
Superset: Scaling Data Access and Visual Insights at Airbnb


Superset: Scaling Data Access and Visual Insights at Airbnb
Introduction
At Airbnb, one of our fundamental beliefs is that data access should be democratized to empower every employee in order to make data informed decisions. We believe that grounding decisions with quantitative insights from data, together with qualitative insights (e.g. in-person user research) result in the best possible business decisions. This applies to all parts of the organization, whether it is about deciding to launch a new product feature or analyzing how to provide the best possible employee experience.
One of the challenges that accompanies data democracy is enabling data access to users at various levels of data literacy. A number of our users are deeply skilled at writing SQL, particularly those in our Data Science, Engineering and Business Operations teams. The ability to write SQL provides tremendous flexibility in accessing data from our Data Warehouse in Hadoop. However, in our vision to empower every user of data, SQL is often times too high a barrier. Secondly, once users have accessed the data, they are faced with the challenge of exploring and discovering insights. Our solution to both of these challenges is the development of
Solution: Superset
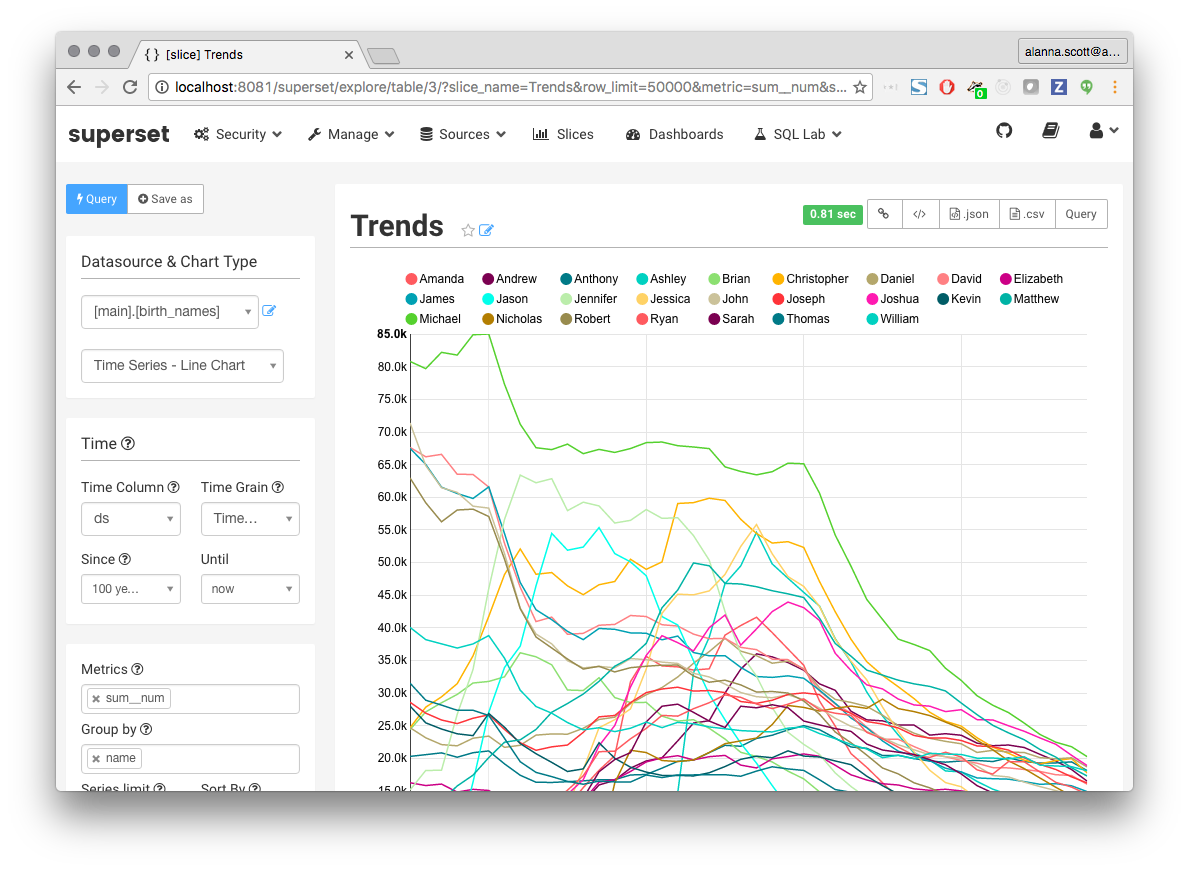
Superset is a data exploration and visualization platform designed to be visual, intuitive and interactive. It consists of two primary interfaces:
- A Rich SQL IDE (Interactive Development Environment) enabling fast and flexible access of data
- A Data Exploration Interface that converts data tables into rich visual insights
The combination of these two interfaces enables users to consume data in a variety of ways. Users can directly visualize data from tables stored a variety of databases including Presto, Hive, Impala, Spark SQL, MySQL, Postgres, Oracle, Redshift, and SQL Server. Connectivity with Druid extends the capabilities of Superset to visualize billions of rows of data thanks to its in-memory, column-oriented distributed architecture. With the addition of a SQL IDE, it provides power users with the ability to compose SQL queries to restructure or reduce the size of your data or union data across tables. Additionally, users can immediately visualize their query results using Superset’s Visualize flow.
