次比賽摸索出來的,肯定還有不好的地方 需要之後實踐中不斷修改。
code : 存放專案程式碼其中CropModel .py 將專案使用到的所有模型進行封裝 ,CropDataSet .py 存放資料載入類以及不同的transform的方法 ,utils存放各種工具方法
data:在data中下分三個資料夾 trainData ,testData,validationData 每個資料夾下面存放著對應的annotation.json以及img資料夾儲存影象
model
feature:feature資料夾儲存TTA之後生成的結果(之所以稱為feature 是在stacking的時候 第二層的演算法是將第一次演算法結果作為特徵的 所以這裡就使用feature來命名這些TTA的結果)
log:儲存tensorboardX生成的訓練過程圖 以及自定義的訓練過程中的log輸出。在這次比賽中沒有儲存log輸出而是使用jupyter 直接打印出來 這樣做是有風險的 不利於log的回溯 同時如果jupyter斷開與伺服器的連線 那麼log資訊就會丟失
submission:儲存提交結果
完整流程解析
EDA
對於該問題EDA相對而言較為簡單 可以分為如下幾個步驟
1.將annotation轉化為pandas格式
2.查詢trainData validateData testData中是否有缺失值存在
3.生成各類樣本數量分佈圖 並按樣本數量大小排序
4. 展示若干樣本影象
首先通過使用matplotlib 和pandas 對資料進行簡單的統計和視覺化
注 matplotlib 可能會出現中文註解亂碼的問題 可以通過下述程式碼解決
import matplotlib
matplotlib.rcParams[u'font.sans-serif'] = ['simhei']
matplotlib.rcParams['axes.unicode_minus'] = False
將json檔案轉化為pandas
with open("../data/AgriculturalDisease_trainingset/AgriculturalDisease_train_annotations.json") as datafile1:
trainDataFram=pd.read_json(datafile1,orient='records')
with open("../data/AgriculturalDisease_validationset/AgriculturalDisease_validation_annotations.json") as datafile2: #first check if it's a valid json file or not
validateDataFram =pd.read_json(datafile2,orient='records')
檢視資料中Null的分佈情況:
total=trainDataFram.isnull().sum().sort_values(ascending=False)
percent=(trainDataFram.isnull().sum())/(trainDataFram.isnull().count()).sort_values(ascending = False)
missing_validation_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'],sort=False)
missing_validation_data.head()

檢視資料分佈情況
dataDistribute=trainDataFram.groupby(by=['disease_class']).size()
plt.figure(figsize=(50,20),dpi=100)
plt.xticks(range(len(dataDistribute)),dataDistribution.index.tolist(),fontsize=40)
plt.yticks(fontsize=40)
bar=plt.bar(dataDistribution.index.tolist(), dataDistribute.tolist(),width=0.7)
for b in bar:
h=b.get_height()
plt.text(b.get_x()+b.get_width()/2,h,int(h),ha='center',fontsize=30)
plt.show()

validate data

由此可見在訓練過程中可以將44,45 label刪除 提升正確率
根據資料量的大小排序
trainDataFram['disease_class'].value_counts().plot(kind='bar',figsize=(60,30),fontsize =60,title="Number of Training Examples Versus Class").title.set_size(80)

按大小排列同時在柱狀圖上增加資料量大小
dataDistribute=trainDataFram['disease_class'].value_counts()
plt.figure(figsize=(50,20),dpi=100)
plt.xticks(range(len(dataDistribute)),dataDistribute.index.tolist(),fontsize=40) #第一個引數是在哪些位置需要放置座標值 第二個引數是放置的座標值大小
plt.yticks(fontsize=40)
bar=plt.bar(range(len(dataDistribute)),dataDistribute.tolist(),width=0.6)
for b in bar:
h=b.get_height()
plt.text(b.get_x()+b.get_width()/2,h,int(h),ha='center',fontsize=25)
plt.show()

檢視trainDataSet和Validate DataSet資料分佈
f,(ax0,ax1)=plt.subplots(1,2,sharey=True,figsize=(15,5))
ax0.hist(trainDataFram['disease_class'].value_counts())
ax0.set_xlabel("# images per class")
ax0.set_ylabel("# classes")
ax0.set_title('Class distribution for Train')
ax1.hist(validateDataFram['disease_class'].value_counts())
