
《Fluency Boost Learning and Inference for Neural Grammatical Error Correction》論文總結
阿新 • • 發佈:2019-02-08
核心思想
這篇論文的核心思想其實很簡單,就是通過有效地增加訓練資料,來使模型的推斷結果更加正確。具體就是使用模型推斷的n-best結果來生成新的訓練資料,用於訓練。
增加訓練資料這個步驟是很關鍵的。
傳統的做法
想到增加訓練資料,一個很正常的想法就是,人為製造一些含有錯誤資訊的訓練資料對。操作步驟為:
- 從訓練資料對dataset中選取訓練資料對,即(src, tgt)
- 合理修改src中的字元,變成src’
- 修改之後的src’與tgt組成一個新的資料對
- 重複上述步驟若干次,得到不少新的訓練資料對dataset’
- 將dataset和dataset’一起用於模型訓練。
論文的做法
但是本論文的做法不同。它的想法其實也挺正常。具體的做法是:
- 對每一個src,使用模型推斷,得到多個推斷結果(n-best)
- 對每一個推斷結果,計算一個flunecy分數
- 抽取出所有分數低於正確推斷結果(認為是n-best的第一個)的推斷結果
- 對於選取出的每一個推斷結果,與tgt句子組成新的訓練資料對,叫做fluency boost sentence pair,這些資料對用於後續的訓練
上述做法就是論文的做法。這種做法與傳統的增加資料的做法相比,有一個明顯的優勢就是:
- 模型推斷的結果,更能反映當前模型的資訊,用它來反饋給模型,能夠更加有效地糾正模型。
因此,個人覺得這種做法訓練出的模型效能要優於傳統的增加訓練資料的做法。
並且,使用fluency boost learning可以多回合進行逐步糾錯,在連續錯誤的情況下,能夠逐步糾正詞語,使得整個推斷流程的詞語上下文變得清晰。
幾個要點
論文有幾個要點,如下:
- 如何計算fluency分數?
- fluency boost learning也有多種型別
計算fluency分數
fluency分數的計算很簡單,公式如下:
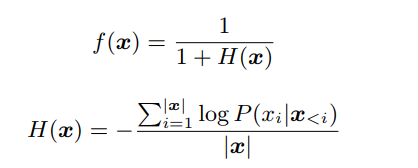
其中x代表句子,f(x) 即 fluency score,H(x)即x的交叉熵。
fluency boost 的種類
fluency boost leanring 有三種方式:
- Back-boost learning
- Self-boost learning
- Dual-boost learning
Back-boost借鑑於NMT的Back translation,是講一個流暢的句子轉換成一個含有錯誤的句子。論文給了一個虛擬碼:

Self-boost允許模型自己生成候選結果。論文的虛擬碼如下:

back-boost和self-boost是從不同的層面生成不流暢的句子用於提升模型的效能。Dual-boost則是兩者的結合。虛擬碼如下:

然後論文還給出了一些資料測試結果對比,有興趣的可以通過文章開頭的論文連結,下載論文檢視。
目前,還不知道哪裡有開源的實現。或許你可以試著自己去實現一個。嘿嘿。
注:
- 論文指出NEC不同於NMT,NEC的目標是不改變原句子的意思的前提下使句子更流暢。
聯絡我

個人公眾號,你可能會有興趣:
