
赫拉(hera)分散式任務排程系統之架構,基本功能(一)
文章目錄
- 為資料平臺打造的任務排程系統
- 前言
- 架構
- 設計目標
- 支援任務的定時排程、依賴排程、手動排程、手動恢復
- 支援豐富的任務型別:shell,hive,python,spark-sql,java
- 視覺化的任務DAG圖展示,任務的執行嚴格按照任務的依賴關係執行& 某個任務的上、下游執行狀況檢視,通過任務依賴圖可以清楚的判斷當前任務為何還未執行,刪除該任務會影響那些任務。
- 支援上傳檔案到hdfs,支援使用hdfs檔案資源
- 支援日誌的實時滾動
- 支援任務失敗自動恢復
- 實現叢集HA,機器宕機環境實現機器斷線重連與心跳恢復與hera叢集HA,節點單點故障環境下任務自動恢復,master斷開,work搶佔master
- 支援master/work 負載,記憶體,程序,cpu資訊的視覺化檢視
- 支援正在等待執行的任務,每個work上正在執行的任務資訊的視覺化檢視
- 支援實時執行的任務,失敗任務,成功任務,任務耗時top10的視覺化檢視 & 支援歷史執行任務資訊的折線圖檢視 具體到某天的總執行次數,總失敗次數,總成功次數,總任務數,總失敗任務數,總成功任務數
- 支援關注自己的任務,自動排程執行失敗時會向負責人傳送郵件
- 組下任務總覽、組下任務失敗、組下任務正在執行
