
文字處理——基於 word2vec 和 CNN 的文字分類 :綜述 & 實踐(一)
導語
傳統的向量空間模型(VSM)假設特徵項之間相互獨立,這與實際情況是不相符的,為了解決這個問題,可以採用文字的分散式表示方式(例如 word embedding形式),通過文字的分散式表示,把文字表示成類似影象和語音的連續、稠密的資料。
這樣我們就可以把深度學習方法遷移到文字分類領域了。基於詞向量和卷積神經網路的文字分類方法不僅考慮了詞語之間的相關性,而且還考慮了詞語在文字中的相對位置,這無疑會提升在分類任務中的準確率。 經過實驗,該方法在驗證資料集上的F1-score值達到了0.9372,相對於原來業務中所採用的分類方法,有20%的提升。
1.業務背景描述
- 分類問題是人類所面臨的一個非常重要且具有普遍意義的問題,我們生活中的很多問題歸根到底都是分類問題。
- 文字分類就是根據文字內容將其分到合適的類別,它是自然語言處理的一個十分重要的問題。文字分類主要應用於資訊檢索,機器翻譯,自動文摘,資訊過濾,郵件分類等任務。
2.文字分類綜述
2.1 文字分類的發展歷史
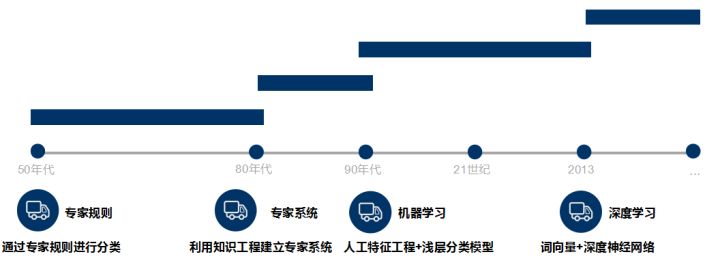
- 文字分類最早可以追溯到上世紀50年代,那時主要通過專家定義規則來進行文字分類
- 80年代出現了利用知識工程建立的專家系統
- 90年代開始藉助於機器學習方法,通過人工特徵工程和淺層分類模型來進行文字分類。
- 現在多采用詞向量以及深度神經網路來進行文字分類。
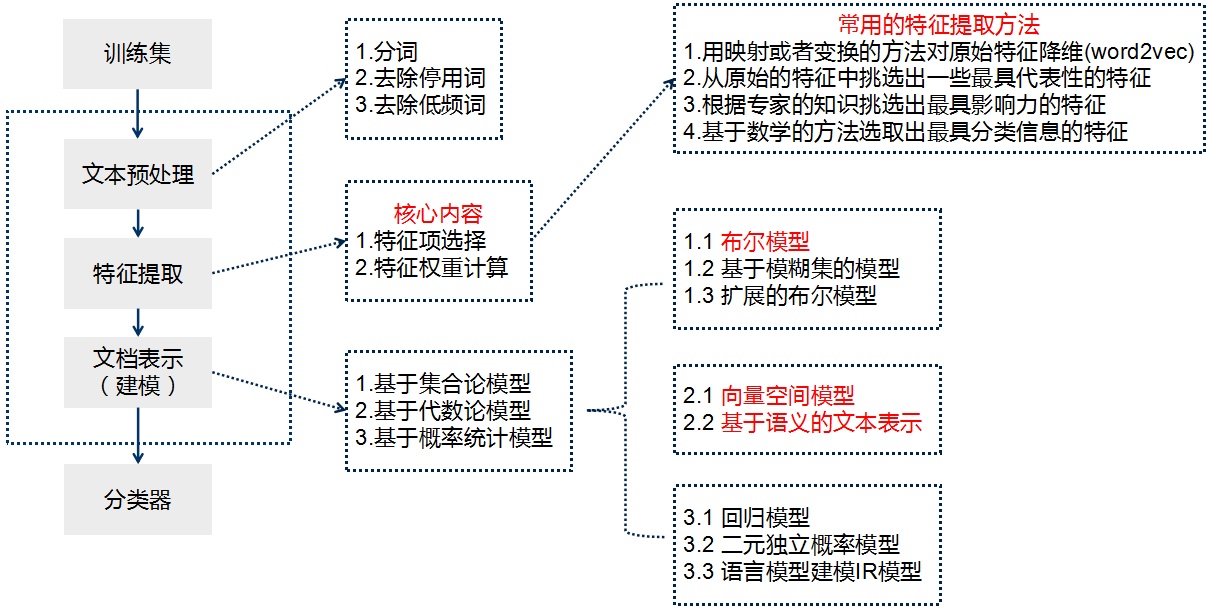
2.2 文字分類的流程
2.3 文件表示
如何把文件表示為演算法能夠處理的結構化資料無疑是文字分類非常重要的環節。
根據文字表示過程所使用的數學方法不同,可以分為以下幾類:
- 1.基於集合論模型
a 布林模型 b. 基於模糊集的模型 c.擴充套件的布林模型 - 2.基於代數論模型
a 向量空間模型(VSM) b 基於語義的文字表示 - 3.基於概率統計模型
a 迴歸模型 b.二元獨立概率模型 c. 語言模型建模IR模型