ax1.set_xlabel("# images per class")
ax1.set_title('Class distribution for Validation')

引數定義
1.對於引數定義可以在每一個jupyter中進行定義
2.也可以將所有的引數在一個Config類中進行定義
要注意在使用jupyter訓練多個模型的時候不要通過一個函式 不同模型修改不同引數來進行 要建立多個jupyter 每一個jupyter訓練一個模型 這樣能夠儲存訓練時候的程式碼清晰 不然想要通過封裝一個函式 不用模型進行不同引數的呼叫會使得程式碼越來越亂 (畢竟不同模型要修改的引數還是很多的)
如果不想把這些引數都寫到模型的jupyter中 可以通過定義一個Config 基類 不同模型繼承這個基類 並重寫部分引數 保證每個模型有一個獨立的Config。
另一點要注意的是 對於隨機種子的設定 為了能夠復現出訓練結果 需要儲存隨機種子的值
同時由於config資料夾和code資料夾不在同一個目錄下 為了能夠在code資料夾下的py檔案中引用config資料夾下的py檔案 需要使用如下命令 將…/config/ 新增到系統路徑中去
import sys
sys.path.append('../config/')
import datetime
class BaseConfig():
def __init__(self,modelName):
#模型名稱
self.modelName=modelName
#各個儲存路徑名稱
self.img_train_pre='../data/AgriculturalDisease_trainingset/images/'
self.img_val_pre='../data/AgriculturalDisease_validationset/images/'
self.img_test_pre='../data/AgriculturalDisease_testA/images/'
self.annotation_train='../data/AgriculturalDisease_trainingset/AgriculturalDisease_train_annotations.json'
self.annotation_val='../data/AgriculturalDisease_validationset/AgriculturalDisease_validation_annotations.json'
#當前時間
self.date=str(datetime.date.today())
self.tensorBoard_path='../log/'+self.date+'/'+self.modelName+'/'+'tensorBoardX/'
self.txtLog_path='../log/'+self.date+'/'+self.modelName+'/'+'txtLog/'+self.date+'_train.txt'
self.best_acc_path='../model/'+self.date+'/'+self.modelName+'/'+self.date+'_acc.pth'
self.best_loss_path='../model/'+self.date+'/'+self.modelName+'/'+self.date+'_loss.pth'
self.submit_path='../submit/'+self.date+'/result.json'
self.SEED=666
self.img_size=229
self.batch_size=64
self.num_class=61
class ResNet50Config(BaseConfig):
def __init__(self):
super().__init__('Resnet50')
self.img_size=224
resnet50Config=ResNet50Config()
資料載入過程
具體可參考pytorch資料載入過程詳解
pytorch 通用的資料載入是通過定義自己的資料載入類 並繼承torch.utils.data.Dataset類 並重寫其中的 init len 和getitem方法
def default_loader(path):
return Image.open(path).convert('RGB')
class MyDataSet(Dataset):
def __init__(self,json_Description,transform=None,target_transform=None,loader=default_loader,path_pre=None):
description=open(json_Description,'r')
imgs=json.load(description)
image_path=[element['image_id'] for element in imgs]
image_label=[element['disease_class'] for element in imgs]
imgs_Norm=list(zip(image_path,image_label))
self.imgs=imgs_Norm
self.transform=transform
self.target_transform=target_transform
self.loader=loader
self.path_pre=path_pre
def __getitem__(self,index):
path,label=self.imgs[index]
img=self.loader(self.path_pre+path)
if self.transform is not None:
img=self.transform(img)
if self.target_transform is not None:
label=self.target_transform(label)
return img,label
def __len__(self):
return len(self.imgs)
重寫init方法是將不同表現形式的資料如json資料讀取並解析成(資料,label)對的形式方便getitem函式使用
重寫getitem函式是將init中(資料,label)對取出索引為index的資料 此時的資料可能只是儲存路徑,因此經過PIL或者Opencv等等 (注意兩者channel順序不同 PIL是 rgb 順序 opencv為gbr順序使用,cv2.cvtColor(img,cv2.COLOR_BGR2RGB) 對opencv讀取資料進行修改)讀取影象 並經過transforms處理返回該index 的(影象,label)對
重寫len方法得到資料大小
