
Better Conversations with Machines
Conversational Tooling
The opportunities in this section are applicable to conversational interfaces, whether those interfaces are voice or text.
Portable Conversational Skills
One of the best parts of being a developer now as opposed to, say, 20 years ago is that we all share our toys so much better than we used to. Between powerful cloud APIs and the world of open source on GitHub, the average developer today has access to huge amounts of powerful technology that can be composed very rapidly. In the world of conversational agents, it’s amazing how quickly developers can hack up a quick chatbot that can hold a simple conversation, send text messages, order you a car, and so on.
Thanks to the excitement around voice-based agents introduced by smart speakers, a lot more developers are working on building conversational interfaces than ever before. However, there aren’t a lot of good examples of building blocks that can be used to build up the basics needed to create a conversational agent.
The best example of what I’d like to have is DialogFlow’s concept of Prebuilt Agents. They are reusable conversational skills, but they’re constrained for use within DialogFlow specifically.
What I’d really like is a generic module that can be used to talk about the weather across a wide range of runtimes. Since I don’t have time to build such a thing, I’m probably going to suggest this idea to my friends at
Speaking of missing tools for voice agent development, there’s another big class of functionality that I find missing for voice.
Semantic Telemetry for Conversational Agents
This is another area where the situation is fairly similar whether you’re developing a conversational agent for messaging platforms or voice platforms. In either case, you need some way of monitoring what your agent/skill is doing. In the voice space, Voice Labs, Dashbot, Bespoken, and others are developing analytics/telemetry solutions focused on these new conversational platforms.
But I want to see so much more than basic statistics around numbers of conversations and abandonment rates. Given the AI capabilities we have today, I definitely want to know things about sentiment, especially for users who abandoned some transactional flow.
At a more fine-grained level, I’d like to know which branches in the dialogue were most successful in leading to a transaction conversion. Beyond that, I’d like to know things about the commonalities in the language that is leading to positive vs. negative outcomes. Should my agent be serious or jokey?
If we throw in a multivariate framework with metrics-based deployment capabilities (like LaunchDarkly), and suddenly you could have self-optimizing dialogues. Let the users decide which dialogue variants are working for them through real-world usage. Given how common and powerful this technique is on the web, it’s only a matter of time before it comes to the world of conversational agents in voice and text.
Voice Tech Infrastructure
The opportunities in this section come out of the widespread deployment of vocal computing technology.
Secure Voice Authentication
If you want to lose a bit of sleep tonight, listen to this clip:

This is approximately the state of the art voice cloning technology; it’s a machine learned model of Donald Trump’s voice that can be made to say whatever a user puts in the textbox. While the technology is not perfect yet, we’re pretty close to the day when you as a human will cease to be able to distinguish between a real human voice and a machine learned clone.
When that day comes, we’ll all probably realize how much we’ve grown to rely upon voice as an authentication mechanism. When we hear the sound of a person’s voice, we believe that that person spoke those words. In a world of human equivalent voice cloning technology, that assumption breaks down.
So, how are we going to rearchitect our social processes and technology to deal with the fact that voices can no longer be trusted? Google Home’s ability to authenticate users by voice, called Voice Match, seems a bit problematic. Adding a spoken password doesn’t seem like much of an improvement from a security perspective. Adding a camera capable of facial recognition still leaves open all sorts of attack vectors.
For important business and governmental conversations, video of the participants could provide some form of verification of identity, but technology for puppeteering video is also coming online, allowing you to pretend to be anyone you have sufficient video data of.
Security is a pervasive challenge throughout technology. There are no easy answers to any of the concerns in this section, but I still believe that there are opportunities in this area for technology that can definitively distinguish between a human voice and its machine learned clone. This may not seem to be a product in high demand today, but it could be a valuable feature of telecommunications products in the very near future.
Machine-to-Machine Communication for Voice Tech
Alexa, talk to Google Home and order me a can of red bull for every morning meeting I have scheduled this week.
On a cheerier note, there are some upsides to having all of these advances in vocal computing and related technology: shiny new toys. Smart speakers have now successfully introduced millions of consumers to why they would want to talk to a machine. Now, we’re just going to see more voice agents in more places like cars, watches, earbuds, and AR/VR headsets.
All of these voice agents use the same interface: speech, which means that they can now talk to each other.

Fun videos like this are just the tip of the iceberg. Intelligent agents will eventually talk to other agents, and they’ll even get useful work done. In my past work, we saw this bot-to-bot interaction happen with Amy, the meeting-scheduling AI I worked on at x.ai. With technology deployed to consumers, such interactions are inevitable; consumers do whatever they want with tech that they’ve purchased.
