
What should we watch tonight?
I have always loved watching a good movie. When I was a kid, the librarian at my local library would joke with me: “What movie are going to rent today, Ben?”. Of course, she knew 9 times out of 10 it would be Willy Wonka and the Chocolate Factory (the original one from 1971). So, there were usually no surprises when I came to the checkout counter with my selection in hand. We would have a few laughs, and then I’d be on my way to the dime store to buy a little candy before going home and popping the movie into our VHS player.
The types of movies that we enjoy feels like a very personal quality of ours. For instance, I would have a hard time explaining to you why I enjoy the movie Amelie so much. Is it because of the music? Or the artistic nature of the film? Or Audrey Tautou? Or my fascination with Europe? Or all of the above? As unique and unpredictable our film preferences might seem, chances are good that somebody else in the world shares very similar tastes to ours.
This is precisely the idea behind collaborative filtering recommenders. Collaborative filtering is a technique to recommend movies to a user based on finding other users with similar tastes. We can find users with similar tastes based on the movies that we have both seen and rated similarly. Andrew Ng provides a great introduction to collaborative filtering recommender systems in his
The goal of this blog post is to share with you (1) how I built a standard movie recommender system for a single user and (2) my solution to the problem of recommending movies to 2 users wanting to watch a movie together. Too often my significant other and I are sitting in front of the TV scrolling through Netflix or Amazon Video trying to decide what movie to watch together, and it seems more often than not one of us has to make a compromise in order to accommodate the preferences of the other. So, the purpose of goal 2 was to try to find a solution for this problem, so that we can both be happy with our movie selection.
Description of the data
For my recommender system, I utilized the MovieLens 20M ratings data set. This data set consists of 20 Million ratings for 27,000 different movies by 138,000 users. The data was created between January 9, 1995 and March 31, 2015. Thus, no movies were included with a release data after March 31, 2015. The ratings data was on a scale of 0.5 stars to 5.0 stars. Each user in this data set rated at a minimum of 20 different movies. The two data files that I used for this project where the Ratings file and the Movies file. These were read into a pandas DataFrame. Screenshots of these two DataFrames are provided below.


An important aspect of the data is the fact that the ratings data is very sparse. This is because of the 27,000 movies, each user has rated only a small fraction of movies. Thus, if we constructed a full matrix with 138,000 rows corresponding to the users and 27,000 columns corresponding to the movies, most of our values would be NaN. Because of this sparseness, I made use of the SciPy sparse matrix package for handling this data, which I will discuss in more detail in the next section.
My Approach
To build a collaborative filtering recommender system, I used a general class of algorithms called low rank matrix factorization. Specifically, I used singular value decomposition (SVD) to reduce the Ratings Matrix with a large number of features to one with a smaller subset of features that allows us to approximate the original matrix. Nick Becker wrote a great blog post describing SVD and how it can be applied to building a recommender system. So I highly encourage the reader to check out his post if you’d like to learn more.
I then implemented the following steps to build the collaborative filtering based recommender system:
- Filtered out the movies with fewer than 10 ratings
- Created a movie_index column that allows us to map movieId to a unique movie_index
- Performed a train/test split of the ratings data
- Implemented mean normalization by movie
- Used the SciPy sparse matrix package to build a sparse matrix where the indices corresponded to the userId and movie_index, and the data corresponded to the mean normalized ratings data
- Performed SVD using the SciPy svds method
- Generated the predicted rating matrix ? by calculating ? = ?·Σ·?ᵀ, where ? is the users features matrix, Σ is a matrix where the diagonal values are the singular values, and ? is the movie features matrix
- Added back the movie mean normalization component to the predicted ratings
- Sorted the top N predicted ratings and printed out the resulting movie list
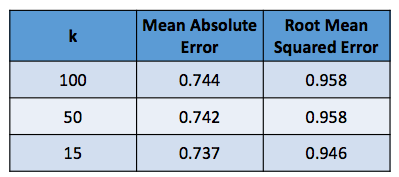
I did model tuning using the training data. One of the free parameters for SVD is the number of components k, which corresponds to the number of singular values. After building the model with a selected value of k, I then calculated a predicted rating for the test set data. This was followed by an error analysis calculating mean absolute error (MAE) and root mean square error (RMSE) based on the actual ratings data. The k value that resulted in the lowest error was then used for building my final recommender system model.
As mentioned earlier, the final part of this project was to build a recommendation system that can make recommendations for 2 users who would like to watch a movie together. Based on a very useful publication (see O’Connor et al.), there are 2 general ways to accomplish this. One way is to create a pseudo-user that represents both user’s tastes. In order to implement this method, the ratings of each user would need to be merged prior to performing SVD. Another approach is to generate a separate recommendation list for each group member and merge the lists in an ad-hoc fashion. I chose this second strategy for building my recommender system.
