
第1章-資料探索(2)-資料預處理之Python實現
簡介
Python中,在資料處理這方面最流行的包應當是屬於Pandas了。Pandas與Scipy一樣,都是基於NumPy這個包開發出來的,所以使用時,都需要引用Numpy。Pandas中的DataFrame與R語言中的資料框的設計理念基本是一致的。不光如此,除了是DataFrame資料型別以外,Pandas還提供時間序列型別Series,以及面板型別Panel。
import numpy as np
import pandas as pd
from pandas import Series, DataFrame, Panel
接下來,我們先來介紹一下Pandas的基本使用方法,然後再根據前一講用Pandas進行實現,資料型別主要介紹DataFrame。下面的實現,預設以及按上述程式碼匯入np以及pd、DataFrame等。
正文
一,Pandas介紹
1,I/O 資料的匯入與匯出
(1) 利用pandas的函式匯入資料

read_csv() / read_table() 的詳細引數

逐塊讀入資料示例
chunker = pd.reade_csv(path, chunksize = 100)
tot = Serise([])
for piece in chunker :
tot = tot.add(piece[‘key’],value_counts(), fill_value= 0)
tot = tot.order(ascending=False)
(2) 利用pandas.DataFrame匯出資料
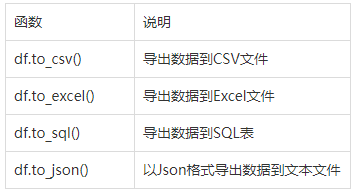
2, 資料的索引與篩選
(1) pandas 會為你自動從0生成索引值
DataFrame是一個表格型的資料結構,它含有一組有序的列,每列可以是不同的值型別(數值,字串,布林值等)。可以與Python中的字典型別互轉。
data = {'state':['fe','te','eea'],'year':[2018,2017,2016],'avgage':[87,85,89]}
frame = DataFrame(data)
print frame
資料中,預設的0,1,2即為自動生成的索引值。
|avgage | state | year
0 | 87 | fe | 2018
1 | 85 | te | 2017
2 | 89 | eea | 2016
(2) 根據索引選取資料
-
通過冒號選取行
例:frame[:2] -
通過布林陣列選取行
例:frame[frame['year']==2018] -
通過列索引選取列
例:frame[ 'year', 'state'] ] -
通過ix選取,(或 iloc操作相同)
選取某行:obj.ix[val]
選取某列:obj.ix[ : , val]
同時選中某行和某列:obj.ix[ val1, val2 ]
3,資料的函式應用
Numpy的通用函式ufunc是可用於pandas,此外,另外我們還可以使用下面幾種常用的方式,詳細點選此處檢視詳情。
- DataFrame.apply()
- DataFrame.applymap()
- DataFrame.aggregate()
- DataFrame.transform()
例:
自定義一極差函式:f = lambda x: x.max() -x.min()
計算每列的極差值: frame.apply(f, axis = 1)
下面列出一些常用的自帶函式



4,資料缺失的處理

我們把之前的例子改一下,通過np.nan來賦值缺失值。
data = {'state':['fe',np.nan,'eea'],'year':[2018,2017,2016],'avgage':[87,85,np.nan]}
frame = DataFrame(data,columns=['year','state','avgage'])
print frame
(1) 檢視哪些元素有缺失值isnull()
frame.isnull()
返回值如下
year state avgage
0 False False False
1 False True False
2 False False True
(2)count統計,忽略NaN
frame.count()統計時,會跳過NaN
類似的,還有sum()等
(3)fillna填充缺失值
-
所有缺失值,填充為統一值(數值或字元均可)
例,所有缺失值填充為0:frame.fillna(0) -
限制填充缺失值
例,選取state列,僅填充第一個缺失值:frame['state'].fillna(0, limit=1)
5,合併資料集
pandas自帶的資料大體有三個方法
- pd.merge
- pd.join,類似merge簡化版
- pd.concat,軸向連線,類似於numpy.concatenate(),預設情況下,concat中的axis=0,表示新增行
pd.merge引數如下