接下來會詳細介紹一下布林模型、向量空間模型(VSM)、基於語義的文字表示。
2.3.1 布林模型
布林模型:查詢和文件均表達為布林表示式,其中文件表示成所有詞的“與”關係,類似於傳統的資料庫檢索,是精確匹配。
例如:
查詢:2006 AND 世界盃 AND NOT 小組賽
文件1:2006年世界盃在德國舉行
文件2:2006年世界盃小組賽已經結束
文件相似度計算:查詢布林表示式和所有文件的布林表示式進行匹配,匹配成功得分為1,否則為0.
布林模型的優缺點:
優點:簡單、現代搜尋引擎中依然包含了布林模型的理念,例如谷歌、百度的高階搜尋功能。
缺點:只能嚴格匹配,另外對於普通使用者而言構建查詢並不容易。
2.3.2 向量空間模型
向量空間模型:把對文字內容的處理簡化為向量空間的向量計算。並且以空間上的相似度表達文件的相似度。
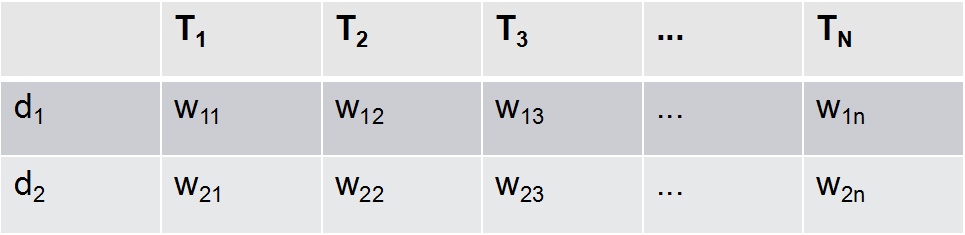
每篇文件由T1、T2、...、Tn一共N個特徵項來表示,並且對應著Wi1、Wi2、... 、Win個權重。通過以上方式,每篇文章都表示成了一個N維的向量。
相似度計算:兩個文件的相似程度可以用兩向量的餘弦夾角來進行度量,夾角越小證明相似度越高。
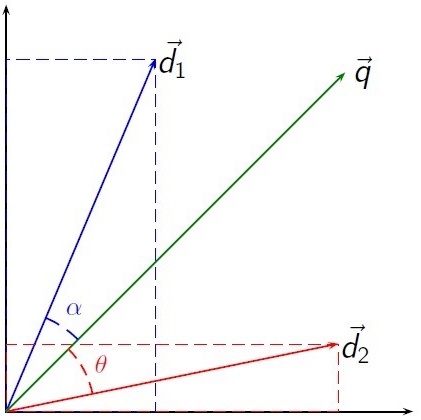
優缺點:
優點:1.簡潔直觀,可以應用到很多領域(文字分類、生物資訊學等)2.支援部分匹配和近似匹配,結果可以排序 3. 檢索效果不錯
缺點:1.理論上支援不夠,基於直覺的經驗性公式。 2. 特徵項之間相互獨立的假設與實際不符。例如,VSM會假設小馬哥和騰訊兩個詞語之間是相互獨立的,這顯然與實際不符。
2.3.3 基於語義的文字表示
基於語義的文字表示方法:為了解決VSM特徵相互獨立這一不符合實際的假設,有人提出了基於語義的文字表示方法,比如LDA主題模型,LSI/PLSI概率潛在語義索引等方法,一般認為這些方法得到的文字表示是文件的深層表示。而word embedding文本分散式表示方法則是深度學習方法的重要基礎。
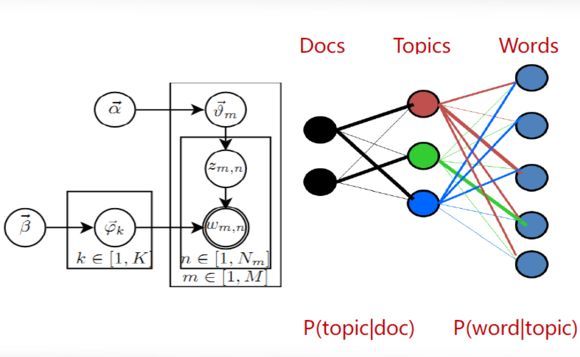
