
利用jieba,word2vec,LR進行搜狐新聞文字分類 基於jieba,TfidfVectorizer,LogisticRegression進行搜狐新聞文字分類
一、簡介
1)jieba
中文叫做結巴,是一款中文分詞工具,https://github.com/fxsjy/jieba
2)word2vec
單詞向量化工具,https://radimrehurek.com/gensim/models/word2vec.html
3)LR
LogisticRegression中文叫做邏輯迴歸模型,是一種基礎、常用的分類方法
二、步驟
0)建立jupyter notebook
桌面新建名字為基於word2vec的文件分類的資料夾,並進入該資料夾,按住shift,滑鼠點選右鍵,然後選擇在此處開啟命令視窗,然後在dos下輸入:jupyter notebook
新建一檔案:word2vecTest.ipynb
1)資料準備
連結:https://pan.baidu.com/s/1mR87V40bUtWgUBIoqn4lOw 密碼:lqe4
訓練集共有24000條樣本,12個分類,每個分類2000條樣本。
測試集共有12000條樣本,12個分類,每個分類1000條樣本。
下載並解壓到基於word2vec的文件分類資料夾內:

檢視資料發現檔案分兩列:
import pandas as pd
train_df = pd.read_csv('sohu_train.txt', sep='\t', header=None)
train_df.head()
檢視train每個分類的名字以及樣本數量:
for name, group in train_df.groupby(0):
print(name,'\t', len(group))
#或者通過columns來檢視
train_df.columns = ['Subject', 'Content']
train_df['Subject'].value_counts().sort_index()

同樣的方法檢視test每個分類的名字以及樣本數量:
test_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
for name, group in test_df.groupby(0):
print(name, '\t', len(group))

關於groupby函式,我們通過檢視name和group加以理解(變數group是一個GroupBy物件,它實際上還沒有進行任何計算):
for name, group in df_train.groupby(0):
print(name)
print(group)

其中科技即打印出來的name,後面的內容即group物件內容,包含兩列,第一列為科技,第二列為內容(注意:該train資料集包含了12個分類,這裡只是展示了name為科技的圖片,其他name結構類似)
2)分詞
安裝jieba:pip install jieba
對訓練集的24000條樣本迴圈遍歷,使用jieba庫的cut方法獲得分詞列表賦值給變數cutWords。
判斷分詞是否為停頓詞,如果不為停頓詞,則新增進變數cutWords中,檢視一下stopwords.txt檔案:


從上我們發現:這些停頓詞語都是沒用用的詞語,對我們文字分類沒什麼作用,所以在分詞的時候,將其從分詞列表中剔除
import jieba, time
train_df.columns = ['分類', '文章']
#stopword_list = [k.strip() for k in open('stopwords.txt', encoding='utf-8').readlines() if k.strip() != '']
#上面的語句不建議這麼寫,因為readlines()是一下子將所有內容讀入記憶體,如果檔案過大,會很耗記憶體,建議這麼寫
stopword_list = [k.strip() for k in open('stopwords.txt', encoding='utf-8') if k.strip() != '']
cutWords_list = []
i = 0
startTime = time.time()
for article in train_df['文章']:
cutWords = [k for k in jieba.cut(article) if k not in stopword_list]
i += 1
if i % 1000 == 0:
print('前%d篇文章分詞共花費%.2f秒' % (i, time.time() - startTime))
cutWords_list.append(cutWords)
本人電腦配置低(在linux下速度很快,本人用ubuntu,前5000篇文章分詞共花費373.56秒,快了近三分之二),用時:

然後將分詞結果儲存為本地檔案cutWords_list.txt,程式碼如下:
with open('cutWords_list.txt', 'w') as file:
for cutWords in cutWords_list:
file.write(' '.join(cutWords) + '\n')
為了節約時間,將cutWords_list.txt儲存到本地,連結:https://pan.baidu.com/s/1zQiiJGp3helJraT3Sfxv5w 提取碼:g6c7
載入分詞檔案:
with open('cutWords_list.txt') as file:
cutWords_list = [ k.split() for k in file ]
檢視分詞結果檔案:cutWords_list.txt,可以看出中文分詞工具jieba分詞效果還不錯:

3)word2vec模型
安裝命令:pip install gensim
呼叫gensim.models.word2vec庫中的LineSentence方法例項化行模型物件(為避免warning資訊輸出,匯入warning 模組):
import warnings
warnings.filterwarnings('ignore')
from gensim.models import Word2Vec
word2vec_model = Word2Vec(cutWords_list, size=100, iter=10, min_count=20)
sentences:可以是一個list,對於大語料集,建議使用BrownCorpus,Text8Corpus或lineSentence構建
size:是指特徵向量的維度,預設為100。大的size需要更多的訓練資料,但是效果會更好,推薦值為幾十到幾百
min_count:可以對字典做截斷,詞頻少於min_count次數的單詞會被丟棄掉, 預設值為5
呼叫Word2Vec模型物件的wv.most_similar方法檢視與攝影含義最相近的詞
wv.most_similar方法有2個引數,第1個引數是要搜尋的詞,第2個關鍵字引數topn資料型別為正整數,是指需要列出多少個最相關的詞彙,預設為10,即列出10個最相關的詞彙
wv.most_similar方法返回值的資料型別為列表,列表中的每個元素的資料型別為元組,元組有2個元素,第1個元素為相關詞彙,第2個元素為相關程度,資料型別為浮點型
word2vec_model.wv.most_similar('攝影')

wv.most_similar方法使用positive和negative這2個關鍵字引數的簡單示例。檢視女人+先生-男人的結果,程式碼如下:
word2vec_model.most_similar(positive=['女人', '先生'], negative=['男人'], topn=1)

檢視兩個詞的相關性,如下圖所示:
word2vec_model.similarity('男人', '女人')
word2vec_model.similarity('攝影', '攝像')

儲存Word2Vec模型為word2vec_model.w2v檔案,程式碼如下:
word2vec_model.save( 'word2vec_model.w2v' )
4)特徵工程
對於每一篇文章,獲取文章的每一個分詞在word2vec模型的相關性向量。然後把一篇文章的所有分詞在word2vec模型中的相關性向量求和取平均數,即此篇文章在word2vec模型中的相關性向量(用一篇文章分詞向量的平均數作為該文章在模型中的相關性向量)
例項化Word2Vec物件時,關鍵字引數size定義為100,則相關性矩陣都為100維
getVector函式獲取每個文章的詞向量,傳入2個引數,第1個引數是每篇文章分詞的結果,第2個引數是word2vec模型物件
每當完成1000篇文章詞向量轉換的時候,列印花費時間
最終將24000篇文章的詞向量賦值給變數X,即X為特徵矩陣
對比文章轉換為相關性向量的4種方法花費時間。為了節省時間,只對比前5000篇文章轉換為相關性向量的花費時間
4.1 ) 第1種方法,用for迴圈常規計算
def getVector_v1(cutWords, word2vec_model):
count = 0
article_vector = np.zeros( word2vec_model.layer1_size )
for cutWord in cutWords:
if cutWord in word2vec_model:
article_vector += word2vec_model[cutWord]
count += 1
return article_vector / count
startTime = time.time()
vector_list = []
i = 0
for cutWords in cutWords_list[:5000]:
i += 1
if i % 1000 == 0:
print('前%d篇文章形成詞向量花費%.2f秒' % (i, time.time() - startTime))
vector_list.append( getVector_v1(cutWords, word2vec_model) )
X = np.array(vector_list)
print('Total Time You Need To Get X:%.2f秒' % (time.time() - startTime) )

4.2)第2種方法,用pandas的mean方法計算
import time
import pandas as pd
import numpy as np
def getVector_v2(cutWords, word2vec_model):
vector_list = [ word2vec_model[k] for k in cutWords if k in word2vec_model]
vector_df = pd.DataFrame(vector_list)
cutWord_vector = vector_df.mean(axis=0).values
return cutWord_vector
startTime = time.time()
vector_list = []
i = 0
for cutWords in cutWords_list[:5000]:
i += 1
if i % 1000 ==0:
print('前%d篇文章形成詞向量花費%.2f秒' %(i, time.time()-startTime))
vector_list.append( getVector_v2(cutWords, word2vec_model) )
X = np.array(vector_list)

4.3)用numpy的mean方法計算
import time
import pandas as pd
import numpy as np
def getVector_v2(cutWords, word2vec_model):
vector_list = [ word2vec_model[k] for k in cutWords if k in word2vec_model]
vector_df = pd.DataFrame(vector_list)
cutWord_vector = vector_df.mean(axis=0).values
return cutWord_vector
startTime = time.time()
vector_list = []
i = 0
for cutWords in cutWords_list[:5000]:
i += 1
if i % 1000 ==0:
print('前%d篇文章形成詞向量花費%.2f秒' %(i, time.time()-startTime))
vector_list.append( getVector_v2(cutWords, word2vec_model) )
X = np.array(vector_list)
print('Total Time You Need To Get X:%.2f秒' % (time.time() - startTime) )