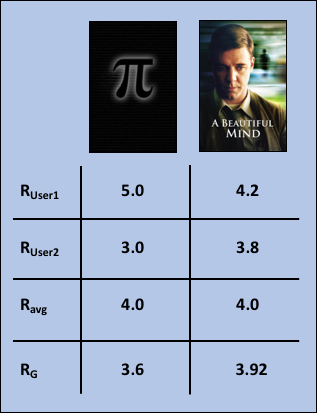
The method by which to merge the two lists required some additional thought. If we simply take the average of the two predicted ratings, then we will not account for movies where the predicted scores between the two group members is very different. This is illustrated in a hypothetical example in the table below: Predicted ratings for User1 and User2 are provided for two movies, Pi and A Beautiful Mind. In the case of Pi, the predicted ratings have a much greater discrepancy between User1 and User2 than for A Beautiful Mind, yet the average rating is the same. This is a problem, because we may be recommending movies in which one user might not like the movie very much and the other user might like it a lot. Hence, this method does not accomplish my original goal, in which I wanted to maximize the overall group’s happiness. The solution to this issue was to develop my own unique group rating function, as described below.

My group rating function is defined as follows:
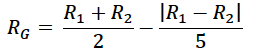
Where R₁ and R₂ are the predicted scores for a particular movie for User1 and User2, respectively and Rg is the group rating. This group rating function calculates the average predicted score minus a penalty term that is proportional to the difference of the two individual ratings. The purpose for the penalty term is to give more weight to movies that have more similar predicted scores. Going back to our example, we can see that the movie Pi resulted in Rg=3.6, whereas A Beautiful Mind resulted in a much better overall score with Rg=3.92. Hence, based on this result, we would have higher confidence that the overall group’s happiness would be greater after watching A Beautiful Mind than it would be for Pi.
Results
The results from model tuning are shown in the table below. We observe that a value of k=15 gave rise to the lowest MAE and RMSE values. This agrees with the results of a reference cited here (see Cremonesi et al.).

Single user results
Next I’d like to demonstrate an example output of my movie recommender for a single user. In this case, UserId 9 gave high ratings to movies that could be generally classified as Thrillers or Crime. For this case, the top recommended movies were also highly rated movies in these genres. Thus, it appears our standard movie recommender is doing a good job.
A subset of original ratings provided for UserId: 9Rated 5.0 for movie What Lies Beneath (2000)Rated 3.0 for movie General's Daughter, The (1999)Rated 2.0 for movie Entrapment (1999)Rated 3.0 for movie Austin Powers: The Spy Who Shagged Me (1999)Rated 3.0 for movie Return of the Living Dead, The (1985)Rated 3.0 for movie Psycho (1960)Rated 3.0 for movie Stigmata (1999)Rated 4.0 for movie American Pie (1999)Rated 2.0 for movie Vertical Limit (2000)Rated 1.0 for movie Traffic (2000)Rated 2.0 for movie Deep Blue Sea (1999)Rated 4.0 for movie Fast and the Furious, The (2001)Rated 4.0 for movie Cast Away (2000)Rated 2.0 for movie Scary Movie (2000)Rated 5.0 for movie Hannibal (2001)Rated 2.0 for movie Creepshow (1982)Rated 2.0 for movie Urban Legends: Final Cut (2000)Rated 5.0 for movie Fight Club (1999)Rated 5.0 for movie Exorcist, The (1973)Rated 4.0 for movie There's Something About Mary (1998)
Top recommendations for UserId: 9Predicting rating 5.0 for movie Shawshank Redemption, The (1994)Predicting rating 5.0 for movie Silence of the Lambs, The (1991)Predicting rating 4.9 for movie Pulp Fiction (1994)Predicting rating 4.9 for movie Braveheart (1995)Predicting rating 4.8 for movie Schindler's List (1993)Predicting rating 4.7 for movie Usual Suspects, The (1995)Predicting rating 4.6 for movie Seven (a.k.a. Se7en) (1995)Predicting rating 4.6 for movie Zero Motivation (Efes beyahasei enosh) (2014)Predicting rating 4.5 for movie Fugitive, The (1993)Predicting rating 4.5 for movie Terminator 2: Judgment Day (1991)Predicting rating 4.5 for movie Godfather: Part II, The (1974)Predicting rating 4.4 for movie Saving Private Ryan (1998)Predicting rating 4.4 for movie Dances with Wolves (1990)Predicting rating 4.4 for movie Matrix, The (1999)Predicting rating 4.4 for movie American Beauty (1999)Predicting rating 4.4 for movie One Flew Over the Cuckoo's Nest (1975)Predicting rating 4.4 for movie Goodfellas (1990)Predicting rating 4.3 for movie Apollo 13 (1995)Predicting rating 4.3 for movie Raiders of the Lost Ark (Indiana Jones and the Raiders of the Lost Ark) (1981)Predicting rating 4.3 for movie American History X (1998)
Combined users results
Lastly, the recommender system results for two users is shown below. One of these users corresponds to myself and the other user corresponds to my significant other (extra credit for correctly guessing which one is which). The combined recommendations employed the group rating function discussed previously. The results of my group recommender is encouraging, since a number of movies that were recommended to us were ones that we had actually seen and really enjoyed.