- 關於hera開源
為資料平臺打造的任務排程系統
前言
在大資料平臺,隨著業務發展,每天承載著成千上萬的ETL任務排程,這些任務集中在hive,shell指令碼排程。怎麼樣讓大量的ETL任務準確的完成排程而不出現問題,甚至在任務排程執行中出現錯誤的情況下,任務能夠完成自我恢復甚至執行錯誤告警與完整的日誌查詢。hera任務排程系統就是在這種背景下衍生的一款分散式排程系統。隨著hera叢集動態擴充套件,可以承載成千上萬的任務排程。它是一款原生的分散式任務排程,可以快速的新增部署wokrer節點,動態擴充套件叢集規模。支援shell,hive,spark
python等伺服器端指令碼排程。
hera分散式任務排程系統是根據前阿里開源排程系統(
zeus)進行的二次開發,其中zeus大概在2014年開源,開源後卻並未進行維護。我公司(二維火)2015年引進了zeus任務排程系統,一直使用至今年11月份,在我們部門乃至整個公司發揮著不可替代的作用。在我使用zeus的這一年多,不得不承認它的強大,只要叢集規模於配置適度,他可以承擔數萬乃至十萬甚至更高的數量級的任務排程。但是由於zeus程式碼是未維護的,前端更是使用GWT技術,難於在zeus上面進行維護。我與另外一個小夥伴(花名:凌霄,現在阿里淘寶部門)於今年三月份開始重寫zeus,改名赫拉(hera)