除此之外 我還習慣將不同型別的transforms 也和Dataset讀取定義在同一個py檔案中
normalize_torch = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
normalize_05 = transforms.Normalize(
mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]
)
normalize_dataset=transforms.Normalize(
mean=[0.463,0.400, 0.486],
std= [0.191,0.212, 0.170]
)
def preprocesswithoutNorm(image_size):
return transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.ToTensor()
])
def preprocess(normalize, image_size):
return transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.ToTensor(),
normalize
])
def preprocess_hflip(normalize, image_size):
return transforms.Compose([
transforms.Resize((image_size, image_size)),
HorizontalFlip(),
transforms.ToTensor(),
normalize
])
def preprocess_with_augmentation(normalize, image_size):
return transforms.Compose([
transforms.Resize((image_size + 20, image_size + 20)),
transforms.RandomRotation(15, expand=True),
transforms.RandomCrop((image_size, image_size)),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.4,
contrast=0.4,
saturation=0.4,
hue=0.2),
transforms.ToTensor(),
normalize
])
一般會定義三個normalize,分別為mean std為0.5 ,ImageNet的mean和std 以及 使用的資料集的std和mean
下面的程式碼對於資料集不是特別大的時候可以使用求資料集上的mean和std 如果特別大可以分塊使用
import tqdm
import cv2
import pandas as pd
import numpy as np
# 訓練樣本和訓練樣本對應的label路徑
trainImgPre='../data/AgriculturalDisease_trainingset/images/'
trainAnnotation='../data/AgriculturalDisease_trainingset/AgriculturalDisease_train_annotations.json'
RESIZE_SIZE=256
CROP_SIZE=224
if __name__=='__main__':
data=[]
with open(trainAnnotation) as datafile1:
trainDataFram=pd.read_json(datafile1,orient='records')
i=0
# for fileName in tqdm_notebook(trainDataFram['image_id'],miniters=256):
for fileName in trainDataFram['image_id']:
img=cv2.imread(trainImgPre+fileName)
data.append(cv2.resize(img,(CROP_SIZE,CROP_SIZE)))
i=i+1
print(i)
data = np.array(data, np.float32) / 255 # Must use float32 at least otherwise we get over float16 limits
print("Shape: ", data.shape)
means = []
stdevs = []
for i in range(3):
pixels = data[:,:,:,i].ravel()
means.append(np.mean(pixels))
stdevs.append(np.std(pixels))
print("means: {}".format(means))
print("stdevs: {}".format(stdevs))
print('transforms.Normalize(mean = {}, std = {})'.format(means, stdevs))
同時在batch size相對較大的時候可以使用在輸入層增加一個BN層 代替全域性的mean和std 可能會有不錯的效果
資料處理 Data Augmentation 和TTA
在本次比賽中對於資料的處理其實沒有太多的設計,主要就是在訓練時的data augmentation ,對類別不均衡樣本的處理 以及在測試的時候的TTA
離線資料增強的方法:
imgaug
augmentor
Augmentation 方法
線上資料增強:
在pytorch中transforms封裝了線上資料增強的方法
對於不均衡樣本的處理:
1.LabelShuffling
首先對原始的影象label檔案按照label順序進行排序 在這裡為AgriculturalDisease_train_annotations.json 按照disease_class 的順序進行排序,
(1)計算各個label數量,並得到樣本數量最多的label對應的樣本數目
(2)根據最大類別數目對每一類產生一個隨機排列的列表
(3)用列表中的數目對每一個類別數目取餘得到索引值 並根據該索引值
(4)然後把所有類別的隨機列表連在一起,做個Random Shuffling,得到最後的影象列表,用這個列表進行訓練

labels=dataFrame.groupby(by=[groupByName]).siez() #獲取每個類別groupby之後的資料數目 Series型別 index為類別名稱 values為每一個類別的數目
maxNum=max(labels)
tmpLabels=np.array(range(maxNum)) #生成maxNum數目的陣列
randomTmpLabels=np.random.permutation(tmpLabels)#將上述陣列打亂順序
targetGroup=trainDataFram.groupby(by=['disease_class']).get_group(groupByName) #根據groupBy的名稱獲取一個group
targetGroup.iloc[randomTmpLabels%labels[i]] # pandas中讀取行分為通過行索引進行讀取以及通過行號索引進行讀取 通過行索引進行讀取使用.loc[] 函式 通過行號索引進行讀取使用 .iloc[]
def labelShuffling(dataFrame,outputPaht="../data/AgriculturalDisease_trainingset/",outputName="AgriculturalDisease_train_Shuffling_annotations.json",groupByName='disease_class'):
groupDataFrame=dataFrame.groupby(by=[groupByName])
labels=groupDataFrame.size()
print("length of label is ",len(labels))
maxNum=max(labels)
lst=pd.DataFrame(columns=["disease_class","image_id"])
for i in range(len(labels)):
print("Processing label :",i)
tmpGroupBy=groupDataFrame.get_group(i)
createdShuffleLabels=np.random.permutation(np.array(range(maxNum)))%labels[i]
print("Num of the label is : ",labels[i])
lst=lst.append(tmpGroupBy.iloc[createdShuffleLabels],ignore_index=True)
print("Done")
lst.to_json(outputPaht+outputName,orient="records",force_ascii=False) # 在這裡因為路徑中存在中文 所以需要將force_ascii 設定為false
2.在這次比賽中存在一個問題就是沒有做K折交叉驗證 這樣使得做第二層stacking的時候會出現資料量不足的問題 同時對於得到的結果也會出現不穩定的問題 最後正確率差距都在千分位上 在本地測試結果較好不一定在線上結果要好 如果做交叉驗證 可以使得結果更加穩定
3.使用帶權重的懲罰
from sklearn.utils import class_weight
class_weight = class_weight.compute_class_weight('balanced',
np.unique(y_train),
y_train)
4.使用訓練集各個label概率與測試集各個label概率進行結果微調 對label進行微調 (該方法適用於訓練樣本和測試樣本分佈不同的時候 因為這次比賽訓練樣本和測試樣本的分佈基本相近 所有該方法效果不是特別穩定)
首先對於二分類而言 由貝葉斯公式可知
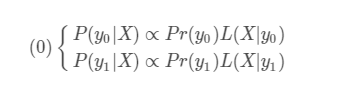
其中 P(y0 | X )代表對於X的預測結果 Pr(y0)代表y0的先驗概率 L(X|y0)代表X和y0之間的似然函式 這裡就是我們訓練所得的預測函式
對於使用訓練集合驗證集 似然函式是相同的,但是由於不同資料的先驗不同 那麼我們得到的P(y0 | X )也不同
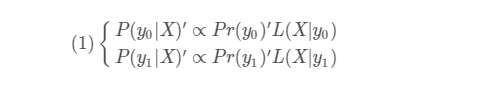
這裡的 P(y0 | X )'是我們要求得的測試集(或者線上下測試時的驗證集)的概率,
又因為L一定,所以:
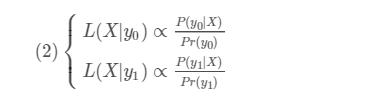
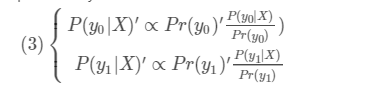
對於多類也是一樣的 我們可把當前處理的類看做y0 ,其他類看做y1
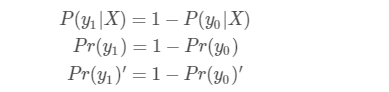
def calibrate_probs(train_df,val_df,prob,NB_CLASS):
calibrated_prob = np.zeros_like(prob)
nb_train = train_df.shape[0]
for class_ in range(NB_CLASS): # enumerate all classes 這裡有61類 其他
prior_y0_train = (train_df['disease_class'] == class_).mean() #類別為class_的先驗
prior_y1_train = 1 - prior_y0_train
prior_y0_test=(val_df['disease_class'] ==class_).mean()
prior_y1_test=1-prior_y0_test
for i in range(prob.shape[0]): # enumerate every probability for a class
predicted_prob_y0 = prob[i, class_]
calibrated_prob_y0 = calibrate(
prior_y0_train, prior_y0_test,
prior_y1_train, prior_y1_test,
predicted_prob_y0)
calibrated_prob[i, class_] = calibrated_prob_y0
return calibrated_prob
def calibrate(prior_y0_train, prior_y0_test,
prior_y1_train, prior_y1_test,
predicted_prob_y0):
predicted_prob_y1 = (1 - predicted_prob_y0)
p_y0 = prior_y0_test * (predicted_prob_y0 / prior_y0_train)
p_y1 = prior_y1_test * (predicted_prob_y1 / prior_y1_train)
return p_y0 / (p_y0 + p_y1) # normalization
TTA
Test Time Augmentation,可以通過多次嘗試不同的TTA方法 因為不能夠保證每一次的TTA都是對結構有正作用,需要根據資料特性和模型選擇不同TTA(其實我也不同清楚選擇TTA的標準化流程 只能通過不斷試驗 希望大佬可以告知TTA 一般化選擇的方法 )