2.3.4 文字的分散式表示:詞向量(word embedding)
文字的分散式表示(Distributed Representation)的基本思想是將每個詞表示為n維稠密,連續的實數向量。
分散式表示的最大優點在於它具有非常強大的表徵能力,比如n維向量每維k個值,可以表徵k的n次方個概念。
事實上,不管是神經網路的影層,還是多個潛在變數的概率主題模型,都是在應用分散式表示。下圖的神經網路語言模型(NNLM)採用的就是文字分散式表示。而詞向量(word embedding)是訓練該語言模型的一個附加產物,即圖中的Matrix C。
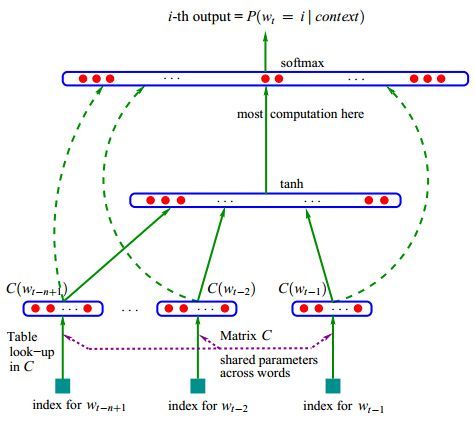
神經網路語言模型(NNLM)
儘管詞的分散式表示在86年就提出來了,但真正火起來是13年google發表的兩篇word2vec的paper,並隨之釋出了簡單的word2vec工具包,並在語義維度上得到了很好的驗證,極大的推動了文字分析的程序。
文字的表示通過詞向量的表示方法,把文字資料從高緯度稀疏的神經網路難處理的方式,變成了類似影象、語言的連續稠密資料,這樣我們就可以把深度學習的演算法遷移到文字領域了。下圖是google的詞向量文章中涉及的兩個模型CBOW和Skip-gram。
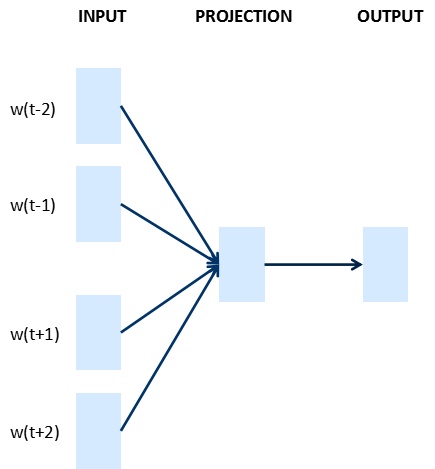
CBOW:上下文來預測當前詞
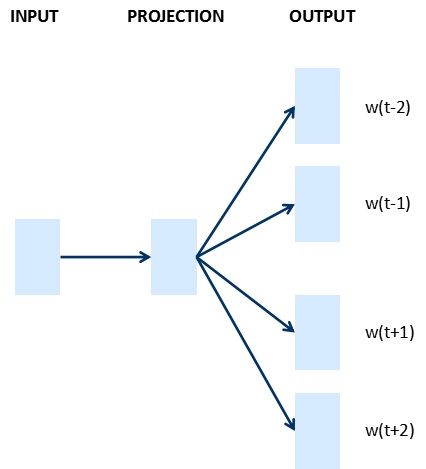
Skip-gram:當前詞預測上下文
2.4 特徵提取
特徵提取對應著特徵項的選擇和特徵權重的計算。
特徵項的選擇就是指根據某個評價指標獨立的對原始特徵項(詞語)進行評分排序,從中選取得分最高的一些特徵項,過濾掉其餘的特徵項。
特徵權重的計算:主要思路是依據一個詞的重要程度與類別內的詞頻成正比(代表性),與所有類別中出現的次數成反比(區分度)。
當選用數學方法進行特徵提取時,決定文字特徵提取效果的最主要因素是評估函式的質量。常見的評估函式主要有如下方法:
2.4.1 TF-IDF
TF:詞頻,計算該詞描述文件內容的能力