架構
hera系統只是負責排程以及輔助的系統,具體的計算還是要落在hadoop、hive、yarn、spark等叢集中去。所以此時又一個硬性要求,如果要執行hadoop,hive,spark等任務,我們的hera系統的worker一定要部署在這些叢集某些機器之上。如果僅僅是shell,那麼也至少需要linux系統。對於windows系統,可以把自己作為master進行除錯。
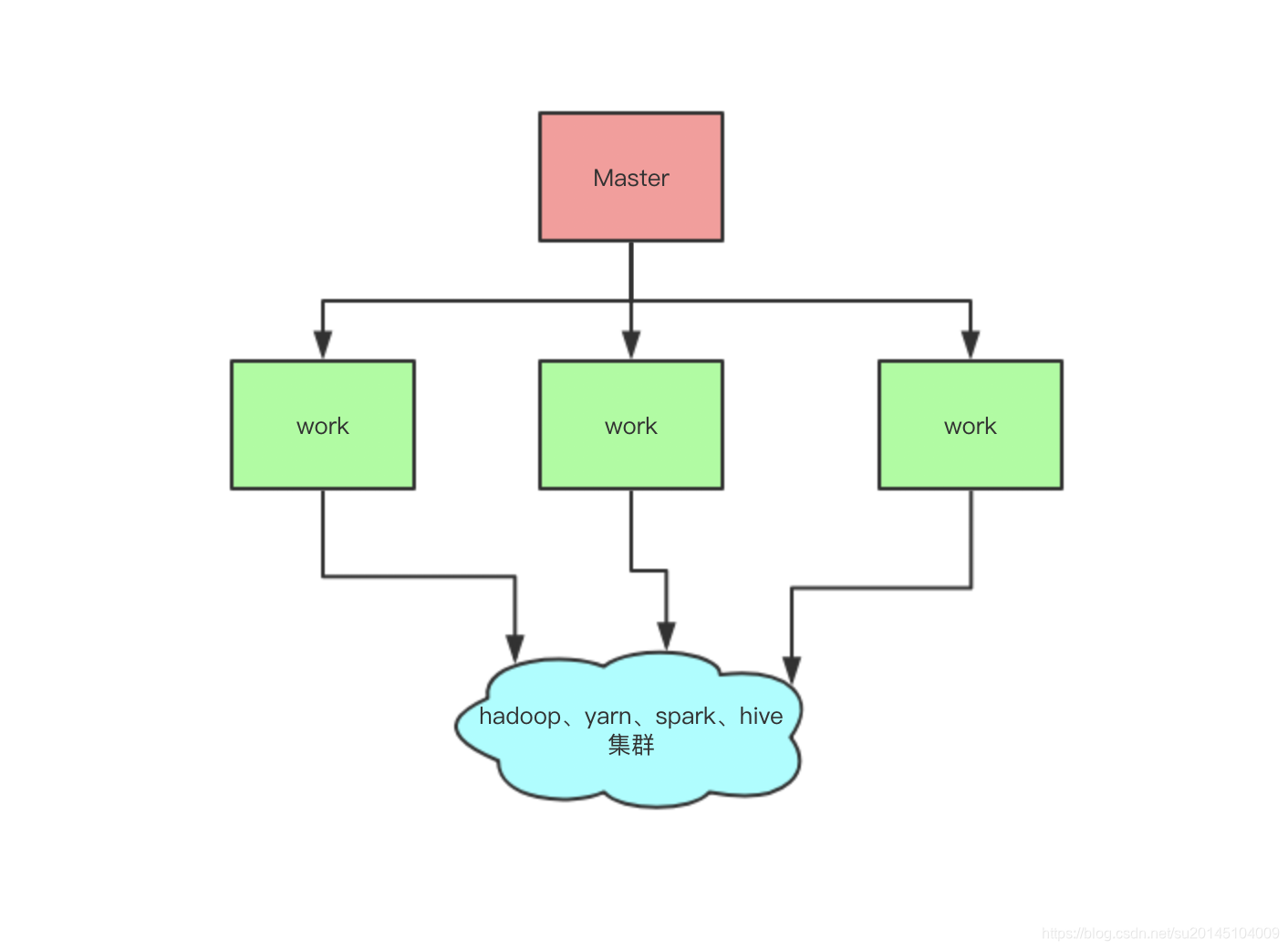
hera系統本身嚴格的遵從主從架構模式,由主節點充當著任務排程觸發與任務分發器,從節點作為具體的任務執行器.架構圖如下:
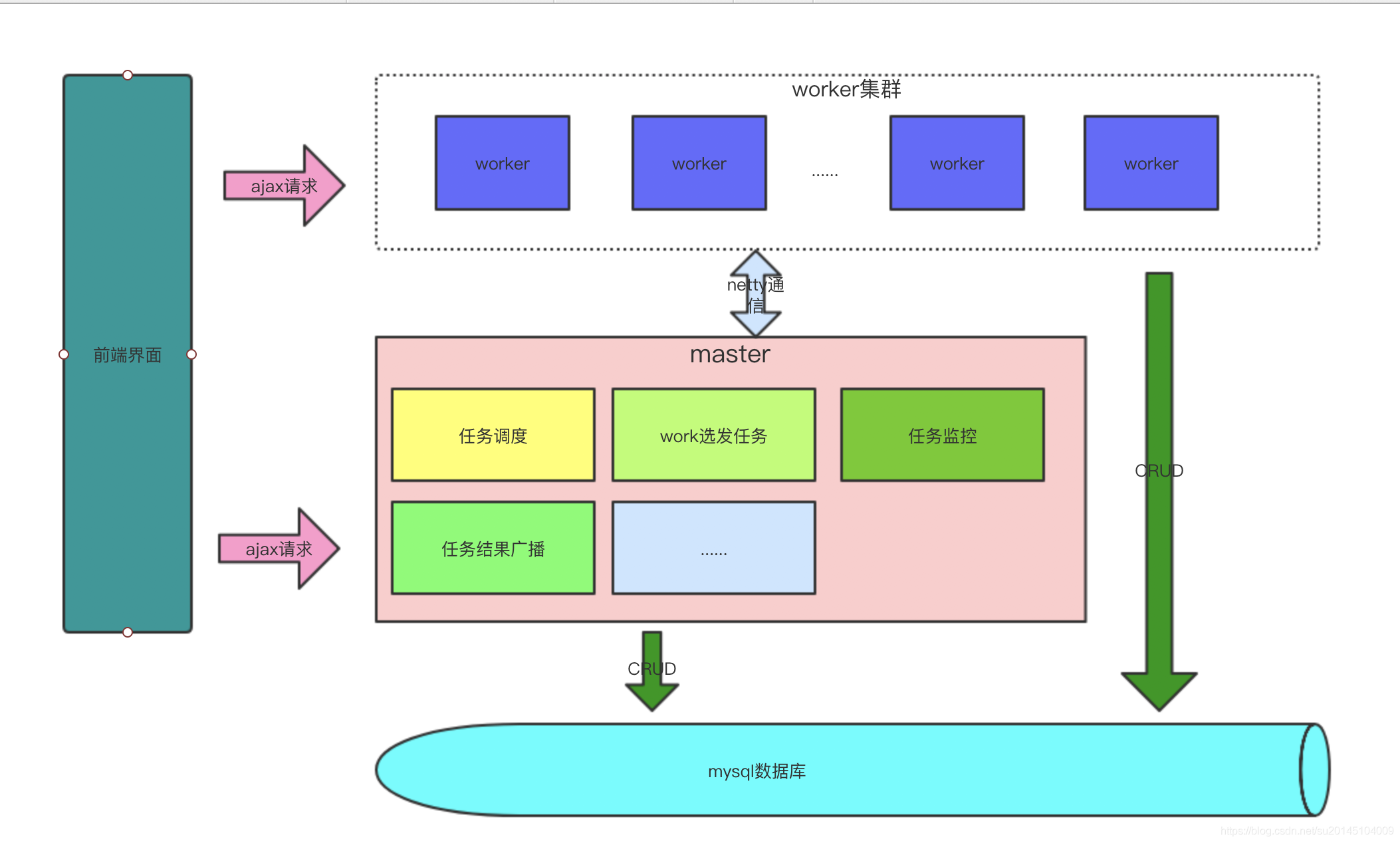
設計目標
hera分散式任務排程系統的設計目標首先是要完成zeus大部分核心功能,並能夠根據自己公司的需求進行擴充套件。大致目標有以下幾點
- 支援任務的定時排程、依賴排程、手動排程、手動恢復
- 支援豐富的任務型別:
shell,hive,python,spark-sql,java - 視覺化的任務
DAG圖展示,任務的執行嚴格按照任務的依賴關係執行 - 某個任務的上、下游執行狀況檢視,通過任務依賴圖可以清楚的判斷當前任務為何還未執行,刪除該任務會影響那些任務。
- 支援上傳檔案到