這裡做TTA的時候主要是使用了翻轉和5個位置切割。注: 在寫深度學習程式碼的時候 一定要多用assert斷言來驗證維度數量 ,每個維度的大小 等等是否和預期的相同 ,尤其是在forward函式中 很關鍵
import numbers
import torchvision.transforms.functional as F
from torchvision.transforms import transforms
class HorizontalFlip(object):
"""Horizontally flip the given PIL Image."""
def __call__(self, img):
"""
Args:
img (PIL Image): Image to be flipped.
Returns:
PIL Image: Flipped image.
"""
return F.hflip(img)
def five_crop(img, size, crop_pos):
if isinstance(size, numbers.Number):
size = (int(size), int(size))
else:
assert len(size) == 2, "Please provide only two dimensions (h, w) for size."
w, h = img.size
crop_h, crop_w = size
if crop_w > w or crop_h > h:
raise ValueError("Requested crop size {} is bigger than input size {}".format(size,
(h, w)))
if crop_pos == 0:
return img.crop((0, 0, crop_w, crop_h))
elif crop_pos == 1:
return img.crop((w - crop_w, 0, w, crop_h))
elif crop_pos == 2:
return img.crop((0, h - crop_h, crop_w, h))
elif crop_pos == 3:
return img.crop((w - crop_w, h - crop_h, w, h))
else:
return F.center_crop(img, (crop_h, crop_w))
class FiveCropParametrized(object):
def __init__(self, size, crop_pos):
self.size = size
self.crop_pos = crop_pos
if isinstance(size, numbers.Number):
self.size = (int(size), int(size))
else:
assert len(size) == 2, "Please provide only two dimensions (h, w) for size."
self.size = size
def __call__(self, img):
return five_crop(img, self.size, self.crop_pos)
模型定義
在模型定義的時候習慣將多個模型寫在一個py檔案中 方便呼叫 這裡使用的模型主要是來自 torchvision.models和pretrained models將這些model做一個封裝
class ResNetFinetune(nn.Module):
finetune = True
def __init__(self, num_classes, net_cls=M.resnet50, dropout=False):
super().__init__()
self.net = net_cls(pretrained=True)
if dropout:
self.net.fc = nn.Sequential(
nn.Dropout(),
nn.Linear(self.net.fc.in_features, num_classes),
)
else:
self.net.avgpool=nn.AdaptiveAvgPool2d(2) ##如果不想限制輸入的大小 可以修改網路的池化層
self.net.fc = nn.Linear(self.net.fc.in_features*4, num_classes) # 修改全連線層 輸出目標數量的結果
def fresh_params(self): #可以在這裡增加其他函式 獲取不同層級的引數等 方便之後設定不同的學習率
return self.net.fc.parameters()
def forward(self, x):
return self.net(x)
class FinetunePretrainedmodels(nn.Module):
finetune = True
def __init__(self, num_classes: int, net_cls, net_kwards):
super().__init__()
self.net = net_cls(**net_kwards)
self.net.last_linear = nn.Linear(self.net.last_linear.in_features, num_classes)
def fresh_params(self):
return self.net.last_linear.parameters()
def forward(self, x):
return self.net(x)
resnet18_finetune = partial(ResNetFinetune, net_cls=M.resnet18) #通過partial固定部分引數 同時保留部分引數
resnet34_finetune = partial(ResNetFinetune, net_cls=M.resnet34)
nasnet_finetune = partial(FinetunePretrainedmodels,
net_cls=pretrainedmodels.nasnetalarge,
net_kwards={'pretrained': 'imagenet', 'num_classes': 1000})
其中對於修改網路結構可參見 ResNet網路結構解析
對於上述**這種引數傳遞的方式可參見 * 和 ** 解析
在載入model的時候 可以通過如下的方式載入:
def getmodel():
print('[+] loading model... ', end='', flush=True)