IDF:逆向文件頻率,用於計算該詞區分文件的的能力
- 思想:一個詞的重要程度與在類別內的詞頻成正比,與所有類別出現的次數成反比。
- 評價:a.TF-IDF的精度並不是特別高。b.TF-IDF並沒有體現出單詞的位置資訊。
2.4.2 詞頻(TF)
詞頻是一個詞在文件中出現的次數。通過詞頻進行特徵選擇就是將詞頻小於某一閾值的詞刪除。
- 思想:出現頻次低的詞對過濾的影響也比較小。
- 評價:有時頻次低的詞彙含有更多有效的資訊,因此不宜大幅刪減詞彙。
2.4.3 文件頻次法(DF)
它指的是在整個資料集中,有多少個文字包含這個單詞。
- 思想:計算每個特徵的文件頻次,並根據閾值去除文件頻次特別低(沒有代表性)和特別高的特徵(沒有區分度)
- 評價:簡單、計算量小、速度快、時間複雜度和文字數量成線性關係,非常適合超大規模文字資料集的特徵選擇。
2.4.4 互資訊方法(Mutual information)
互資訊用於衡量某個詞與類別之間的統計獨立關係,在過濾問題中用於度量特徵對於主題的區分度。
- 思想:在某個特定類別出現頻率高,在其他類別出現頻率低的詞彙與該類的互資訊較大。
- 評價:優點-不需要對特徵詞和類別之間關係的性質做任何假設。缺點-得分非常容易受詞邊緣概率的影響。實驗結果表明互資訊分類效果通常比較差。
2.4.5 期望交叉熵
交叉熵反映了文字類別的概率分佈和在出現了某個特定詞的條件下文字類別的概率分佈之間的距離
思想:特徵詞t 的交叉熵越大, 對文字類別分佈的影響也越大。
評價:熵的特徵選擇不考慮單詞未發生的情況,效果要優於資訊增益。
2.4.6 資訊增益
資訊增益是資訊理論中的一個重要概念, 它表示了某一個特徵項的存在與否對類別預測的影響。
- 思想:某個特徵項的資訊增益值越大, 貢獻越大, 對分類也越重要。
- 評價:資訊增益表現出的分類效能偏低,因為資訊增益考慮了文字特徵未發生的情
2.4.7 卡方校驗
它指的是在整個資料集中,有多少個文字包含這個單詞。
- 思想:在指定類別文字中出現頻率高的詞條與在其他類別文字中出現頻率比較高的詞條,對判定文件是否屬於該類別都是很有幫助的.