hdfs,支援使用hdfs檔案資源 - 支援日誌的實時滾動
- 支援任務失敗自動恢復
- 實現叢集HA,機器宕機環境實現機器斷線重連與心跳恢復與
hera叢集HA,節點單點故障環境下任務自動恢復,master斷開,worker搶佔master - 支援對
master/work負載,記憶體,程序,cpu資訊的視覺化檢視 - 支援正在等待執行的任務,每個
worker上正在執行的任務資訊的視覺化檢視 - 支援實時執行的任務,失敗任務,成功任務,任務耗時
top10的視覺化檢視 - 支援歷史執行任務資訊的折線圖檢視 具體到某天的總執行次數,總失敗次數,總成功次數,總任務數,總失敗任務數,總成功任務數
- 支援關注自己的任務,自動排程執行失敗時會向負責人傳送郵件
- 對外提供
API,開放系統任務排程觸發介面,便於對接其它需要使用hera的系統 - 組下任務總覽、組下任務失敗、組下任務正在執行
- 支援
map-reduce任務和yarn任務的實時取消。 - (還有更多,等待大家探索)
支援任務的定時排程、依賴排程、手動排程、手動恢復
- 定時排程
主要是根據cron表示式來解析該任務的執行時間,在達到觸發時間時將該任務加入任務佇列
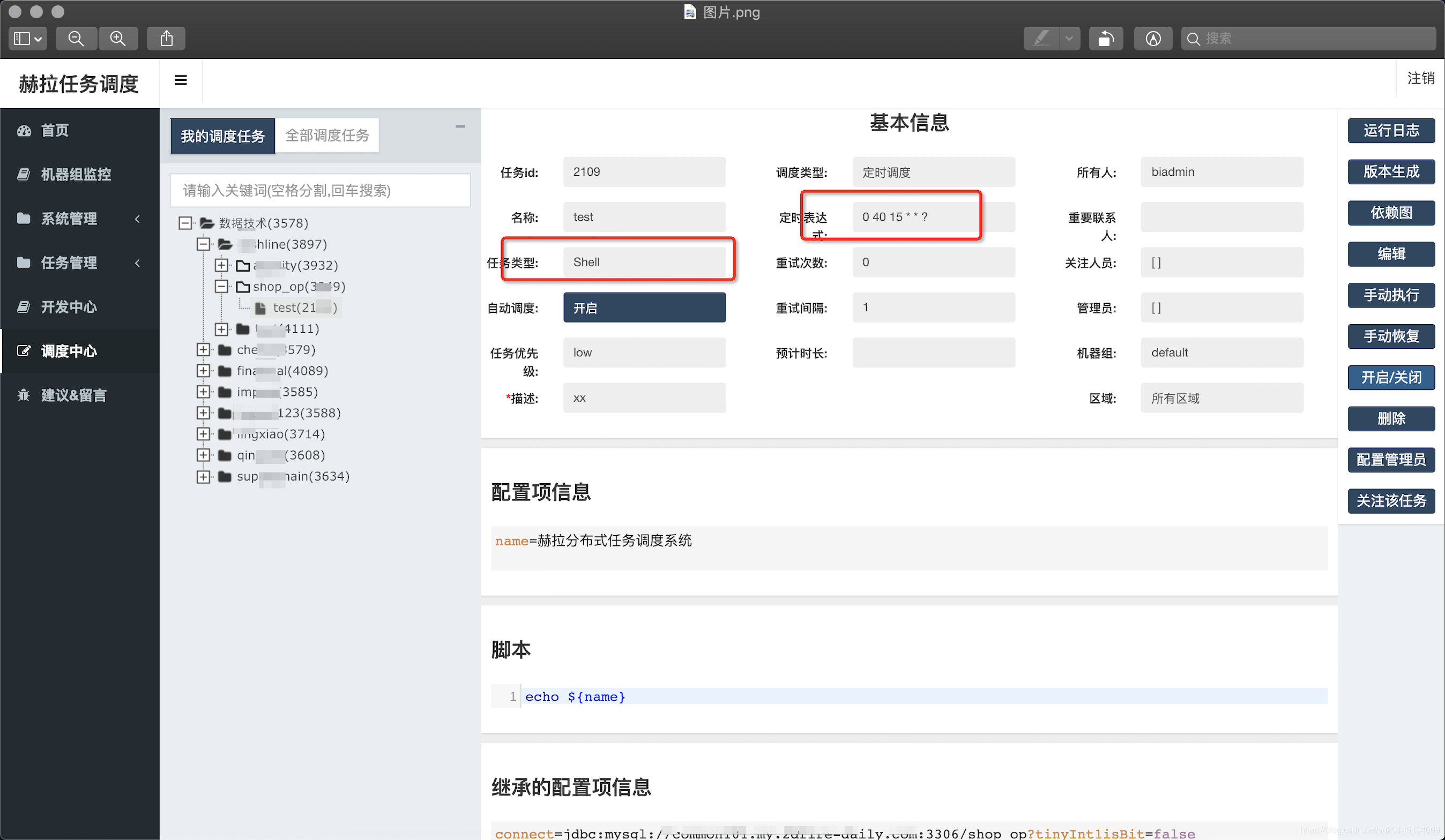