4.4)第4種方法,用numpy的add、divide方法計算
import time
import numpy as np
import pandas as pd
def getVector_v4(cutWords, word2vec_model):
i = 0
index2word_set = set(word2vec_model.wv.index2word)
article_vector = np.zeros((word2vec_model.layer1_size))
for cutWord in cutWords:
if cutWord in index2word_set:
article_vector = np.add(article_vector, word2vec_model.wv[cutWord])
i += 1
cutWord_vector = np.divide(article_vector, i)
return cutWord_vector
startTime = time.time()
vector_list = []
i = 0
for cutWords in cutWords_list[:5000]:
i += 1
if i % 1000 == 0:
print('前%d篇文章形成詞向量花費%.2f秒' %(i, time.time()-startTime))
vector_list.append( getVector_v4(cutWords, word2vec_model) )
X = np.array(vector_list)
print('Total Time You Need To Get X:%.2f秒' % (time.time() - startTime) )

因為形成特徵矩陣的花費時間較長,為了避免以後重複花費時間,把特徵矩陣儲存為檔案。使用ndarray物件的dump方法,需要1個引數,資料型別為字串,為儲存檔案的檔名,載入資料也很方便,程式碼如下:
X.dump('articles_vector.txt')
#載入資料可以用下面的程式碼
X = np.load('articles_vector.txt')
5)模型訓練、模型評估
1)標籤編碼
呼叫sklearn.preprocessing庫的LabelEncoder方法對文章分類做標籤編碼
import pandas as pd
from sklearn.preprocessing import LabelEncoder
train_df = pd.read_csv('sohu_train.txt', sep='\t', header=None)
train_df.columns = ['分類', '文章']
labelEncoder = LabelEncoder()
y = labelEncoder.fit_transform(train_df['分類'])
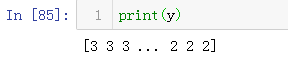
2)LR模型
呼叫sklearn.linear_model庫的LogisticRegression方法例項化模型物件
呼叫sklearn.model_selection庫的train_test_split方法劃分訓練集和測試集
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2, random_state=0) logistic_model = LogisticRegression() logistic_model.fit(train_X, train_y) logistic_model.score(test_X, test_y)

3)儲存模型
呼叫sklearn.externals庫中的joblib方法儲存模型為logistic.model檔案
模型持久化官方文件示例:http://sklearn.apachecn.org/cn/0.19.0/modules/model_persistence.html
from sklearn.externals import joblib
joblib.dump(logistic_model, 'logistic.model')
#載入模型
logistic_model = joblib.load('logistic.model')
4)交叉驗證
呼叫sklearn.model_selection庫的ShuffleSplit方法例項化交叉驗證物件
呼叫sklearn.model_selection庫的cross_val_score方法獲得交叉驗證每一次的得分
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import ShuffleSplit from sklearn.model_selection import cross_val_score cv_split = ShuffleSplit(n_splits=5, train_size=0.7, test_size=0.2) logistic_model = LogisticRegression() score_ndarray = cross_val_score(logistic_model, X, y, cv=cv_split) print(score_ndarray) print(score_ndarray.mean())
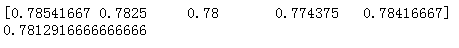
6)模型測試
呼叫sklearn.externals庫的joblib物件的load方法載入模型賦值給變數logistic_model
呼叫DataFrame物件的groupby方法對每個分類分組,從而每種文章類別的分類準確性
呼叫自定義的getVector方法將文章轉換為相關性向量
自定義getVectorMatrix方法獲得測試集的特徵矩陣
呼叫StandardScaler物件的transform方法將預測標籤做標籤編碼,從而獲得預測目標值
import pandas as pd
import numpy as np
from sklearn.externals import joblib
import jieba
def getVectorMatrix(article_series):
return np.array([getVector_v4(jieba.cut(k), word2vec_model) for k in article_series])
logistic_model = joblib.load('logistic.model')
test_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
test_df.columns = ['分類', '文章']
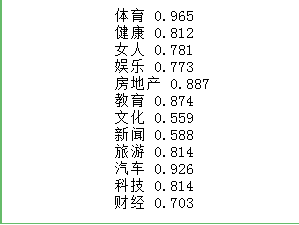
for name, group in test_df.groupby('分類'):
featureMatrix = getVectorMatrix(group['文章'])
target = labelEncoder.transform(group['分類'])
print(name, logistic_model.score(featureMatrix, target))
7)結論
word2vec模型應用的第1個小型專案,訓練集資料共有24000條,測試集資料共有12000條。
經過交叉驗證,模型平均得分為0.78左右。
測試集的驗證效果中,體育、教育、健康、旅遊、汽車、科技、房地產這7個分類得分較高,即容易被正確分類。
女人、娛樂、新聞、文化、財經這5個分類得分較低,即難以被正確分類。
想要學習如何提高文件分類的準確率,請檢視我的另外一篇文章《基於jieba,TfidfVectorizer,LogisticRegression進行搜狐新聞文字分類》
8)致謝
本文參考簡書:https://www.jianshu.com/p/96b983784dae
感謝作者的詳細過程,再次感謝!