- 評價:卡方校驗特徵選擇演算法的準確率、分類效果受訓練集影響較小,結果穩定。對存在類別交叉現象的文字進行分類時,效能優於其他類別的分類方法。
2.4.8 其他評估函式
- 二次資訊熵(QEMI)
- 文字證據權(The weight of Evidence for Text)
- 優勢率(Odds Ratio)
- 遺傳演算法(Genetic Algorithm)
- 主成分分析(PCA)
- 模擬退火演算法(Simulating Anneal)
- N-Gram演算法
2.5 傳統特徵提取方法總結
傳統的特徵選擇方法大多采用以上特徵評估函式進行特徵權重的計算。
但由於這些評估函式都是基於統計學原理的,因此一個缺點就是需要一個龐大的訓練集,才能獲得對分類起關鍵作用的特徵,這需要消耗大量的人力和物力。
另外基於評估函式的特徵提取方法建立在特徵獨立的假設基礎上,但在實際中這個假設很難成立。
2.6 通過對映和變化來進行特徵提取
特徵選擇也可以通過用對映或變換的方法把原始特徵變換為較少的新特徵
傳統的特徵提取降維方法,會損失部分文件資訊,以DF為例,它會剔除低頻詞彙,而很多情況下這部分詞彙可能包含較多資訊,對於分類的重要性比較大。