為了進行測試我新建了一個shell任務 在15:40執行 ,在配置項裡輸入我們自己的配置,在指令碼中使用${}進行替換,其中的繼承配置項,即任務繼承的所在組的配置資訊,如果有重複以最近的為準
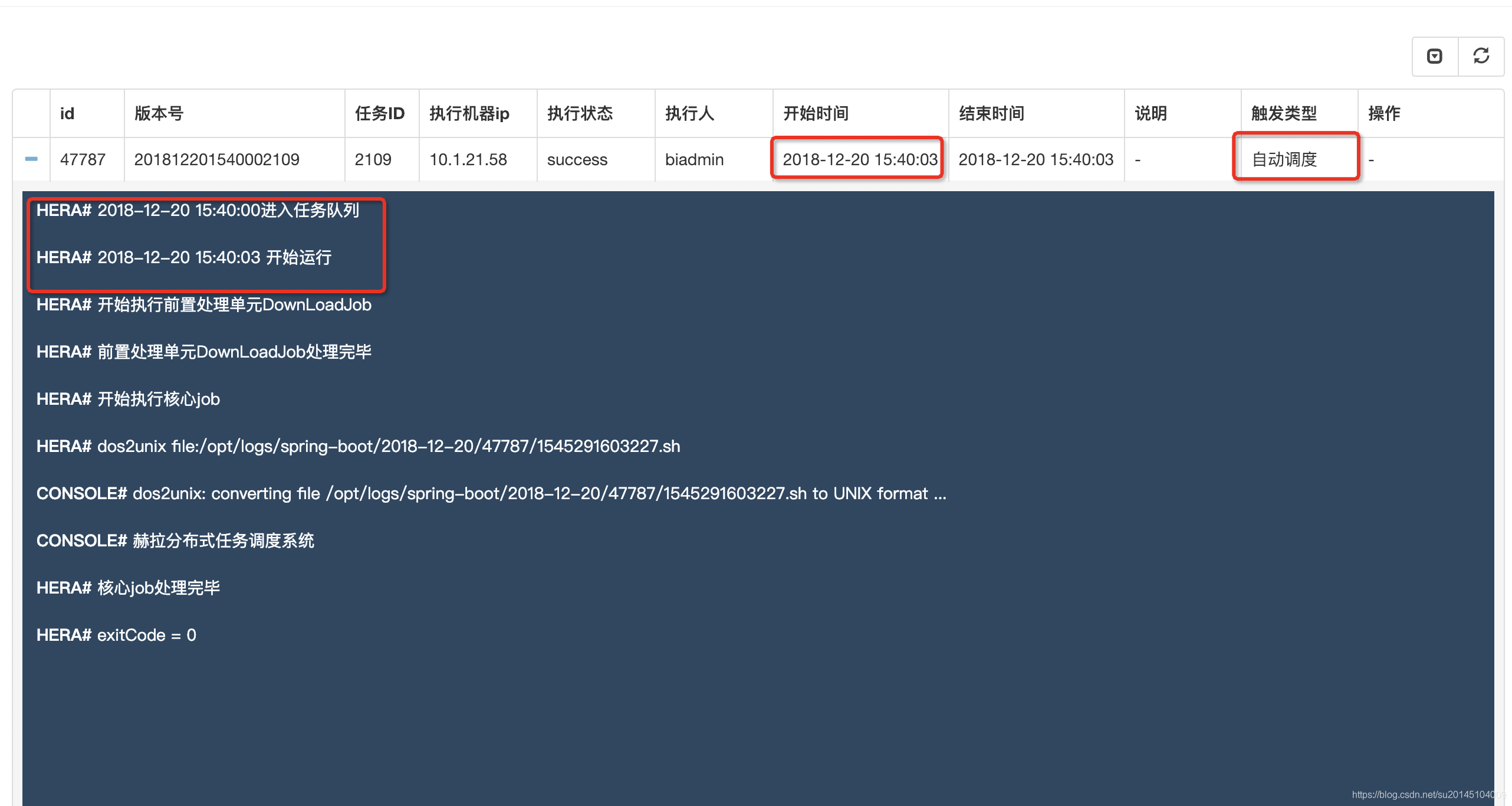
當任務達到時間開始執行,輸出我們想要的結果:赫然分散式任務排程系統
- 依賴排程
我們的任務大部分都有依賴關係,只有在上一個任務計算出結果後才能進行下一步的執行。我們的依賴任務會在所有的依賴任務都執行完成之後才會被觸發加入任務佇列
貼一個已有的任務執行資訊
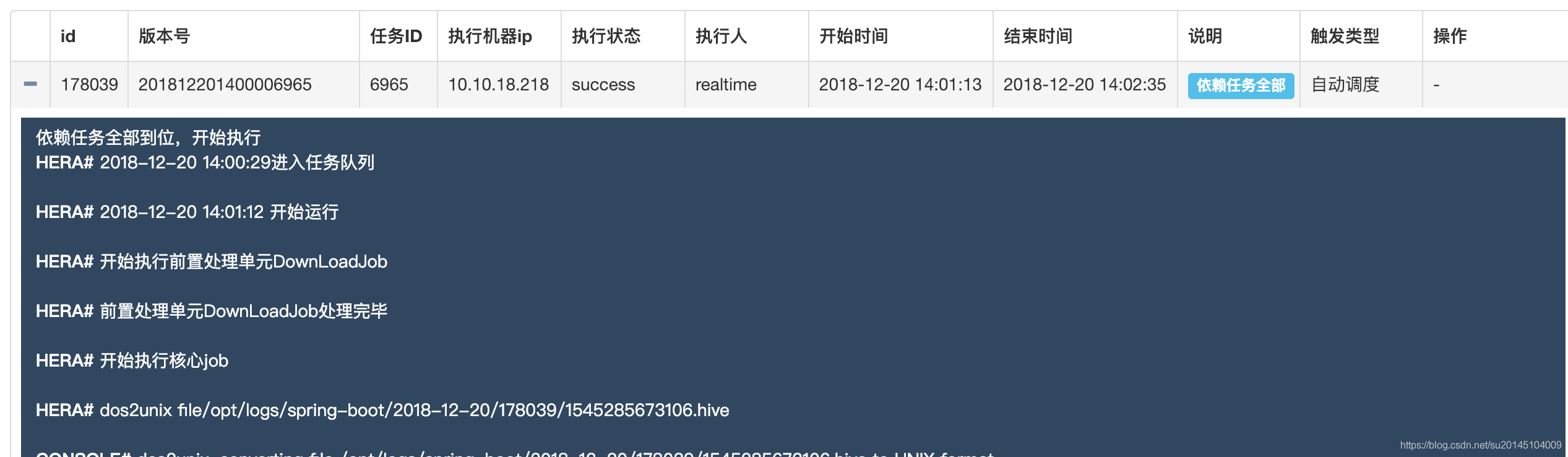
- 手動排程
手動排程即為手動執行的任務,手動執行後自動加入任務佇列,請注意,手動任務執行成功後不會通知下游任務(即:依賴於該任務的任務)該任務已經執行完成
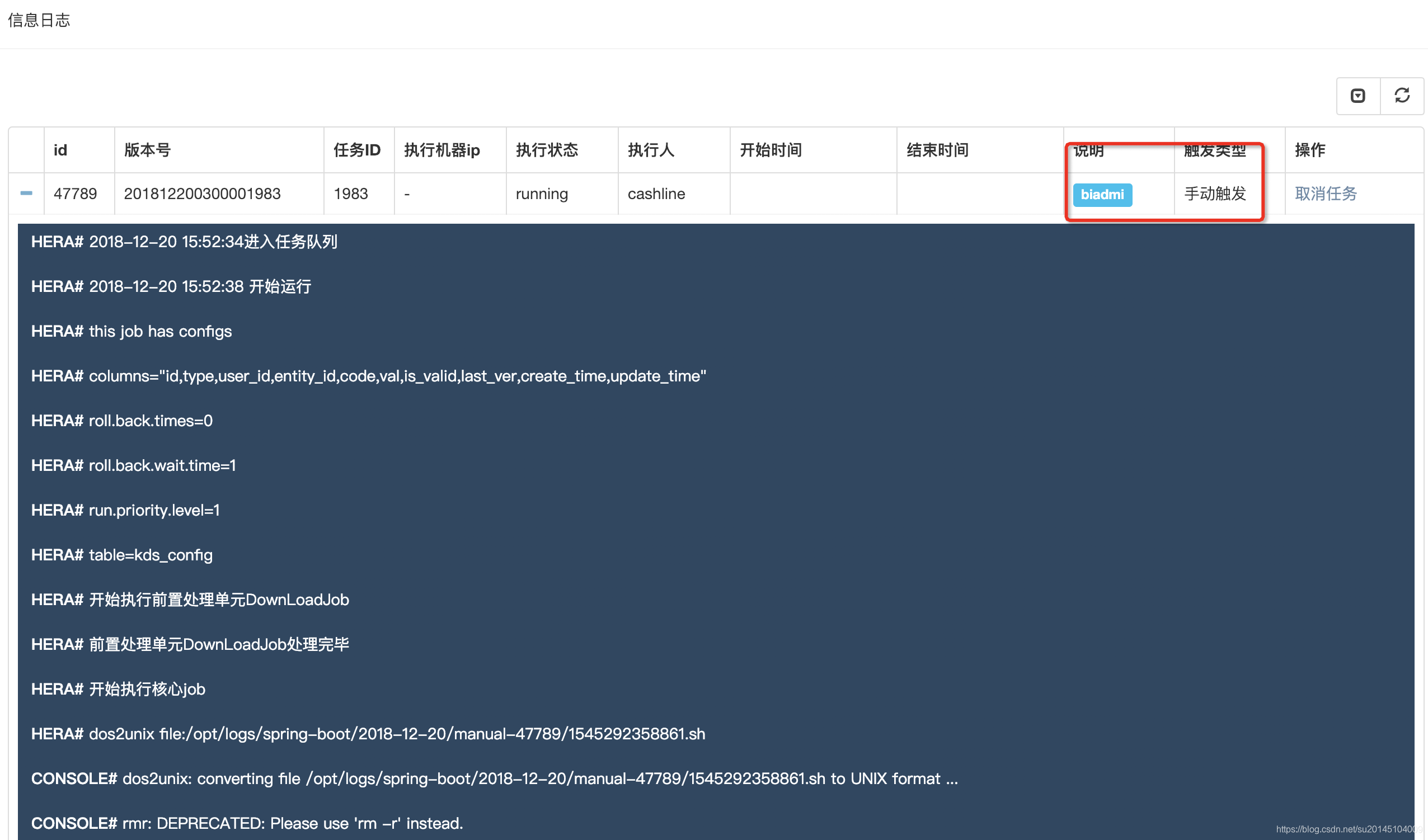
- 手動恢復
手動恢復類似於手動排程,於手動排程的區別為此時如果該任務執行成功,會通知下游任務該任務已經執行完成
支援豐富的任務型別:shell,hive,python,spark-sql,java
hera分散式任務排程系統依賴於jdk原生的ProcessBuilder 通過該工具向work/master以shell命令的方式執行任務。
比如python任務