model=CropModels.resnet50_finetune(NB_CLASS)
model.cuda()
print('Done')
return model
訓練過程定義
為每一個模型構建以ipynb 用來儲存訓練過程 每個模型中有3個用以訓練的函式 train ,reuseTrain,TrainWithRawData 。具體程式碼見github 首先設定好隨機種子 方便之後的復現 並設定GPU編號random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed_all(SEED)
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
torch.backends.cudnn.benchmark = True
訓練策略:
- Train FC adam (LR 0.001-> 0.00001)
- Polishing, only FC SGD (LR 0.001 -> 0.00001)
- Train full net Adam(LR 0.0001->收斂) 以loss是否下降為標準 連續3個epoch loss不下降 則lr減小十倍
- Train full net SGD (LR 1e-4 ---->收斂)以loss是否下降為標準 連續3個epoch loss不下降 則lr減小十倍
- Train without augs SGD LR 1e-4
可以嘗試在訓練過程中FC層的lr設定為其他層的10倍
使用帶權重的交叉熵作為損失函式,在整個訓練過程中 每300個batch 做一次記錄 並跑一遍驗證集
除了上述基本模型 有很多為細粒度分類專門設計的模型,在這次比賽中沒有嘗試這些模型 有時間可以跑一下試一試
模型融合
在這次比賽中做的不好的地方就是模型融合 使用stacking的方法進行模型融合後結果不增反降,使用gmeans 融合結果也只是稍有增加,可能是我對於stacking的做法有些問題
Stacking 介紹1
Stacking 介紹2
針對CNN不同整合策略
CNN with xgboost
使用LightGBM或xgboost (其實也可以試試 LR和Random Forest )對上述神經網路結果進行stacking
這裡不同的地方是可以借鑑 stacking with cnn的模型融合方法 在這裡實驗沒有什麼提升 可能是程式碼的問題
測試與結果提交
因為在結果預測的時候使用了TTA ,所以生成的最終預測結果是一個三維的矩陣 每一行是一個樣本 每一列代表預測的型別 而channel代表不同的TTA生成的對於不同樣本每一類的預測得分 比如使用5 crop 作為TTA那麼就會得到5個channeldef predictAll(model_name, model_class, weight_pth, image_size, normalize):
print(f'[+] predict {model_name}')
model = get_model(model_class)
model.load_state_dict(torch.load(weight_pth)['state_dict'])
model.eval()
print('load state dict done')
tta_preprocess = [preprocess(normalize, image_size), preprocess_hflip(normalize, image_size)]
tta_preprocess += make_transforms([transforms.Resize((image_size + 20, image_size + 20))],
[transforms.ToTensor(), normalize],
five_crops(image_size))
tta_preprocess += make_transforms([transforms.Resize((image_size + 20, image_size + 20))],
[HorizontalFlip(), transforms.ToTensor(), normalize],
five_crops(image_size))
print(f'[+] tta size: {len(tta_preprocess)}')
data_loaders = []
for transform in tta_preprocess:
test_dataset = MyDataSet(json_Description=ANNOTATION_VAL,transform=transform,path_pre=IMAGE_VAL_PRE)
data_loader = DataLoader(dataset=test_dataset, num_workers=16,
batch_size=BATCH_SIZE,
shuffle=False)
data_loaders.append(data_loader)
print('add transforms')
lx, px = utils.predict_tta(model, data_loaders)
data = {
'lx': lx.cpu(),
'px': px.cpu(),
}
if not os.path.exists('../feature/'+model_name):
os.makedirs('../feature/'+model_name)
torch.save(data, '../feature/'+model_name+'/val_all_prediction.pth')
print('Done'
其中使用到的predict,predicttta等都在utils中做了封裝
def predict(model, dataloader):
all_labels = []
all_outputs = []
model.eval()
with torch.no_grad():
for batch_idx, (inputs, labels) in enumerate(dataloader):
all_labels.append(labels)
inputs = Variable(inputs).cuda()
outputs = model(inputs)
all_outputs.append(outputs.data.cpu())
all_outputs = torch.cat(all_outputs)
all_labels = torch.cat(all_labels)
all_labels = all_labels.cuda()
all_outputs = all_outputs.cuda()
return all_labels, all_outputs
