
Getting Better at Machine Learning
Models that are an integrated part of a product experience, or what we referred to as data products, often involve feedback loops. When done right, feedback loops can help us to create better experiences. However, feedback loops can also create unintended negative consequences, such as bias or inaccurate model performance measurements.
User Feedback Can Make Your Model Better
One of the most unexpected skills that I learned about real-life machine learning is the ability to spot opportunities for users to provide model feedback via product interactions. These decisions might seem only relevant to UI/UX at first, but they can actually have a profound impact on the quality of the features that the data product offers.

For example, Netflix decided last year to move away from the star-rating system to a thumbs up/down system, reportedly because its simplicity prompts more users to provide feedback, which in terms help Netflix to make their recommendations better. Similarly, Facebook, Twitter, Quora, and other social networks have long designed features such as likes, retweets, and comments which not only make the product more interactive, but also allow these companies to monetize better via personalization.
Creating feedback opportunities in product, instrumenting and capturing these feedback, and integrating it back into model development is important for both improving user experience as well as optimizing the companies’ business objectives and bottom lines.
Feedback Loops Can Also Bias Model Performance
While feedback loops can be powerful, they can also have unintended, negative consequences. One important topic is that models that are biased will amplify the bias the feedback loop introduces (see here). Other times, feedback loop can affect our ability to measure model performance accurately.
This latter phenomenon is best illustrated by Michael Manapat, who explains this bias based on his experience building fraud models at Stripe. In his example, he pointed out that when a live fraud model enforces certain policy (e.g. block a transaction if its fraud score is above certain threshold), the system never gets to observe the ground truth for those blocked transactions, regardless of whether they are fraudulent or not. This blind spot can affect our ability to measure the effectiveness of a model running live in production.

Why? When obvious fraudulent transactions are blocked, the ones that remained with ground truth that we can observe are typically false negative transactions that are harder to get right. When we re-train our models on these “harder” examples, our model performance will necessarily be worse than what it really is performing in production.
Michael’s solution to this bias is to inject randomness in production traffic to understand the counterfactuals. Specifically, for transactions that are deemed fraudulent, we will let a small percentage of transactions pass, regardless of their scores, so we can observe the ground truth. Using these additional labels, we can then re-adjust the calculation for model performance. This approach is simple but not entirely obvious. In fact, it took me a long while before spotting the same feedback loop in my model, and it is not until I encountered Michael’s talk that I found a solution.
Takeaway: Feedback loops in machine learning models are subtle. Knowing how to leverage feedback loops can help you to build a better user experience, and being aware of feedback loops can inform you to calculate the performance of your live system more accurately.
Conclusion

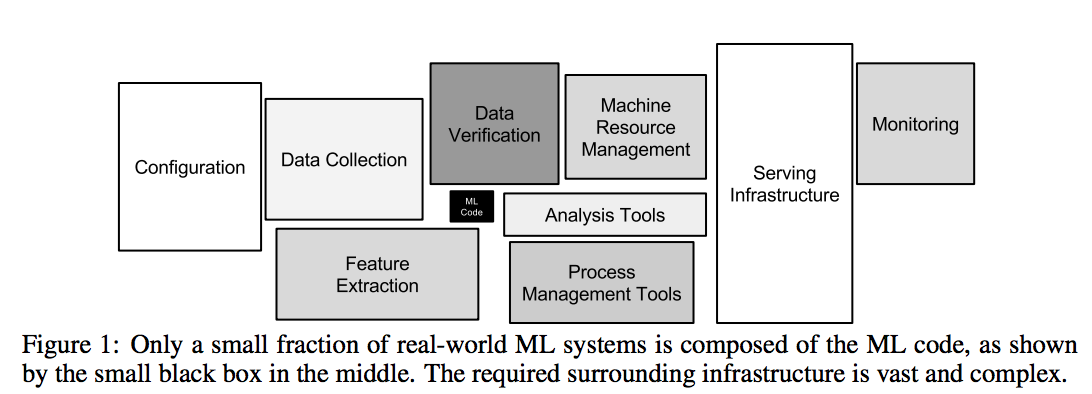
Throughout this post, I gave concrete examples around topics such as problem definition, feature engineering, model debugging, productionization, and dealing with feedback loops. The main underlying theme here is that building a machine learning system involves a lot more nuances than just fitting a model on a laptop. While the materials that I have covered here are only a subset of the topics that one would encounter in practice, I hope that they have been informative in helping you to move beyond “Laptop Data Science”.
Happy Machine Learning!