We first launched Superset’s data exploration interface in March 2016 as a way for users to perform fast and intuitive “slicing and dicing” against any dataset. Since then, we have added a number of major new features including:
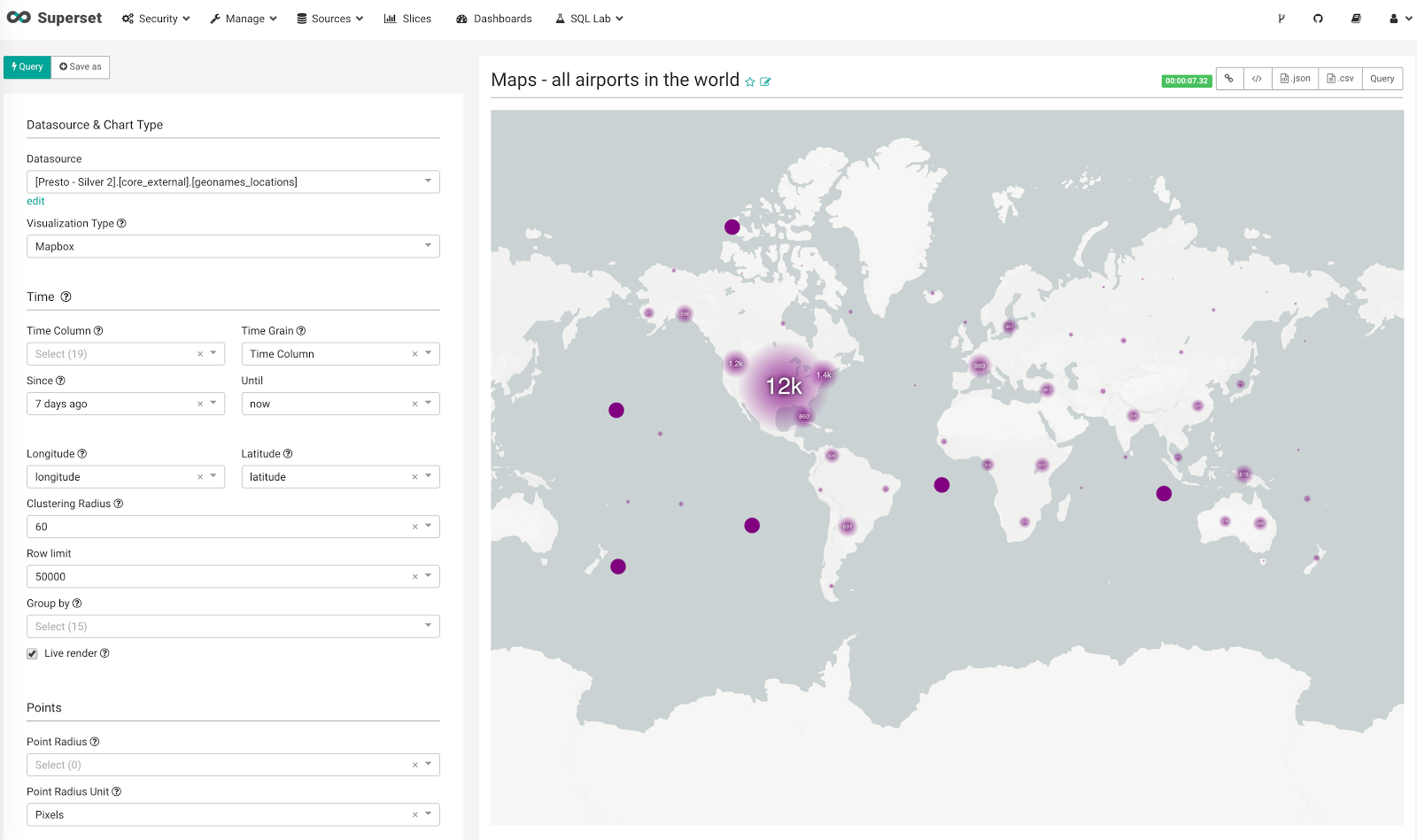
- Maps and geo support leveraging Mapbox
- User profile pages which highlight a user’s favorited dashboards/slices, created content, and recent activity
- New security permissions plus the ability to “Request Access” to a dashboard view
- Completely revamped design, UI/UX and theme
- A new name and logo! We changed the project name from Caravel to Superset. We were drawn to the name Superset as it alludes to multiple collections and sets of data while enabling users to consume data in a variety of ways

Introducing Superset SQL Lab
Today we’re announcing the introduction of “SQL Lab”, the new SQL IDE in Superset. Integrating SQL Lab into Superset is advantageous because it connects the flow from arbitrary SQL to data visualization, dashboarding and knowledge sharing. Integrating both the SQL IDE and the Data Exploration interfaces together had the additional benefit of managing authentication, roles and permissions in a single tool. SQL Lab as a part of Superset enables us to provide backend query support to all the databases that Superset supports (with the exception of Druid which is not SQL based).