我們可以首先寫一個python指令碼hello.py(這裡隨便貼個圖片),然後把該指令碼上傳到hdfs
在執行的時候我們可以通過
download[hdfs:///hera/hello.py hello.py];
python hello.py;
來執行該指令碼
這樣一個完整的pyhton指令碼就能通過方式實現shell方式呼叫執行,通過hera內部實現的job執行封裝,指令碼的文法解析,實現pyhton任務執行。實際上,通過這種方式甚至可以實現java,scala,hive-udf等伺服器端語言的指令碼任務執行。
- hive spark-sql 指令碼的執行
對於hive指令碼和spark-sql指令碼 都是通過-f 命令來執行一個檔案
視覺化的任務DAG圖展示,任務的執行嚴格按照任務的依賴關係執行& 某個任務的上、下游執行狀況檢視,通過任務依賴圖可以清楚的判斷當前任務為何還未執行,刪除該任務會影響那些任務。
當任務數量過多,依賴錯綜複雜時就需要一個DAG圖來檢視任務之間的關係。
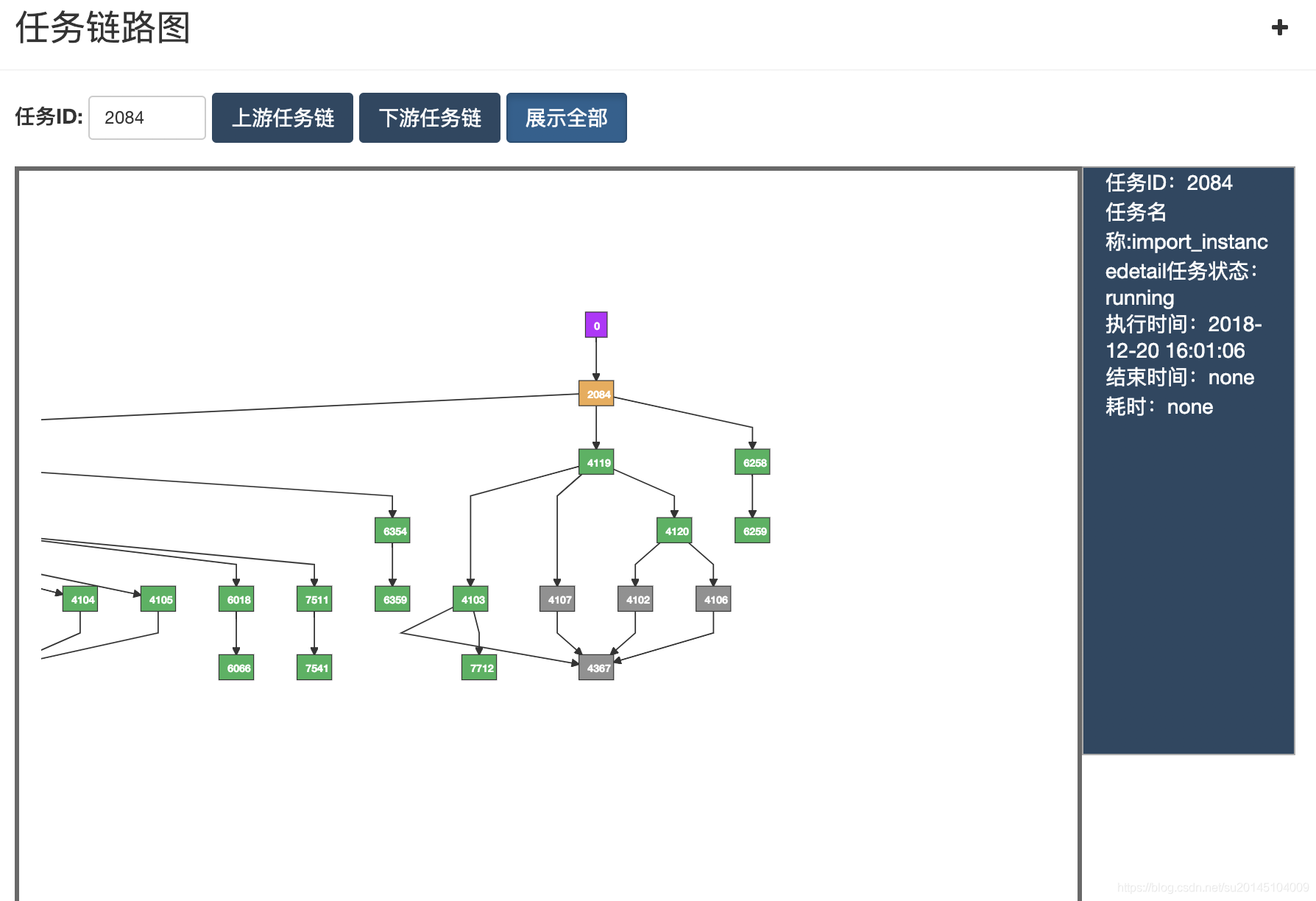
黃色表示正在執行,灰色表示關閉的任務,紅色表示失敗的任務,綠色表示執行成功的任務。右側會顯示該任務的詳細資訊。
當然在這裡既支援全部檢視也支援點選檢視,當點選某個任務時會展示出依賴這個任務的所有任務。
