
Building a Real-World Pipeline for Image Classification
Proof of concept
First, we have decided to implement something quite small, but that can bring value for our users, as a proof of concept.
The idea was to create a model that identified a banner on the image, or if the image is/has a banner. Thus, enabling us to filter them in order to find one main image
For that, we have manually gathered approximately athousand images for each “class”. Yes, we went through our data and kept copying images to folders until we had “enough” of them for the first try.
Here is a video explaining the whole idea in depth:

As the video shows, it is easy to start and get fairly good results. Tensorflow’s developers say that we could use about 100 images of each class. However, on our experience that was not suitable for production usage, where we have to cover a wider range if images. Of course, it varies depending on context.
Either way, our goal was to prove that it was possible to use it, and it was.
Moving forward
Once the concept has been proved, we acquired trust that the technology would be an enabler, that it would scale to our throughput and precision expectations.
The next step would be to split efforts in two parts: creating a strong model and building infrastructure to classify, store, and serve the classification data.
Building the model — we need data?
As mentioned, the amount of images for our use-case was bigger than we first thought. Thus, we had to gather a reasonable amount of manually labeled images to improve the model’s accuracy against our wide inventory.


We have started with a “banner/no-banner” simple front-end application that would read from a database of images, show to a user and as for a manual classification.
Unfortunately, I couldn’t find screenshots of that one, but only for the subsequent update which introduced the concept of positioning.
Either way, the concept is the same, collecting manual labeled data.
We ran this application across the whole company, asking people to classify images from our inventory according to the rules we’ve stipulated on a document.
Even though, there were clearly mistakes, so we advise you to use some sort of consensus logic around the final conclusion of a manually labeled tag. e.g.: “if at least 5 people classified this as an ‘engine’, then it is an engine”.
Just in case, in order to avoid pollution on your models’ classes data.
Building the model — brick and mortar
Now that we have our dataset of images it’s a matter of putting it to good use. Our transfer learning attempt with the Inception model was a little heavy so we decided to make our own model using our favourite framework… Keras.

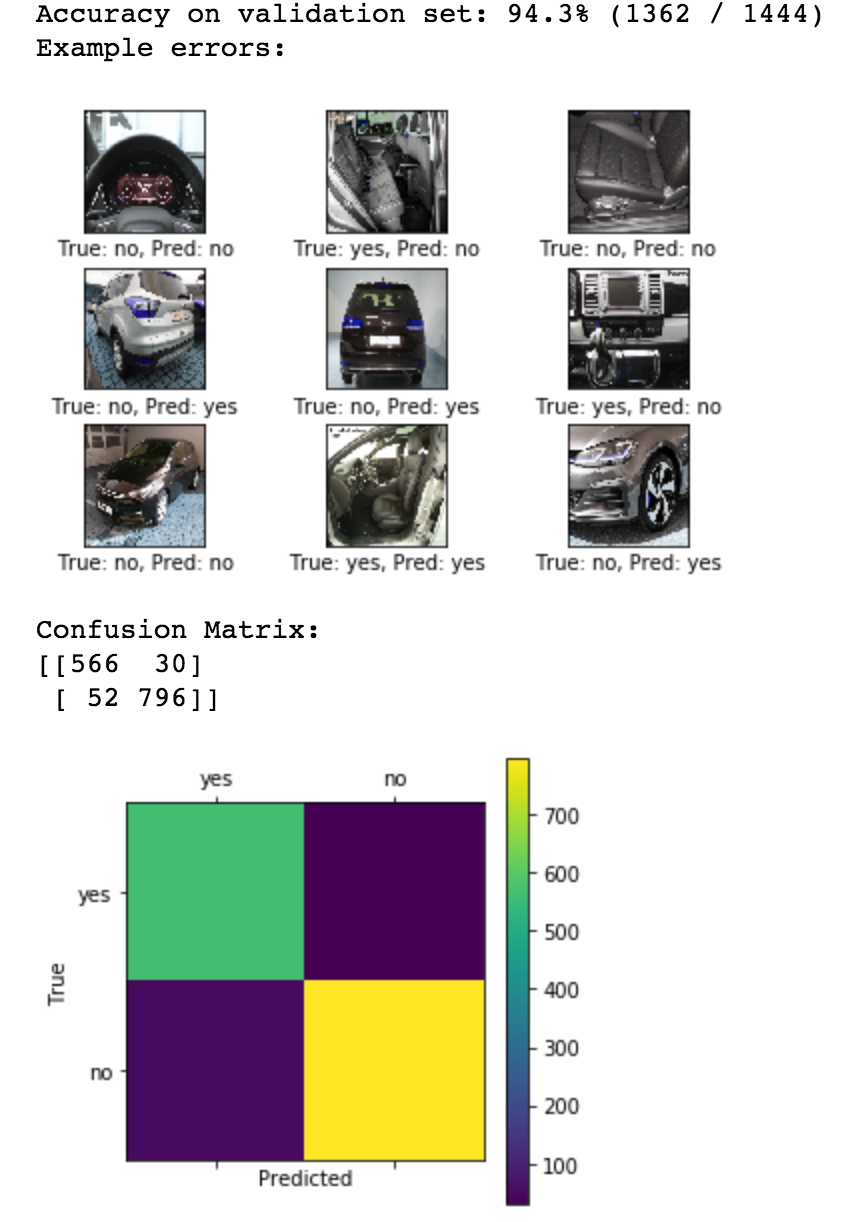
We will cover the creation of this model in more detail in another post (coming soon), but the end result was a small, efficient model capable of classifying images containing banners and those that don’t.
Here is an example of the models’ results, how the image of a car is seen by the model after extensive training an tweaking:


More tips on building the model will be presented on the sequel focused article.
Building the Infrastructure
While our model was being prepared, on the Platform Engineering side, we had to create infrastructure to support thousands of images being processed every minute. Our partners aren’t easy on us when it comes to sending data.
There were several challenges along the way, and the draft below covers only the first Production implementation:

We receive data from our providers, that goes into our normal ingestion process. The relevant part for this process, the images, are constantly reporting changes in the “image-stream”, where at the moment we use AWS Kinesis.
The image-classification-worker is an internal piece of code that gets new images, triggers the classification on Tensorflow-Serving, caches it and post data into another database, for consuption.
Among the challenges, we have storage & caching of classification data, fan-out, real-timeliness/impact, error-reporting and of course, budget.
You will learn more about how we have been dealing with those on a sequel article. We’ll explain in detail how we’ve implemented the architecture above, the tricks and limitations and how we evolved that to what we have now, spoiler: it grow a lot.