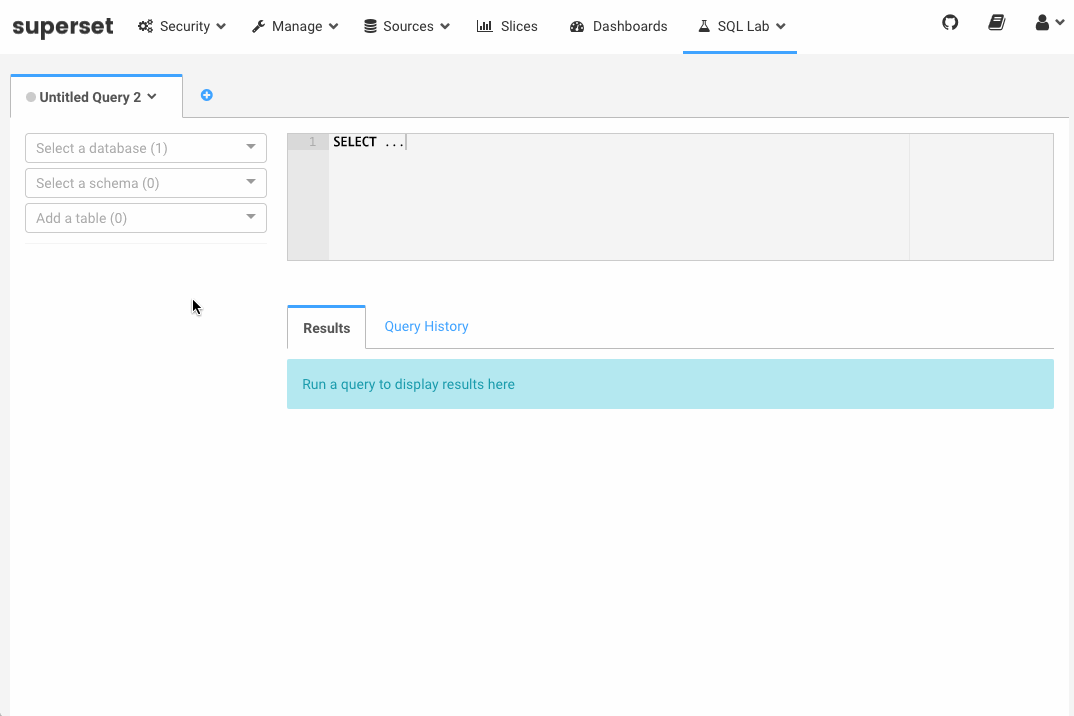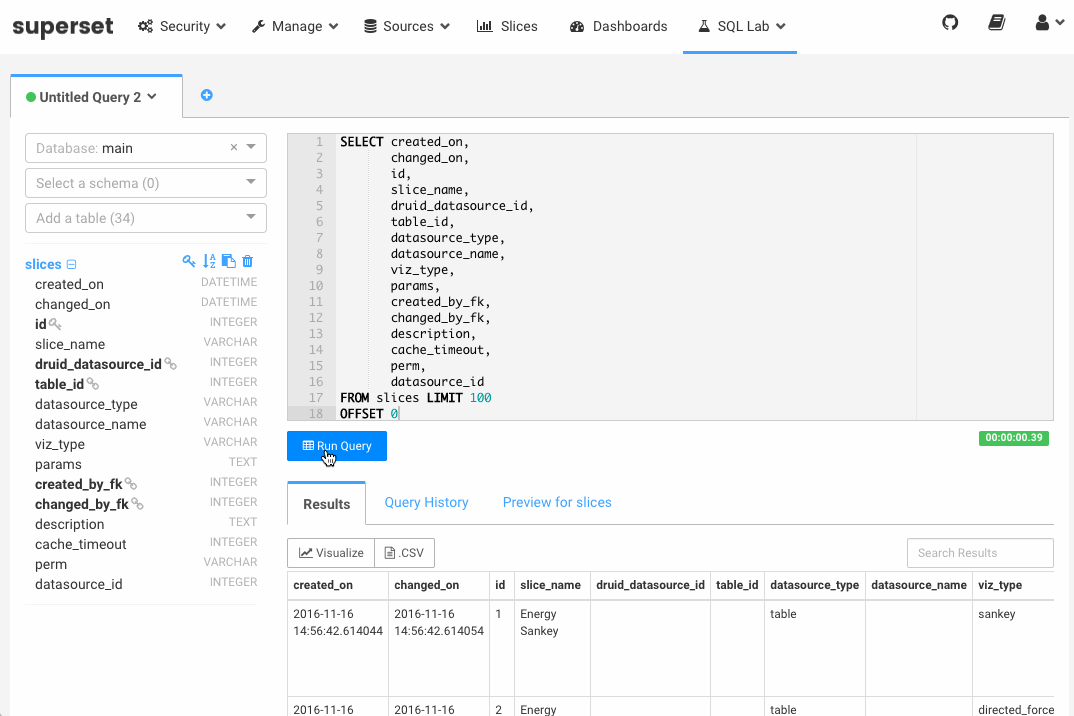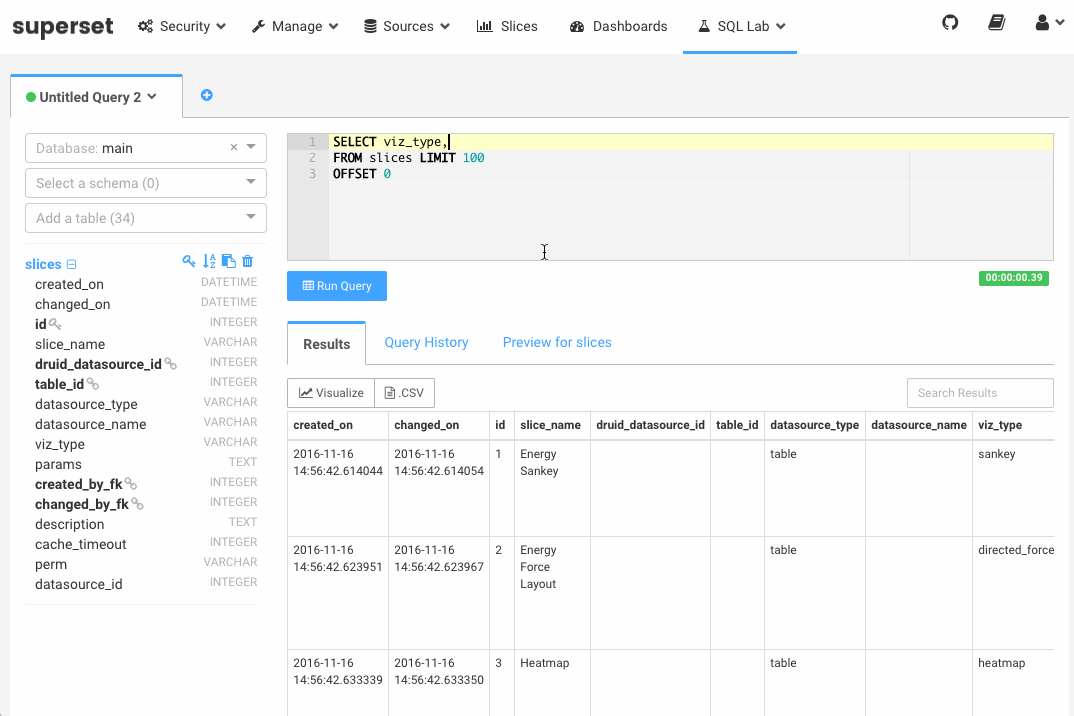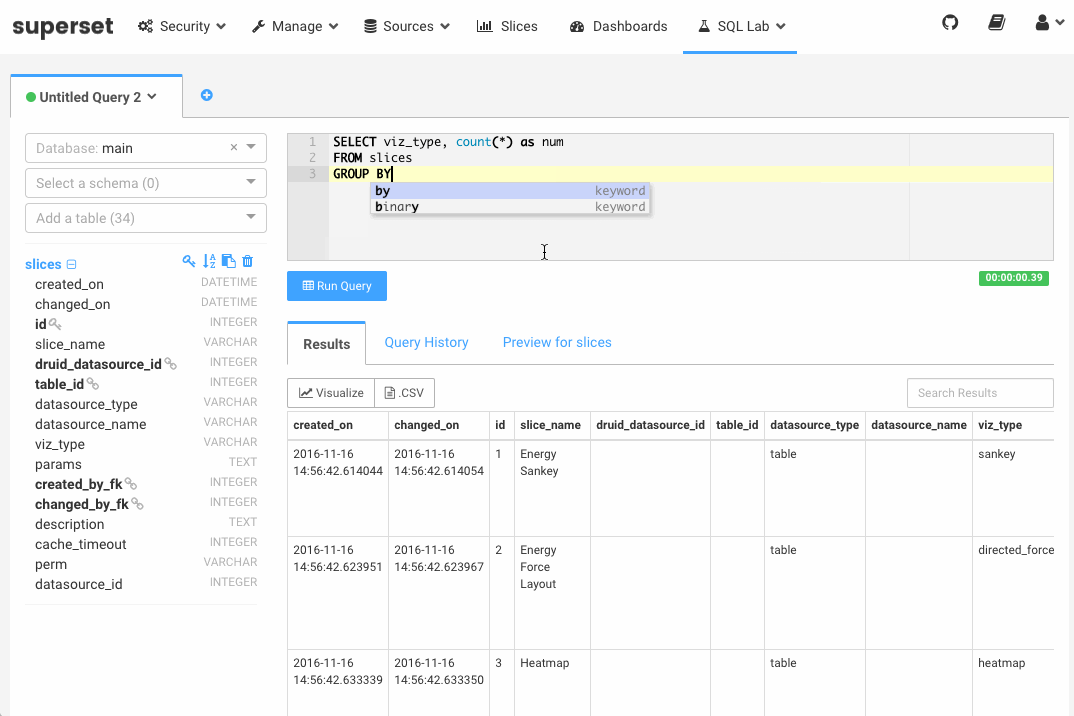
SQL Lab packs a number of powerful features including (for the full list, see the Superset documentation):
- Multiple tabs as distinct workspaces
- Per-tab query history, enabling people to iterate on separate queries
- Table and column metadata browsing, providing a reference while authoring queries
- View and search through your query results
- Workflow to create rich visualizations out of arbitrary SQL using Superset’s Visualize flow
- Support for long running background sql statements as “CREATE TABLE AS”
- Operates with most database backends including Presto, Hive, Impala, Spark SQL, MySQL, Postgres, Oracle, Redshift, and SQL Server
- A SQL query search engine — this enables users to find anything from historical queries by any user to seeing who has queried a table you created
- Support for Jinja templates syntax in your SQL, allowing to parameterize elements of your query and call macros
- Advanced support for Presto: showing a progress bar, showing extra metadata around partitioned fields and latest partition value