def safe_stack_2array(acc, a):
a = a.unsqueeze(-1) # 在最後一維擴充 unsqueeze用來擴充一維 squeeze用來壓縮維度為1的
if acc is None:
return a
return torch.cat((acc, a), dim=acc.dim() - 1)
def predict_tta(model, dataloaders):
prediction = None
lx = None
for dataloader in dataloaders:
lx, px = predict(model, dataloader)
print('predict finish')
prediction = safe_stack_2array(prediction, px)
return lx, prediction
log記錄,視覺化訓練過程及其他trick
1 使用tensorBoardX視覺化訓練過程
writer=SummaryWriter(Config.log) # 建立 /日期/模型名稱/TensorBoard的組織形式
writer.add_scalar('Val/Acc',accuracy,niter) #每次想要新增記錄點的時候呼叫 add_scalar 引數分別為 圖表名稱 記錄值 記錄點座標
writer.add_scalar('Val/Loss',log_loss,niter)
2.儲存log
class Logger(object):
def __init__(self):
self.terminal = sys.stdout #stdout
self.file = None
def open(self, file, mode=None):
if mode is None: mode ='w'
self.file = open(file, mode)
def write(self, message, is_terminal=1, is_file=1 ):
if '\r' in message: is_file=0
if is_terminal == 1:
self.terminal.write(message)
self.terminal.flush()
#time.sleep(1)
if is_file == 1:
self.file.write(message)
self.file.flush()
def flush(self):
# this flush method is needed for python 3 compatibility.
# this handles the flush command by doing nothing.
# you might want to specify some extra behavior here.
pass
#Log 呼叫
log = Logger()
log.open(config.logs + "log_train.txt",mode="a")
log.write("\n------------------------------------ [START %s] %s\n\n" % (datetime.now().strftime('%Y-%m-%d %H:%M:%S'), '-' * 40))
log.write('** start training here! **\n')
log.write(' |------------ VALID -------------|----------- TRAIN -------------| \n') #可以定製想要的log儲存內容
log.write('lr iter epoch | loss top-1 top-2 | loss top-1 top-2 | time \n')
log.write('----------------------------------------------------------------------------------------------------\n')
3.save check point
def snapshot(dir_path, run_name, state,key='loss'):
if key=='loss':
filePath=os.path.join(dir_path,run_name)
if not os.path.exists(filePath):
os.makedirs(filePath)
snapshot_file = os.path.join(dir_path,
run_name , date+'_loss_best.pth')
torch.save(state, snapshot_file)
else:
filePath=os.path.join(dir_path,run_name)
if not os.path.exists(filePath):
os.makedirs(filePath)
snapshot_file = os.path.join(dir_path,
run_name ,date+ '_acc_best.pth')
torch.save(state, snapshot_file)
#上述程式碼其實寫的很不好 可以稍加修改
utils.snapshot('../model/', 'ResNet50', {
'epoch': epoch + 1,
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict(),
'val_loss': log_loss,
'val_correct':accuracy })
4.定製執行時儲存內容
class RunningMean:
def __init__(self, value=0, count=0):
self.total_value = value
self.count = count
def update(self, value, count=1):
self.total_value += value
self.count += count
@property
def value(self):
if self.count:
return float(self.total_value)/ self.count
else:
return float("inf")
def __str__(self):
return str(self.value)
這些東西其實也可以不自己寫 下述程式碼庫模組化了這些內容 下次可以嘗試使用
心得與體會
打比賽最重要的還是要去嘗試 然後查詢之前是否有類似的比賽 從別人的程式碼中學習 不斷總結才能夠有所提高。
希望下次比賽能夠有一個好成績,這次比賽的地址和資料集下載地址如下:
比賽地址
資料集地址 密碼: 4ac2