如何解決傳統特徵提取方法的缺點:找到頻率低詞彙的相似高頻詞,例如:在介紹月亮的古詩中,玉兔和嬋娟是低頻詞,我們可以用高頻詞月亮來代替,這無疑會提升分類系統對文字的理解深度。詞向量能夠有效的表示詞語之間的相似度。
2.7 傳統的文字分類方法。
- 基本上大部分機器學習方法都在文字分類領域有所應用。
- 例如:Naive Bayes,KNN,SVM,集合類方法,最大熵,神經網路等等。
2.8 深度學習文字分類方法
- 卷積神經網路(TextCNN)
- 迴圈神經網路(TextRNN)
- TextRNN+Attention
- TextRCNN(TextRNN+CNN)
本文采用的是卷積神經網路(TextCNN)
3.實踐及結果
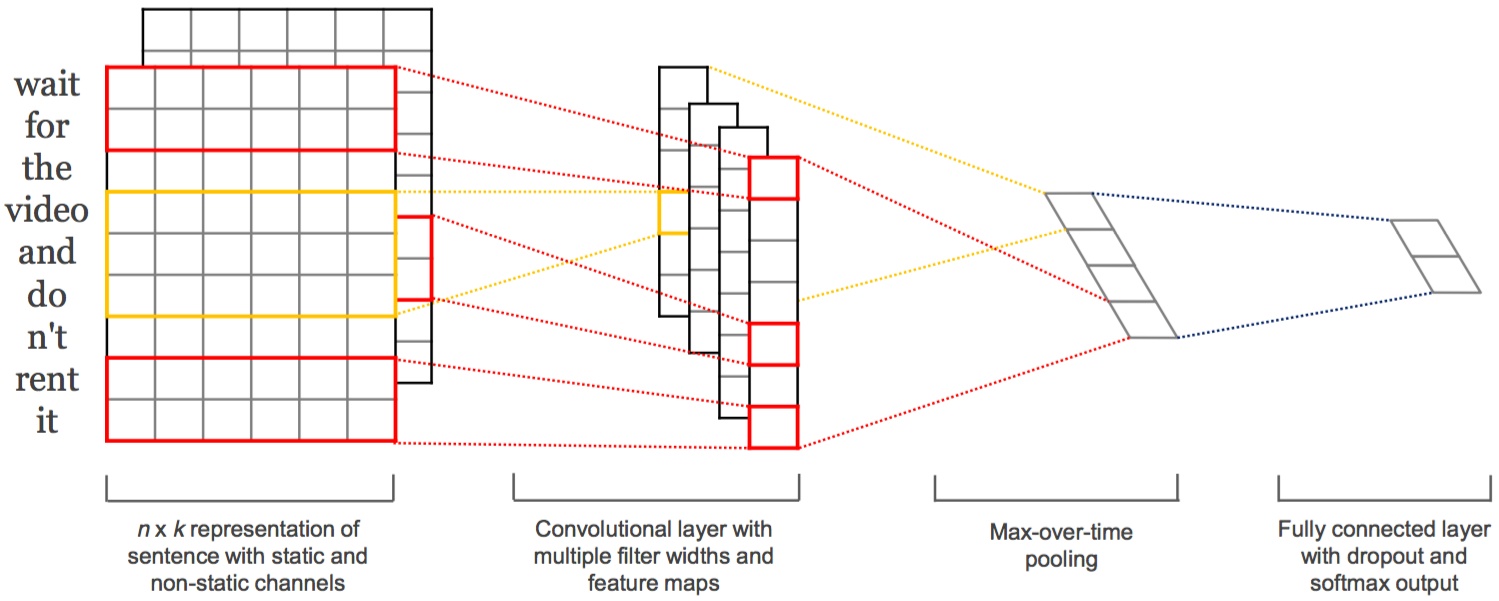
TextCNN網路概覽圖
3.1 實踐步驟
- 根據警情詳情首先訓練詞向量模型,vector.model
- 把警情詳情文字進行分詞,去除停用詞,然後利用詞向量來表示,每篇文件表示為250*200的矩陣(250:文件包含的詞語個數,不夠的以200維-5.0填充,200:每個詞語用200維向量來表示)
- 把警情訓練樣本分割為train-set,validation set,test set。
- 利用設計好的卷積神經網路進行訓練,並測試。
3.2 設計的卷積神經網路結構