Computationally intensive, long running queries are common in the “petabyte era” of data, and SQL Lab is designed to provide a nice workflow for this use case. For deployments that have an asynchronous backend available, SQL Lab will automatically default to running queries asynchronously to support large queries. Additionally, with the Create Table As (CTAS) feature, SQL Lab allows users to store query results in a newly created table. With this table, users can then query and visualize data off of the summary table that was just created.
SQL Lab also makes it easy to manage access for any internal database to a set of employees. Administrators can add a new database to Superset using a simple flow while subsequently granting permissions to users through roles. Users can be granted per-database-connection access, as well as per-table access. In the cases where per-table access applies, Superset introspects the query and identifies the table referenced in the SQL.
What’s Next?
Superset had humble beginnings starting out as a hackathon data visualization project, however now it is a full-fledged open source project. Since we launched Superset in March 2016, it has grown into one of the most popular open source data visualization apps, with over 10,000 stars and 100 contributors on GitHub. New features and bug fixes are being added weekly by both Airbnb engineers and community contributors. With the addition of SQL Lab, we are confident that data users will find even more usefulness from the project. We’re excited to see the project grow and improve over time. Some of the features in the near term roadmap include:
- A smoother “visualize flow”, with smart defaults
- Better support for Hive, showing progress bar and linking to query logs
- Surfacing more database-engine-specific metadata
- An on-demand table profiler service that can surface information about the data in your table
- Social features: favorites, tags, comments, table users
Airbnb loves open source, and the Superset team does all of their work in the open. Come join our community on Github! Or if you are really excited about our vision and want to join the team, we’re hiring software engineers to revolutionize the future of data visualization.