We’ve seen machine-to-machine interactions at scale before. In adtech and programmatic trading, huge portions of the decisions within those given markets are made by machines in milliseconds at a scale beyond what could be done with humans alone. From my experience as a machine learning developer for both of those industries, there are some key bits of enabling infrastructure that allow for large-scale machine-to-machine interactions in those markets. For example, those industries have adopted machine-readable formats for data interchange.
For vocal computing, no such formats exist. An Echo talks exactly the same to a human as it does to a Google Home. If those data interchange protocols for machine-to-machine interaction did exist, they could allow for data interchange to occur at frequencies above what humans can hear, making them effectively silent. They could also be much higher bandwidth if they didn’t have to represent their data in the form of spoken words arranged in sentences. Instead, a dense binary interchange format could be used. While we’re at, let’s propose that there’s some nice error compensating properties to our hypothetical protocol, to ensure that no audio packet is lost. Finally, let’s add in mechanisms to ensure security to enable us to make transactions and provide personal information with confidence.
These are all problems that we have solved for other networking technologies for which there are standard approaches. The challenge now is taking advantage of the new possibilities enabled by rooms full of talking machines that could be made to collaborate together through machine-to-machine conversations.
Machine Learning
The opportunities in this section involve developing new machine learning capabilities and using them in new ways.
End-to-End Learning for Automatic Speech Recognition
This is a technology that already exists but hasn’t really been applied to all of the areas where it could be useful. End-to-end learning refers to a technique whereby a given concept is learned by a single, unified learning system (e.g. a single deep neural network) as opposed to multiple, specialized stages of processing typically assumed to be somewhat informed by human intuition. The benefits of end-to-end learning are typically something like:
- Reduce the amount of human knowledge required to produce an effective system
- Achieve greater generality, allowing the system to function over a broader range of concepts, with the same architecture
The second property is really a consequence of the first. Specialized sub-systems designed by humans can be brittle due to assumptions baked into their designs. By turning all of a given problem into a single learning problem, a single neural architecture can be capable of addressing a broad range of related concepts. For example, Baidu was very successful in using this approach to build automatic speech recognizers (ASRs) for English and Mandarin, two very different languages.

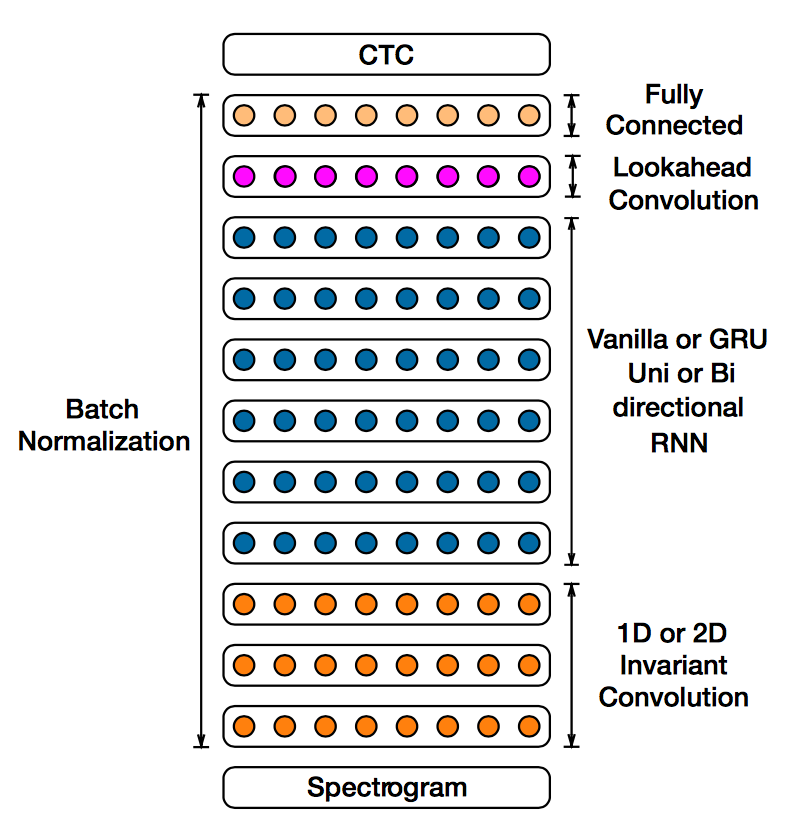
It’s not just about being able to handle two well-studied languages. The end-to-end learning approach means that ASRs can be customized per application without the need for human intuition about the problem. Instead, application-specific training data in combination with a sufficiently general neural architecture can be used to build a highly accurate speech recognition system. This presents a plausible approach for building application-specific ASRs for things like cars, watches, earbuds, AR/VR headsets, and so on. No fundamental problems need to be solved; we just need to collect the training data.
Superhuman Vocal Capabilities
We often talk about particular machine learning problems in terms of human equivalence: has the most capable system in the world performed as well as humans typically do on a given task. For nicely bounded problems like board games, AI systems have been fantastically successful. For more open-ended problems like music composition, human equivalence is trickier to measure and achieve.
Human equivalence isn’t the goal in every problem, though. While humans can’t flap their arms and fly, we were able to build capabilities that only birds had via airplanes and then surpass even birds and the rest of the animal kingdom by flying all the way into outer space.
There are still opportunities to build capabilities in vocal computing technology that surpass what humans are capable of on their own. Sophisticated microphones can already pick up sounds beyond what a human ear can percieve. So, what happens when we stop trying to build a courtroom stenographer and start trying to build Daredevil?
An interesting new class of technology attempts to reason about voice data in ways that surpass what a human can do. NeuroLex and similar other companies are building technologies to detect diseases using only voice data, something pretty far beyond what humans can do.
A bit closer to human capabilities, Nexmo and others are building systems to detect customer’s sentiment on customer service calls. While we humans can do some sentiment detection via voice, broadly deployed voice sentiment detection AIs could eventually surpass human abilities in this domain and produce highly empathic systems that know more about what a human is feeling than other humans do.
Machine-Human Dialogue Training Sets
This one is a bit of a borderline case. Amazon, Google, and Apple are all amassing pretty large training datasets of humans talking to machines. Of course, these datasets aren’t shared with the larger developer community directly, and there just aren’t that many companies who have such datasets in the first place. So, most developers don’t have access to anything like this.
One of the most powerful capabilities that could be built with this data is an automatic speech recognizer (ASR) that was trained specifically on instances of humans talking to machines. Anyone who has every listened to people talk to machines knows that people change how they speak when they talk to a machine.


If the ASR that backs the voice agent was built on human-human conversations, then it may be unprepared for the differences in the human’s speech as compared to the properties of the speech used to train the ASR. In machine learning terms, this can be viewed as a form of concept drift, which is a pernicious issue in real world machine learning that isn’t trivial to address. One solution would be to train on datasets of machine-human dialogues, as presumably Amazon, Google, and Apple are doing today.
But for developers who aren’t at those companies or who can’t integrate cloud APIs into their products, what other solutions exist? One really interesting possibility is to build the sort of systems described in the next section.
Adaptive Speech Recognition, Natural Language Understanding, and Speech Synthesis
Often in machine learning, certain assumptions around the architecture of our overall system are left implicit or at least glossed over. Back when I got started in the field, it was extremely rare to come across people discussing or developing crucial system components like model servers. It was not uncommon to see discussions of feature selection that included no mention of how feature sets were managed and how selection decisions were stored and reused during serving. Eventually, I got irritated enough by this imbalance in focus in machine learning engineering that I wrote a whole book that tried to cover the full range of system components that cooperate in a full machine learning system.
One of the underdiscussed assumptions I see now in voice tech is that the models in use are pretrained static models. This assumption corresponds to common practice for automatic speech recognizers and speech synthesis systems both, so it’s a valid assumption, but it’s not the only way that machine learning systems can be built. Various techniques can be used to continuously update models in realtime to make them more responsive to real-world changes in the environment.
Applying these techniques at the ASR level could allow for better speech recognition performance in adverse environments (e.g. in a car, walking on a street, a noisy room). At the natural language understanding level (NLU), there are all sorts of possibilities for more contextually dynamic behavior of models. For example, in a customer service context, when a NLU model detects that a sufficient fraction of the ASRs output is incomprehensible, it could dynamically request human annotation of the problem data for immediate reuse, rather than simple escalation to a human agent.
Speech synthesis systems are typically designed with a bit more dynamism in mind. Using formats like SSML, developers can get more dynamic behavior out of synthesized voices for things like whispering or emphasis, but the models used still remain constant. A dynamically retrained speech synthesis model could do even more. It could speak in a way that highly empathetic humans do: mimicking the speaker to create more affinity or altering its vocal properties when a human is having trouble hearing in a particular environment.