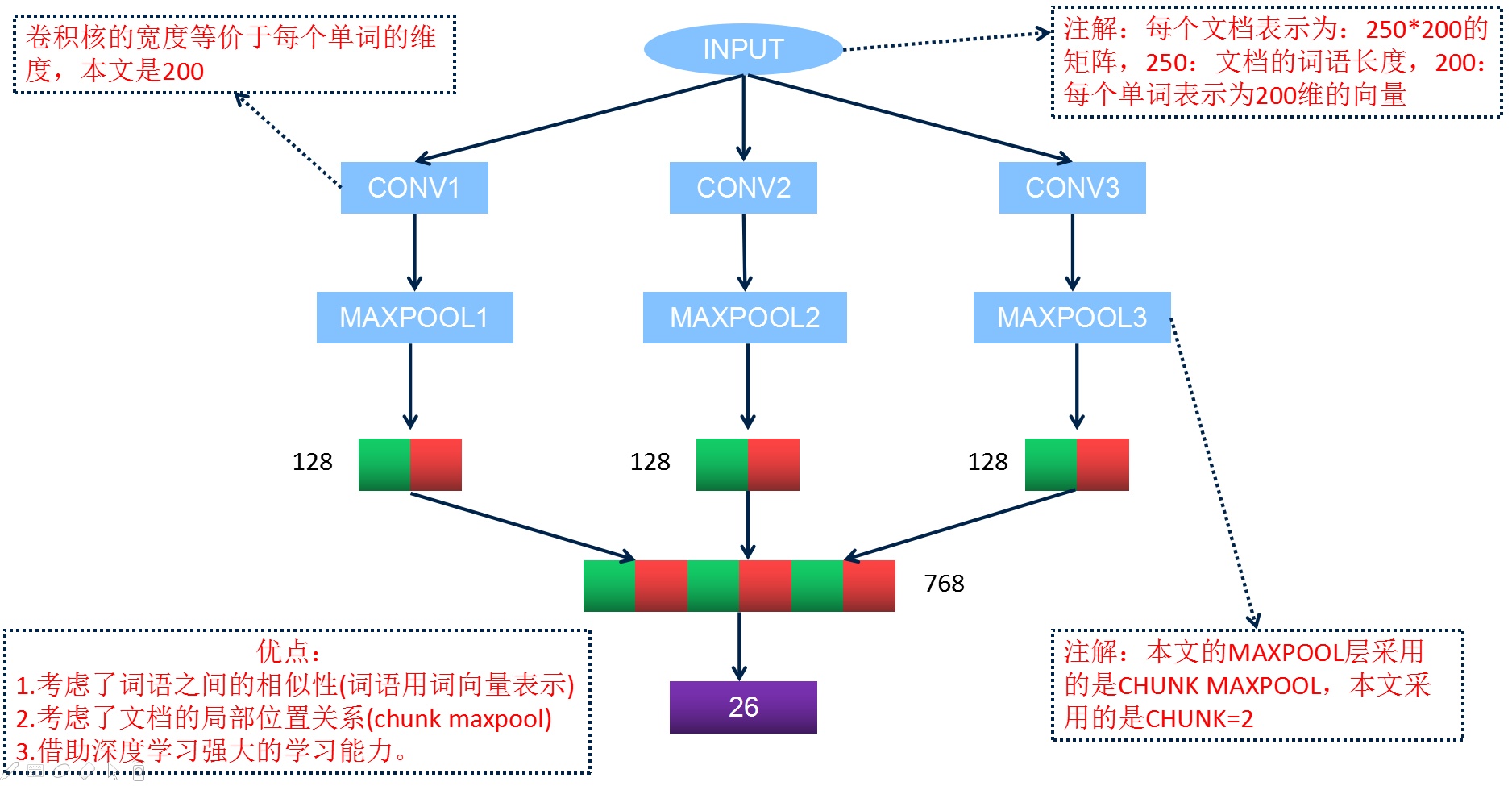
3.3 實驗結果
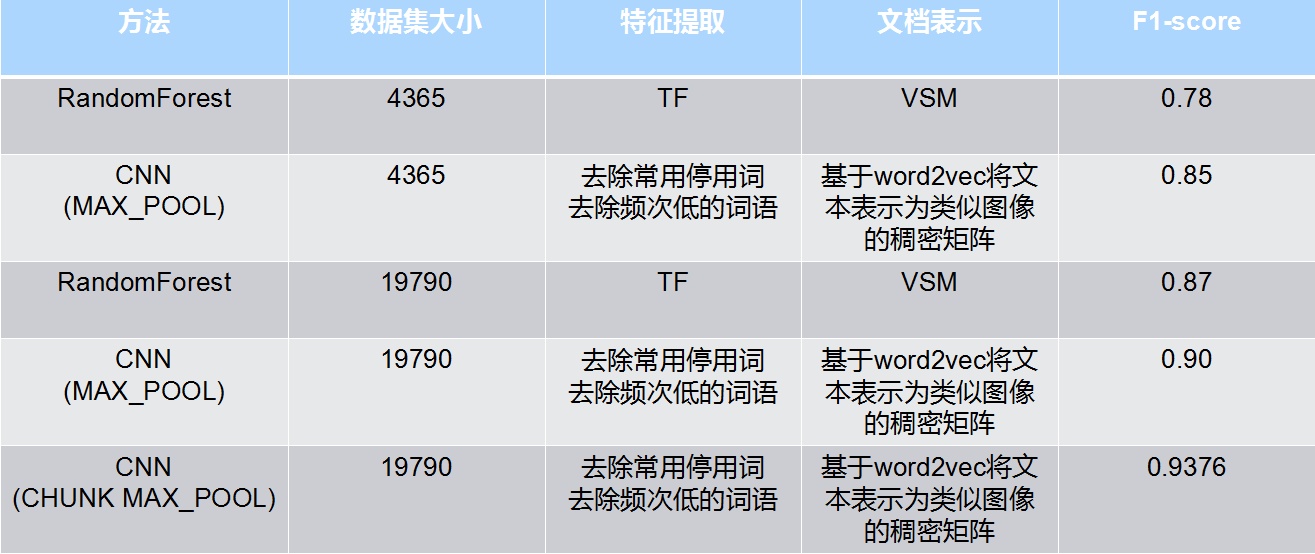
為了檢驗模型在真實資料上的分類準確率,我們又額外人工稽核了1000條深圳地區的案情資料,相較於原來分類準確率的68%,提升到了現在的90%,說明我們的模型確實有效,相對於原來的模型有較大的提升。
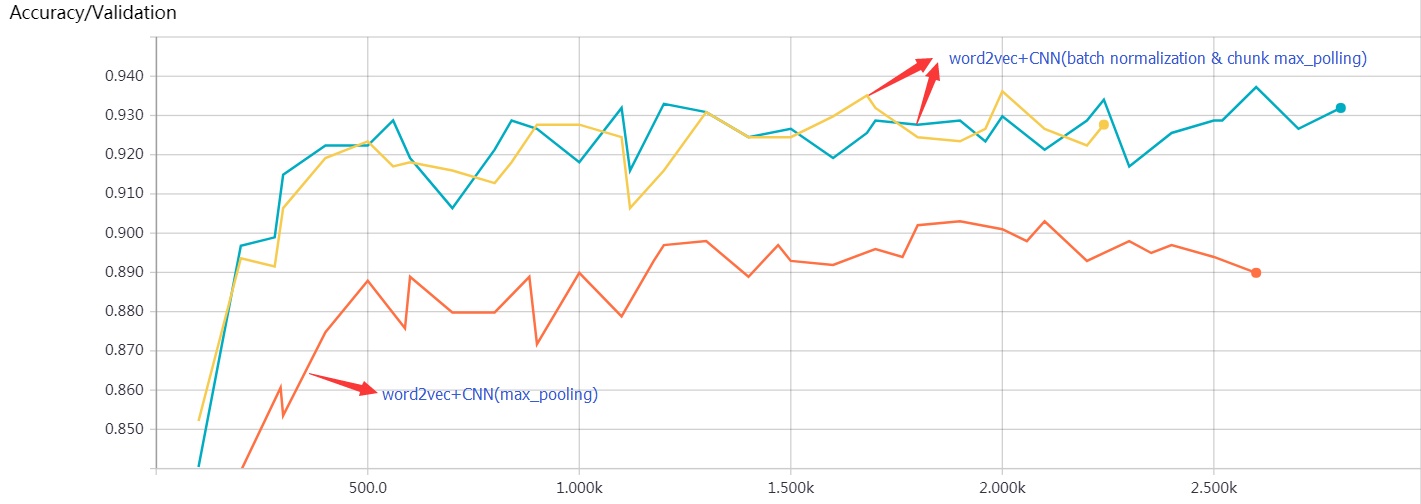
- 紅色:word2vec+CNN(max_pooling)在驗證集上的準確率走勢圖
- 黃色和藍色:word2vec+CNN(batch normalization & chunk max_pooling:2 chunk)在驗證集上的準確率走勢圖
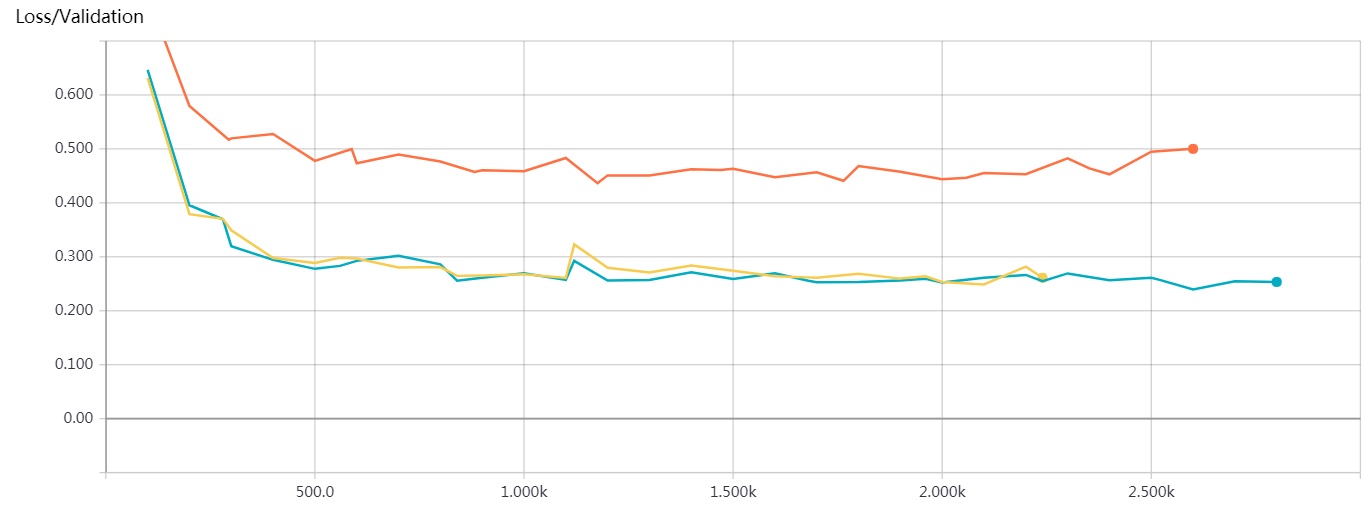
紅色:word2vec+CNN(max_pooling) 在驗證集上的Loss走勢
黃色和藍色:word2vec+CNN(batch normalization & chunk max_pooling:2 chunk)在驗證集上的Loss走勢
3.4 一些感悟
- 一定要理解你的資料
- 做好實驗記錄和分析
- 大量的資料樣本比改善模型來的更有效,但代價也很高
- 閱讀paper,理解原理,開闊視野,加強實踐,敢於嘗試,追求卓越
4. 一些參考文獻
- CSDN-基於tensorflow的CNN文字分類
- CSDN-深度學習在文字分類中的應用
- 知乎-用深度學習解決大規模文字分類的問題-綜述和實踐
- 簡書-利用tensorflow實現卷積神經網路做文字分類
- CSDN-利用word-embedding自動生成語義相近句子
- Github-Implementing a CNN for text classification in tensorflow
- 卷積神經網路在句子建模上的應用
- CSDN-自然語言處理中CNN模型幾種常見的Max-Pooling操作
- WILDML-understanding convolutional neural network for NLP
- 部落格園-文字深度表示模型--word2vec & doc2vec詞向量模型
- CSDN-用docsim/doc2vec/LSH比較兩個文件之間的相似度
- Deeplearning中文論壇-自然語言處理(三)之 word embedding
- CSDN-DeepNLP的學習,詞嵌入來龍去脈-深度學習
- CSDN-自己動手寫word2vec