A subset of original ratings provided for UserId: 138494Rated 4.5 for movie Like Water for Chocolate (Como agua para chocolate) (1992)Rated 4.0 for movie Mr. Holland's Opus (1995)Rated 4.0 for movie Sense and Sensibility (1995)Rated 2.0 for movie Fargo (1996)Rated 4.0 for movie Pi (1998)Rated 4.5 for movie Garden State (2004)Rated 4.0 for movie What's Eating Gilbert Grape (1993)Rated 1.0 for movie Lemony Snicket's A Series of Unfortunate Events (2004)Rated 4.0 for movie Apollo 13 (1995)Rated 4.5 for movie Buffalo '66 (a.k.a. Buffalo 66) (1998)Rated 4.5 for movie Mission, The (1986)Rated 4.5 for movie River Runs Through It, A (1992)Rated 5.0 for movie Spanish Apartment, The (L'auberge espagnole) (2002)Rated 5.0 for movie Willy Wonka & the Chocolate Factory (1971)Rated 3.0 for movie Sideways (2004)Rated 5.0 for movie Amelie (Fabuleux destin d'Amélie Poulain, Le) (2001)Rated 4.0 for movie Bend It Like Beckham (2002)Rated 1.0 for movie Dumb & Dumber (Dumb and Dumber) (1994)Rated 4.0 for movie Dead Poets Society (1989)Rated 4.0 for movie O Brother, Where Art Thou? (2000)
A subset of original ratings provided for UserId: 138495Rated 1.0 for movie Indiana Jones and the Kingdom of the Crystal Skull (2008)Rated 4.5 for movie Mephisto (1981)Rated 5.0 for movie Life Is Beautiful (La Vita è bella) (1997)Rated 3.5 for movie Out of Africa (1985)Rated 4.0 for movie Sense and Sensibility (1995)Rated 4.5 for movie Virgin Suicides, The (1999)Rated 1.0 for movie Dumb & Dumber (Dumb and Dumber) (1994)Rated 4.0 for movie Three Colors: Blue (Trois couleurs: Bleu) (1993)Rated 1.0 for movie Star Trek: Insurrection (1998)Rated 4.5 for movie Postman, The (Postino, Il) (1994)Rated 4.0 for movie Steel Magnolias (1989)Rated 4.0 for movie Gattaca (1997)Rated 2.5 for movie Dangerous Minds (1995)Rated 3.5 for movie Seven (a.k.a. Se7en) (1995)Rated 0.5 for movie Terminator 2: Judgment Day (1991)Rated 2.5 for movie Driving Miss Daisy (1989)Rated 0.5 for movie Home Alone (1990)Rated 4.0 for movie Love Actually (2003)Rated 4.0 for movie Leaving Las Vegas (1995)Rated 5.0 for movie Cinema Paradiso (Nuovo cinema Paradiso) (1989)
Top combinded recommendations for UserIds: 138494 and 138495Predicting rating 4.5 for movie Zero Motivation (Efes beyahasei enosh) (2014)Predicting rating 4.5 for movie Shawshank Redemption, The (1994)Predicting rating 4.5 for movie Fight Club (1999)Predicting rating 4.4 for movie Forrest Gump (1994)Predicting rating 4.3 for movie Usual Suspects, The (1995)Predicting rating 4.3 for movie Matrix, The (1999)Predicting rating 4.3 for movie Schindler's List (1993)Predicting rating 4.3 for movie American Beauty (1999)Predicting rating 4.3 for movie Memento (2000)Predicting rating 4.3 for movie Death on the Staircase (Soupçons) (2004)Predicting rating 4.3 for movie City of God (Cidade de Deus) (2002)Predicting rating 4.3 for movie Star Wars: Episode V - The Empire Strikes Back (1980)Predicting rating 4.3 for movie Seven Samurai (Shichinin no samurai) (1954)Predicting rating 4.3 for movie Spirited Away (Sen to Chihiro no kamikakushi) (2001)Predicting rating 4.3 for movie Dark Knight, The (2008)Predicting rating 4.3 for movie Princess Bride, The (1987)Predicting rating 4.3 for movie O Auto da Compadecida (Dog's Will, A) (2000)Predicting rating 4.3 for movie Band of Brothers (2001)Predicting rating 4.3 for movie Rear Window (1954)Predicting rating 4.3 for movie One Flew Over the Cuckoo's Nest (1975)
Wrapping up
In this blog post, I demonstrated (1) how to build a movie recommender by applying SVD on the MovieLens 20M ratings data set, and (2) how to provide recommendations to a group of 2 users wanting to watch a movie together. Of course, there are many possible ways to build a recommender system. With more time, I would have liked to implement a more advanced algorithm than plain vanilla SVD. For example, the group that won the Netflix prize competition developed a collaborative filtering algorithm that can better capture both user and movie biases in the data. Thus, if certain movies have higher than average ratings, these movies don’t completely dominate the recommender algorithm. I did in part account for this fact by implementing a mean normalization of the movie ratings data, but the Netflix prize winners adopted a more advanced approach to this problem that likely does better (see Yehuda).
Lastly, I’d like to thank you for reading this blog post. Please check out my Github repo if you’d like to explore the code I wrote for this project. I had a lot of fun writing this post and sharing with you my love of machine learning and, of course, Willy Wonka and the Chocolate Factory.