pd.merge(df1, df2, how='innner', on = 'key')
表示:用df1中的key列 與df2中的key列進行內關聯,合併取得資料。
pd.merge( df1, df2 , left_on = 'key', right_index = True, how = 'outer')
表示:用df1中的key列 與df2中索引列進行外關聯,合併取得資料。
6,資料的聚合與分組運算
DataFrame.groupby()
- 1,根據列分組:dataframe.groupby([列1,列2]).mean()
⚠️分組中的缺失值預設會被排除在外計算 - 2,根據字典或Series分組:dataframe.groupby(字典或Series).mean()
- 3,根據函式分組:dataframe.groupby(len).mean() ,比如根據長度len來分組
- 4,根據索引分組:dataframe.groupby(level=‘city’,axis=1).count()
groupby將會產生一個GroupBy物件,該物件可以進行迭代、運用聚合函式等
可以用groupby物件.agg(func), 通過agg使用自己寫的的聚合函式func
agg(),可選取多個函式,agg(‘mean’, ‘count’, ’sum’, ’median’, ’std’, ’var’, ’min’, ’max’, ’prod’, ’first’, ’last’ )
二,利用Pandas進行資料預處理
前一節講過,預處理的四個步驟,接下來演示相應的操作:
資料清洗:SINCE原則處理資料
資料整合:pandas.merge方法
資料變換:pandas、scipy、numpy的處理
資料規約:會放到第五章進行講解
1,資料清洗
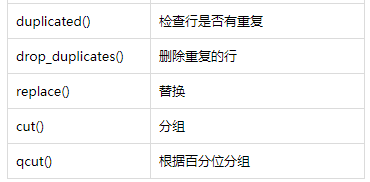
- Simple原則: 發現重複與冗餘
data = {'state':['a','b','c','a','b','c'],'year':[2018,2016,2017,2018,2016,2017],'avgage':[87,85,88,87,85,88]}
frame = DataFrame(data,columns=['year','state','avgage'])
print frame
frame[frame.duplicated()].count() #統計所有資料全部重複的有多少
frame[frame.duplicated()] #統計重複的資料是哪幾個
year state avgage
3 2018 a 87
4 2016 b 85
5 2017 c 88
frame.drop_duplicates() #把重複的刪除,但是不會刪除原始資料
對於冗餘,與資料規約的步驟是基本一致的,會合併到資料規約的步驟來計算。
- Integral原則:處理缺失處理
處理缺失值的具體理論方法,參見第六章,此處僅介紹一下,如何發現以及填充缺失值。
data = {'state':['a','b','c',np.nan,'b','c'],'year':[2018,2016,np.nan,2018,2016,2017],'avgage':[87,85,88,np.nan,85,88]}
frame = DataFrame(data,columns=['year','state','avgage'])
print frame
frame.count() # 統計了每列剔除缺失值以後的個數
frame.isnull().sum() # 統計了每列缺失值的個數
frame.fillna(0) #把缺失值都填充為0,此處也可以是字串,不過很少有把缺失值填充統一值的
對於不同的列,動態指定不同列的填充值
frame.fillna(frame.mean()) # 將每一列的均值填充到各列自己的缺失值中,同理最大最小值等統計值均可。
# 可以看到,只有數值型的列,適合用均值這種統計指標,對於列state, 我們可以用頻數高的眾數
# 當然眾數可能不是唯一的,所以我們取第一個眾數,來填充state列
frame['state'].fillna(frame.mode()['state'][0])
# 運用自定義函式來填充, 假設自定義函式就是取眾數的第一個值
f = lambda x: x.fillna(x.mode()[0])
frame.apply(f)
- Normal原則:統一格式並標準化
統一格式,基本就是修改並賦值的過程,此處不再討論。
對於數值型變數,我們有兩種方式,標準化:
歸一化公式
f = lambda x: ( x - min(x) )/ ( max(x) - min(x) )
frame['avgage'].transform(f)
標準化公式
f = lambda x: ( x - x.mean() )/ x.std()
frame['avgage'].transform(f)
- Consistent一致性原則:就要以業務與經驗為主來判斷
- Effective有效原則:錯誤與異常
對於異常值,我們最簡單的方法是檢視樣本資料的分佈來得到結果。根據箱線圖的三個重要的分位數,在Q3+1.5IQR和Q1-1.5IQR的範圍以外的,認為是異常值,或者叫做離群點。
q1, q2, q3 = frame['avgage'].quantile([0.25,0.5,0.75])
IQR = q3-q1
O1 = q1 - 1.5*IQR
O2 = q3 + 1.5*IQR
(frame['avgage'] < O1) | (frame['avgage'] > O2 ) # 是否異常點的判斷
此外,還有專門研究異常檢測的方法論,可以參照第十八章異常檢測,來進行學習。
2,資料整合:
pandas.merge方法
dat1 = DataFrame({'key':['a','b','d'],
'value1':[12,3,5],
'year':[1998,1999,2001]})
dat2 = DataFrame({'key':['a','c','e'],
'value2':[43,32,10],
'mon':[12,10,10]})
# 通過key值內關聯起來
pd.merge(dat1,dat2,on = 'key',how='inner')
key value1 year mon value2
0 a 12 1998 12 43
# 通過key值左關聯起來
pd.merge(dat1,dat2,on = 'key',how='left') # 或
pd.merge(dat1,dat2,left_on = 'key',right_on = 'key',how='left')
key value1 year mon value2
0 a 12 1998 12.0 43.0
1 b 3 1999 NaN NaN
2 d 5 2001 NaN NaN
3,資料變換:
將數值屬性拆分成分類屬性
dat = DataFrame({'value':[12,3,5,3,5,6,7,8,2,5,8,1,4,8]})
#將資料分為三組,並且命名組1、2、3;
result = pd.cut(dat['value'],3,labels=['組1','組2','組3'])
#將分組變數dummy化
dum = pd.get_dummies(result)
#合併這些結果
pd.concat([dat,result,dum],axis=1)