
slowfast解讀:facebook用於機器視覺分析視訊理解的雙模CNNk
檢測並歸類影象中的物體是最廣為人知的一個計算機視覺任務,隨著ImageNet資料集挑戰而更加流行。不過還有一個令人惱火的問題有待解決:視訊理解。視訊理解指的是對視訊片段進行分析並進行解讀。雖然有一些最新的進展,現代演算法還遠遠達不到人類的理解層次。
Facebook的AI研究團隊新發表的一篇論文,SlowFast,提出了一種新穎的方法來分析視訊片段的內容,可以在兩個應用最廣的視訊理解基準測試中獲得了當前最好的結果:Kinetics-400和AVA。該方法的核心是對同一個視訊片段應用兩個平行的卷積神經網路(CNN)—— 一個慢(Slow)通道,一個快(Fast)通道。
作者觀察到視訊場景中的幀通常包含兩個不同的部分——不怎麼變化或者緩慢變化的靜態區域和正在發生變化的動態區域,這通常意味著有些重要的事情發生了。例如,飛機起飛的視訊會包含相對靜態的機場和一個在場景中快速移動的動態物體(飛機)。在日常生活中,當兩個人見面時,握手通常會比較快而場景中的其他部分則相對靜態。
根據這一洞察,SlowFast使用了一個慢速高解析度CNN(Fast通道)來分析視訊中的靜態內容,同時使用一個快速低解析度CNN(Slow通道)來分析視訊中的動態內容。這一技術部分源於靈長類動物的視網膜神經節的啟發,在視網膜神經節中,大約80%的細胞(P-cells)以低頻運作,可以識別細節,而大約20%的細胞(M-cells)則以高頻運作,負責響應快速變化。類似的,在SlowFast中,Slow通道的計算成本要比Fast通道高4倍。
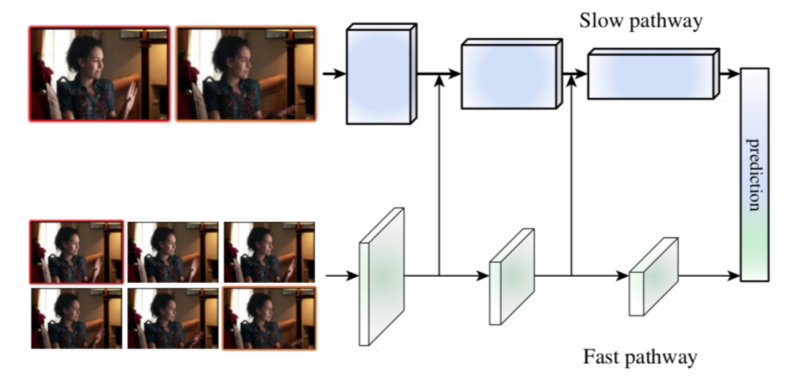
SlowFast工作原理
Slow通道和Fast通道都使用3D RestNet模型,捕捉若干幀之後立即執行3D卷積操作。
Slow通道使用一個較大的時序跨度(即每秒跳過的幀數),通常設定為16,這意味著大約1秒可以採集2幀。Fast通道使用一個非常小的時序跨度τ/α,其中α通常設定為8,以便1秒可以採集15幀。Fast通道通過使用小得多的卷積寬度(使用的濾波器數量)來保持輕量化,通常設定為慢通道卷積寬度的⅛,這個值被標記為β。使用小一些的卷積寬度的原因是Fast通道需要的計算量要比Slow通道小4倍,雖然它的時序頻率更高。
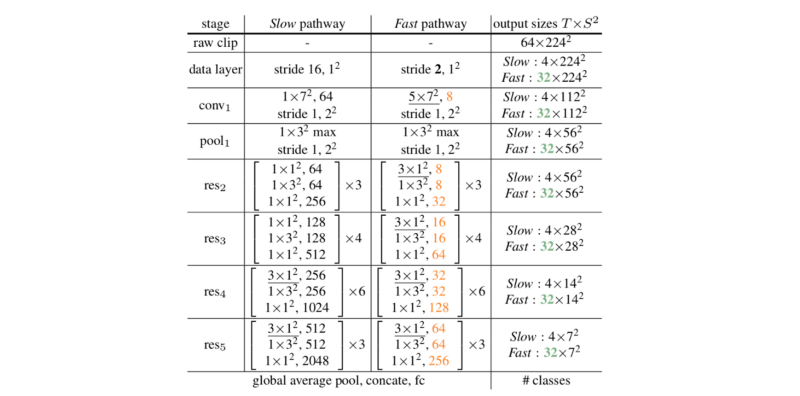
上圖是一個SlowFast網路的例項。卷積核的尺寸記作{T×S², C} ,其中T、S和C分別表示時序temporal, 空間spatial和頻道Channel的尺寸。跨度記作{temporal stride, spatial stride ^ 2}。速度比率(跳幀率) 為 α = 8 ,頻道比率為1/β = 1/8。τ 設定為 16。綠色表示高一些的時序解析度,Fast通道中的橙色表示較少的頻道。
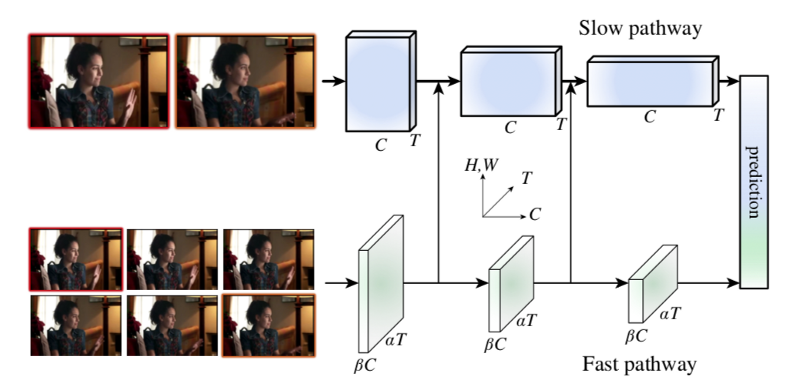
側向連線
