
西電人工智慧大作業(Q-learing)
阿新 • • 發佈:2018-12-29
深度學習Q-learing演算法實現
1. 問題分析
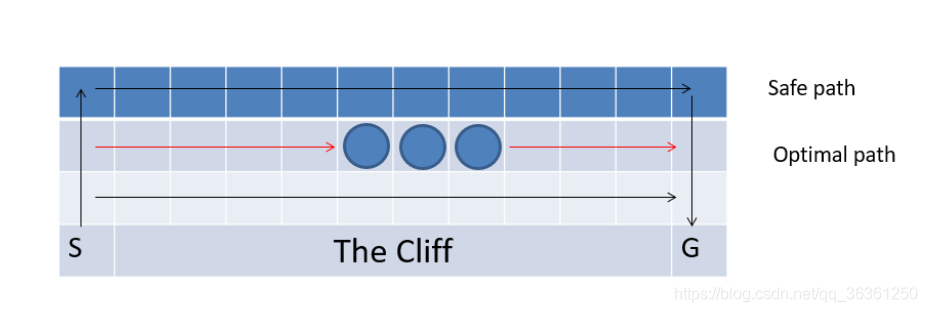
這是一個走懸崖的問題。強化學習中的主體從S出發走到G處一個回合結束,除了在邊緣以外都有上下左右四個行動,如果主體走入懸崖區域,回報為-100,走入中間三個圓圈中的任一個,會得到-1的獎勵,走入其他所有的位置,回報都為-5。
這是一個經典的Q-learing問題走懸崖的問題,也就是讓我們選擇的最大利益的路徑,可以將圖片轉化為reward矩陣
[[ -5. -5. -5. -5. -5. -5. -5. -5. -5. -5. -5. -5.]
[ 我們的目標就是讓agent從s(3,0)到達g(3,11)尋找之間利益最大化的路徑,學習最優的策略。
2. Q—learing理論分析
在Q-learing演算法中有兩個特別重要的術語:狀態(state)
行為(action),在我們這個題目中,state對應的就是我們的agent在懸崖地圖中所處的位置,action也就是agent下一步的活動,我的設定是(0, 1 ,2,3,4)對應的為(原地不動,上,下,左,右),需要注意的事我們的next action是隨機的但是也是取決於目前的狀態(current state)。
我們的核心為Q-learing的轉移規則(transition rule),我們依靠這個規則去不斷地學習,並把agent學習的經驗都儲存在Q-stable,並不斷迭代去不斷地積累經驗,最後到達我們設定的目標,這樣一個不斷試錯,學習的過程,最後到達目標的過程為一個episode
其中 表示現在狀態的state和action, 表示下一個狀態的state和action,學習引數為 ,越接近1代表約考慮遠期結果。
在Q-table初始化時由於agent對於周圍的環境一無所知,所以初始化為零矩陣。
3. 演算法實現
參考以下虛擬碼:

具體程式如見附錄
程式的關鍵點:
- 核心程式碼即為虛擬碼,但是各種方法需要自己實現,在程式中有註釋可以參考
- 需要判斷agent在一個狀態下可以使用的行動,這一點我用
valid_action(self, current_state)實現
**發現的問題:**題目中的目標點為G 的目標值也是為-1,但是程式會走到這個一步但是函式沒有收斂到此處,而且由於在獎勵點收益大,所以最後的agent會收斂到獎勵點處,在三個獎勵點處來回移動。所有我將最後的目標點G的值改為了100,函式可以收斂到此處。後來也看到文獻中的吸收目標
3. 結果展示
最後到Q-tabel矩陣由於太大放到附錄檢視,但是同時為了更加直觀的看到執行結果,
編寫了動態繪圖的程式 畫出了所有的路徑。如果需要檢視動態圖片請執行程式最終結果如下圖: