
Encoding concepts, categories and classes for neural networks
Encoding concepts, categories and classes for neural networks

In a previous post, we explained how neural networks work to predict a continuous value (like house price) from several features. One of the questions we got is how neural networks can encode concepts, categories or classes. For instance, how can neural networks convert a number of pixels to a true/false answer whether or not the underlying picture contains a cat?
First, here are some observations:
- A binary classification problem is a problem ‘with a “Yes/No”’ answer. Some examples include: Does this picture contain a cat? Is this e-mail spam? Is this application a virus? Is this a question?
- A multi-classification problem is a problem with several categories as an answer, like: what type of vehicle is this (car/bus/truck/motorcycle)?
- Any multi-classification problem can be converted to a series of binary classifications. (like: Is this a car, yes or no? Is this a bus, yes or no? etc)
The core idea of classification in neural networks is to convert concepts, categories and classes into probabilities of belonging to these concepts, categories or classes.
Meaning that a cat is 100% cat. A dog is 100% dog. A car is 100% car, etc. Each independent concept by itself is a dimension in the conceptual space. So for instance, we can say:
- A cat is: 100% “cat”, 0% “dog”, 0% “bus”, 0% “car”. [1; 0; 0; 0]
- A car is: 0% “cat”, 0% “dog”, 0% “bus”, 100% “car”. [0; 0; 0; 1 ]
- A yes is 100% “yes”, 0% “no” -> [1; 0]
The vectorized representation of a category is then a 1 in the dimension representing this category and 0 in the rest. This schema is called 1-hot encoding.
With this idea in mid, we now have a new way to encode categories into classical multi-dimensional vectors. However these vectors have some special properties since they need to represent probabilities or confidence level of belonging to these categories:
- The vector length defines the number of categories the neural network can support.
- Each dimension should be bounded between 0 and 1.
- The sum over the vector should be always 1.
- The selected category is the one with the highest value/confidence level (arg max).
So, for instance, if we get as output [0.6, 0.1, 0.2, 0.1] over [cat, dog, bus, car] we can say that the neural network classified this image as a cat with a confidence level of 60% .
Softmax layer
While designing neural networks for classification problems, in order to maintain the properties of the probability vectors at the last layer, there is a special activation called “softmax”.
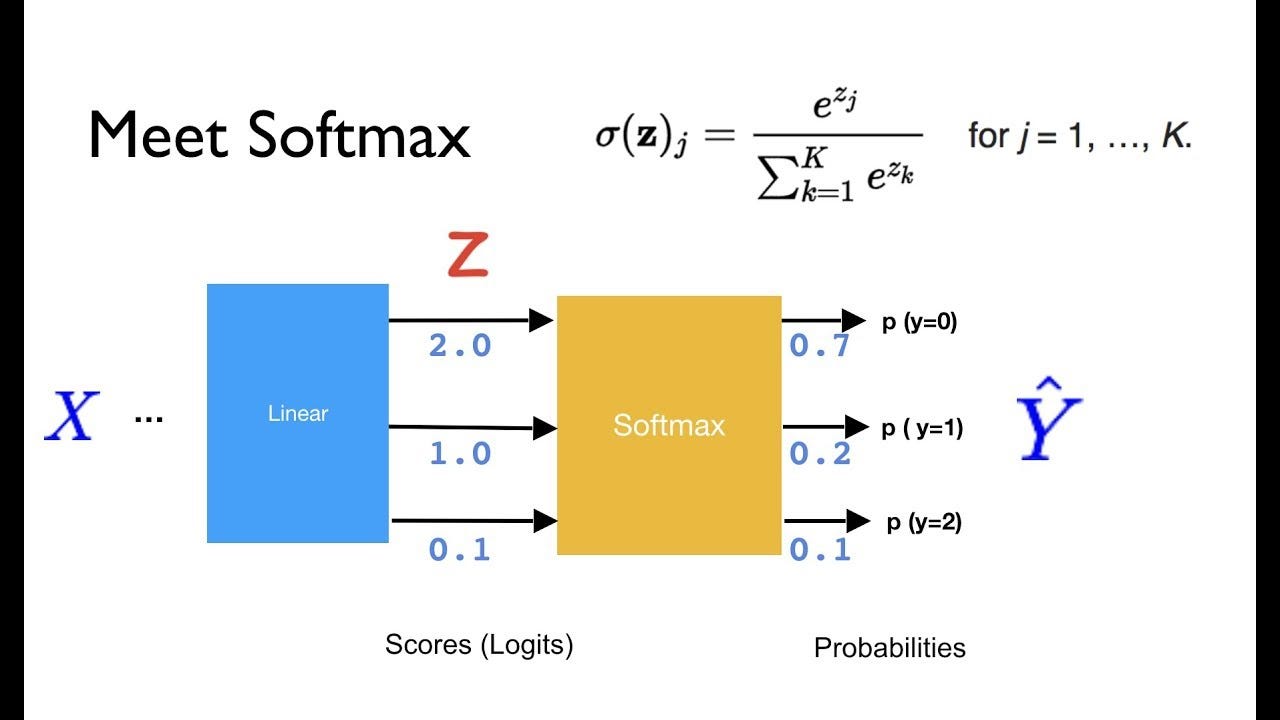
What the softmax does is that it takes any vector of numbers, exponentiates everything, then divides every element by the sum of the exponential.
[2 ; 1; 0.1] -> exponential [7.3; 2.7; 1.1] -> sum is 11.1 -> final vector is [0.66; 0.24; 0.1] (which is a probability-vector).
We can easily verify the following properties:
- Every component is between 0 and 1 since an exponential can’t be negative, and a division over the sum can’t be over 1.
- The sum of output always be equal to 1.
- The order is maintained: a higher initial score will lead to a higher probability.
- What matters is the relative score to each other. For instance if we have these 2 vectors: [10;10;10] or [200;200;200], they will both be converted to the same [1/3; 1/3; 1/3] probability.
The final step is to provide the loss function that triggers the backpropagation of the learning. Since the outputs are 1-hot encoded vectors, as presented earlier, the most suitable loss function is the log-loss function:

It is derived from information theory and Shannon entropy. Since the actual outputs y are either 0 or 1, the loss is accumulating the lack of confidence of the NN over the known categories.
- If the NN is very confident -> the probability of the correct class will be close to 1 -> the log will be close to 0 -> no loss -> no back-propagation -> no learning!
- If the NN is not very confident -> the probability will be close to 0 -> the log will be close to -infinity, the loss will be close to infinity -> Big loss -> Big opportunity to learn using back-propagation.
Calculating exponentials and logarithmics are computationally expensive. As we can see from the previous 2 parts, the softmax layer is raising the logit scores to exponential in order to get probability vectors, and then the loss function is doing the log to calculate the entropy of the loss.
If we combine these 2 stages in one layer, logarithmics and exponentials kind of cancel out each others, and we can get the same final result with much less computational resources. That’s why in many neural network frameworks and libraries there is a “softmax-log-loss” function, which is much more optimal than having the 2 functions separated.