如圖中所示,來自Fast通道的資料通過側向連線被送入Slow通道,這使得Slow通道可以瞭解Fast通道的處理結果。單一資料樣本的形狀在兩個通道間是不同的(Fast通道是{αT, S², βC} 而Slow通道是 {T, S², αβC}),這要求SlowFast對Fast通道的結果進行資料變換,然後融入Slow通道。
論文給出了三種進行資料變換的技術思路,其中第三個思路在實踐中最有效。
- Time-to-channel:將{αT, S², βC} 變形轉置為 {T , S², αβC},就是說把α幀壓入一幀
- Time-strided取樣:簡單地每隔α幀進行取樣,{αT , S², βC} 就變換為 {T , S², βC}
- Time-strided卷積: 用一個5×12的核進行3d卷積, 2βC輸出頻道,跨度= α.
有趣的是,研究人員發現雙向側鏈接,即將Slow通道結果也送入Fast通道,對效能沒有改善。
在每個通道的末端,SlowFast執行全域性平均池化,一個用來降維的標準操作,然後組合兩個通道的結果並送入一個全連線分類層,該層使用softmax來識別影象中發生的動作。
資料集
SlowFast在兩個主要的資料集 —— DeepMind的Kinetics-400和Google的AVA上進行了測試。雖然兩個資料集都包含了場景的標註,它們之間還是有些差異:
Kinetics-400包含成千上萬個Youtube視訊的10秒片段,將人的動作歸為400類(例如:握手、跑、跳舞等),其中每一類至少包含400個視訊。
AVA包含430個15分鐘的標註過的Youtube視訊,有80個原子化可視動作。每個動作的標註即包含描述文字,也包含在畫面中的定位框。
結果
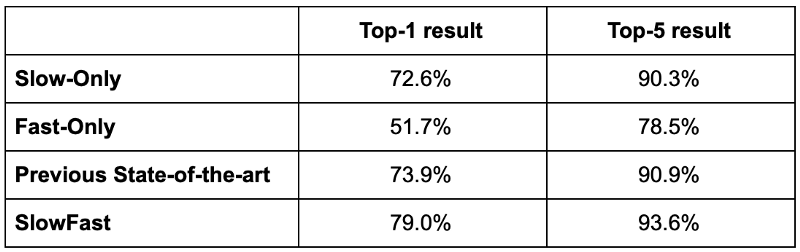
SlowFast在兩個資料集上都達到了迄今為止最好的結果,在Kinetics-400上它超過最好top-1得分5.1% (79.0% vs 73.9%) ,超過最好的top-5得分2.7% (93.6% vs 90.9%)。在 Kinetics-600 資料集上它也達到了最好的結果。Kinetics-600資料集與Kinetics-400類似,不過它將動作分為600類,每一類包含600個視訊。
在AVA測試中,SlowFast研究人員首先使用的版本,是一個較快速R-CNN目標識別演算法和現成的行人檢測器的整合,利用這個行人檢測器獲取感興趣區域。研究人員隨後對SlowFast網路進行了預訓練,最後在ROI上執行網路。結果是28.3 mAP (median average precision) ,比之前的最好結果21.9 mAP有大幅改進。值得指出的是在Kinetics-400和Kinetics-600上的預訓練沒有獲得顯著的效能提升。
有趣的是,論文比較了只使用Slow通道、只使用Fast通道、同時使用Slow和Fast通道的結果,在Kinetics-400上,只使用Slow通道的網路其top-1結果為72.6%,top-5為90.3%。只使用Fast通道的網路,top-1和top-5分別為51.7% 和 78.5%。
匯智網翻譯整理,轉載請標明出處。SlowFast Explained: Dual-mode CNN for Video Understanding