支援上傳檔案到hdfs,支援使用hdfs檔案資源
這個在上面 的 支援豐富的任務型別:shell,hive,python,spark-sql,java 已經說過,不再贅述。
支援日誌的實時滾動
當執行任務時,可以通過檢視日誌的方式檢視實時滾動的日誌
支援任務失敗自動恢復
當然,某些情況下任務可能會失敗,比如網路閃斷,可能下一秒就好了。建議對於非常重要的任務一定要開啟任務失敗重試,設定自定義的重試次數於重試時間間隔,設定後master會根據配置進行失敗任務重試排程。
比如設定重試次數3,重試間隔10分鐘
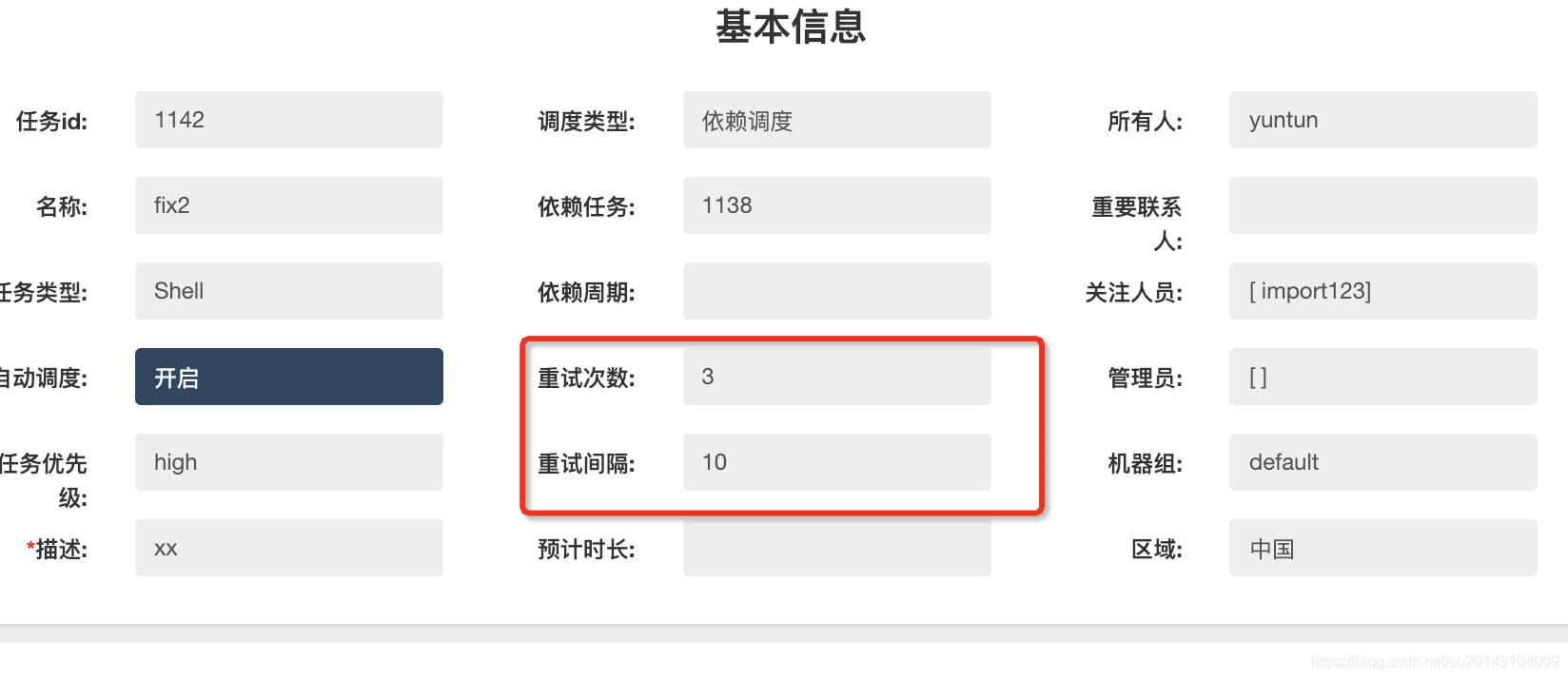
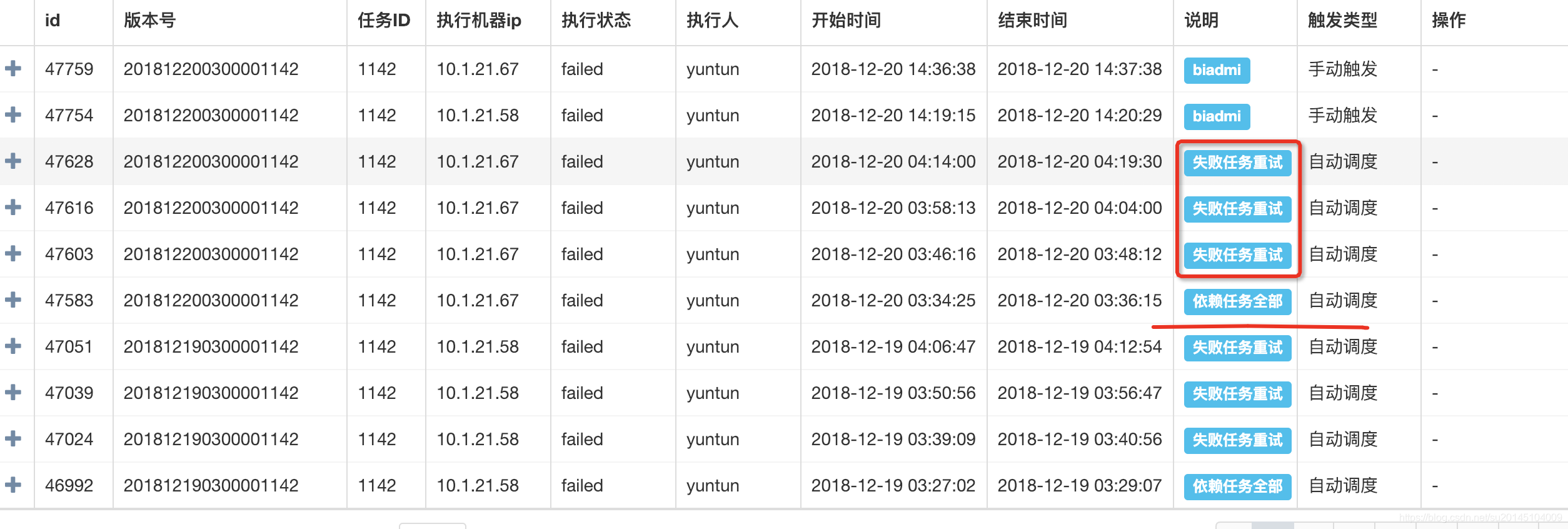
任務在執行失敗後進行三次重試,可以看上次失敗的結束時間與開始時間間隔為10分鐘。
實現叢集HA,機器宕機環境實現機器斷線重連與心跳恢復與hera叢集HA,節點單點故障環境下任務自動恢復,master斷開,work搶佔master
構建分散式系統,無法避免的就是需要做叢集容災。在出現伺服器宕機與網路閃斷的情況下要做到叢集實現自動通訊恢復,在此基礎上,要做到實現任務在通訊恢復後任務重新恢復執行等。
這個就無法展示了,等待大家以後去體驗。
支援master/work 負載,記憶體,程序,cpu資訊的視覺化檢視
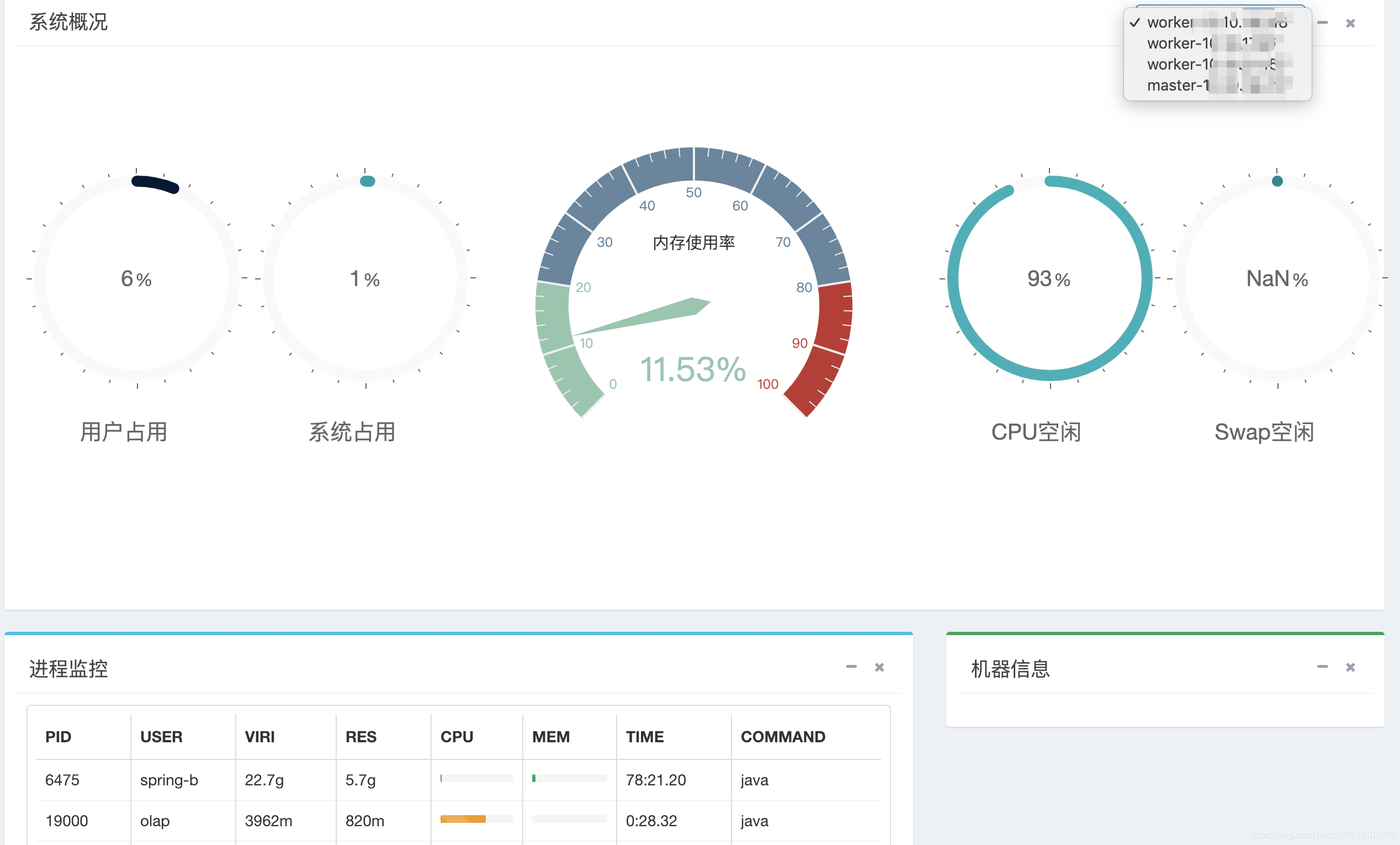
這裡可以看機器的使用者cpu佔用百分比,系統cpu佔用百分比,cpu空閒,進行資訊 等等。。
支援正在等待執行的任務,每個work上正在執行的任務資訊的視覺化檢視
首先上圖
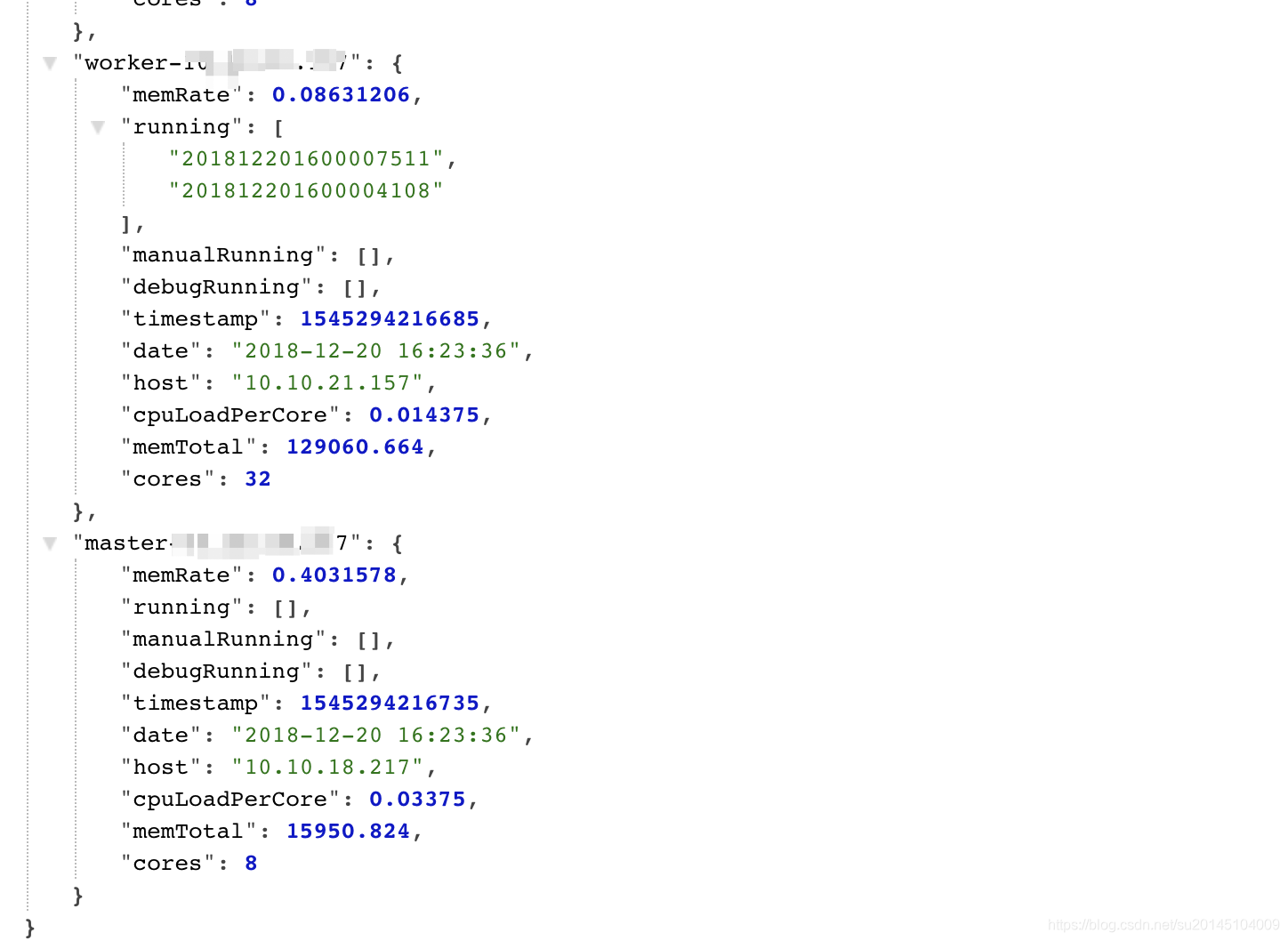
哈哈,有點簡陋,只是提供了api介面,無奈沒前端,現在就我一個人在開發。等吧。
裡面的資訊有機器記憶體使用百分比,平均每個核的負載,機器總記憶體,統計的時間。其中有三個佇列,分別是running,manualRunning,debugRunning 在master開頭的機器上表示等待執行的任務,在work開頭的機器上表示正在執行的任務。分別對應自動排程&依賴任務 、手動執行任務、開發任務(另外一個開發介面)
支援實時執行的任務,失敗任務,成功任務,任務耗時top10的視覺化檢視 & 支援歷史執行任務資訊的折線圖檢視 具體到某天的總執行次數,總失敗次數,總成功次數,總任務數,總失敗任務數,總成功任務數
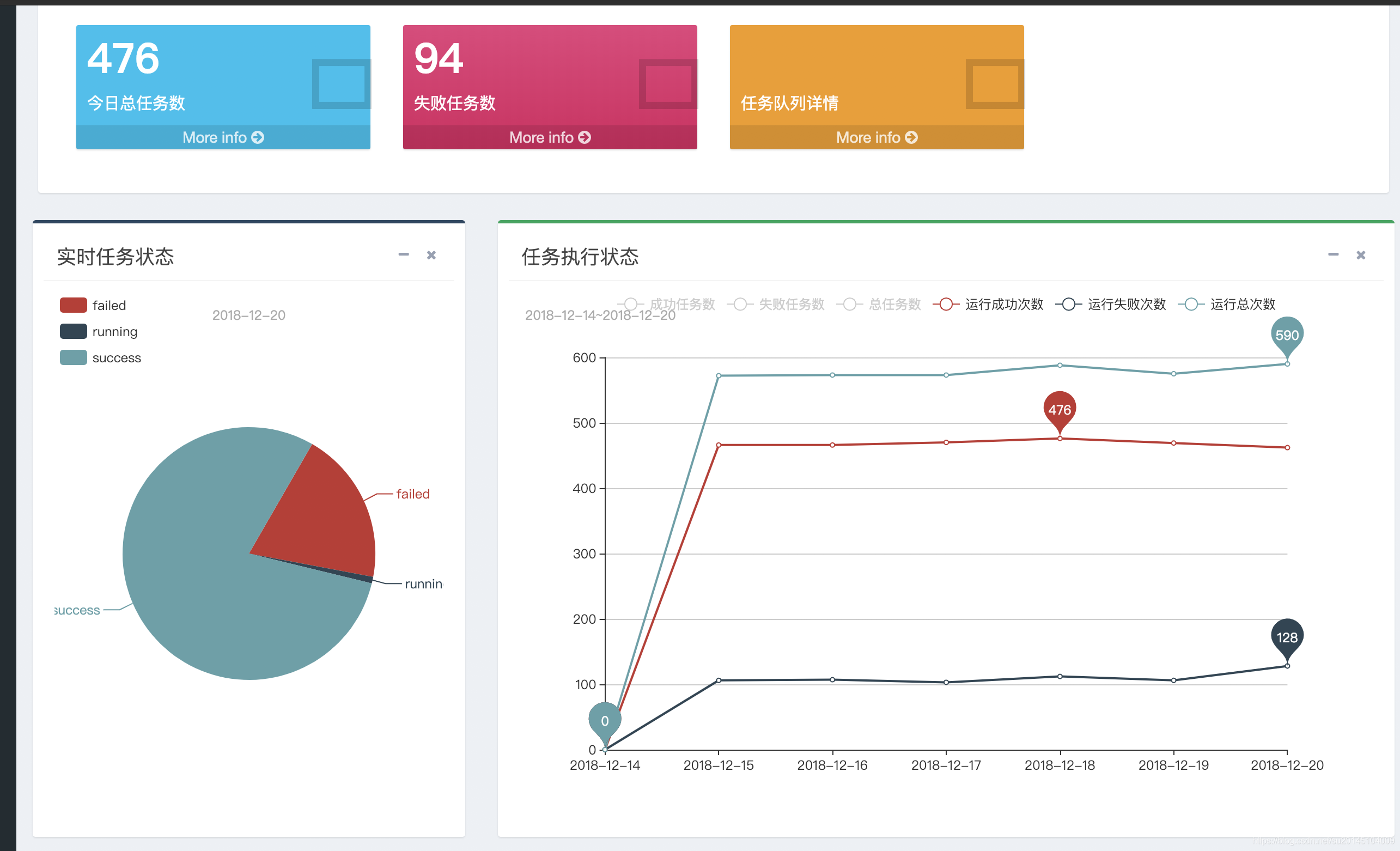
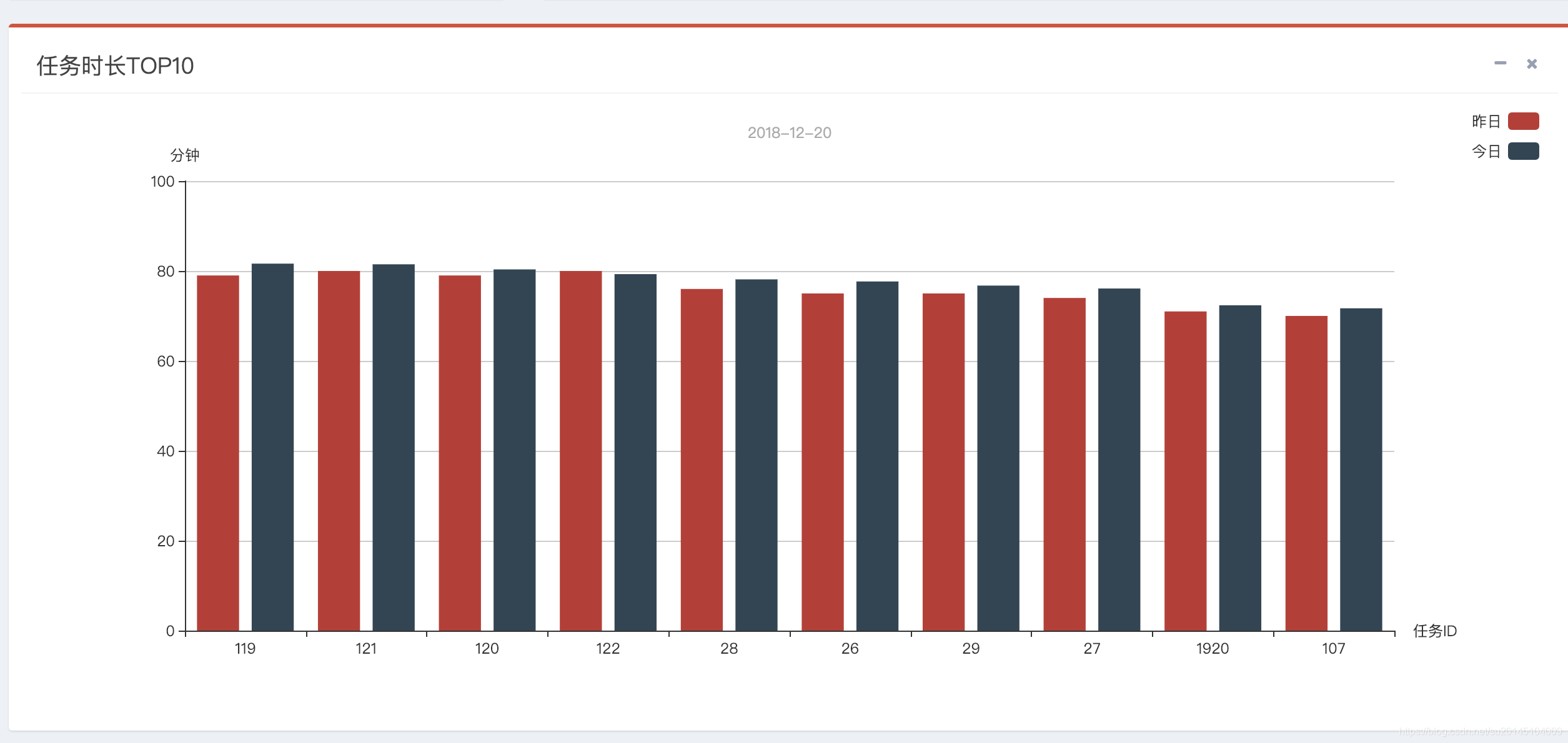
其中餅圖可以通過點選進去檢視具體的詳細任務資訊

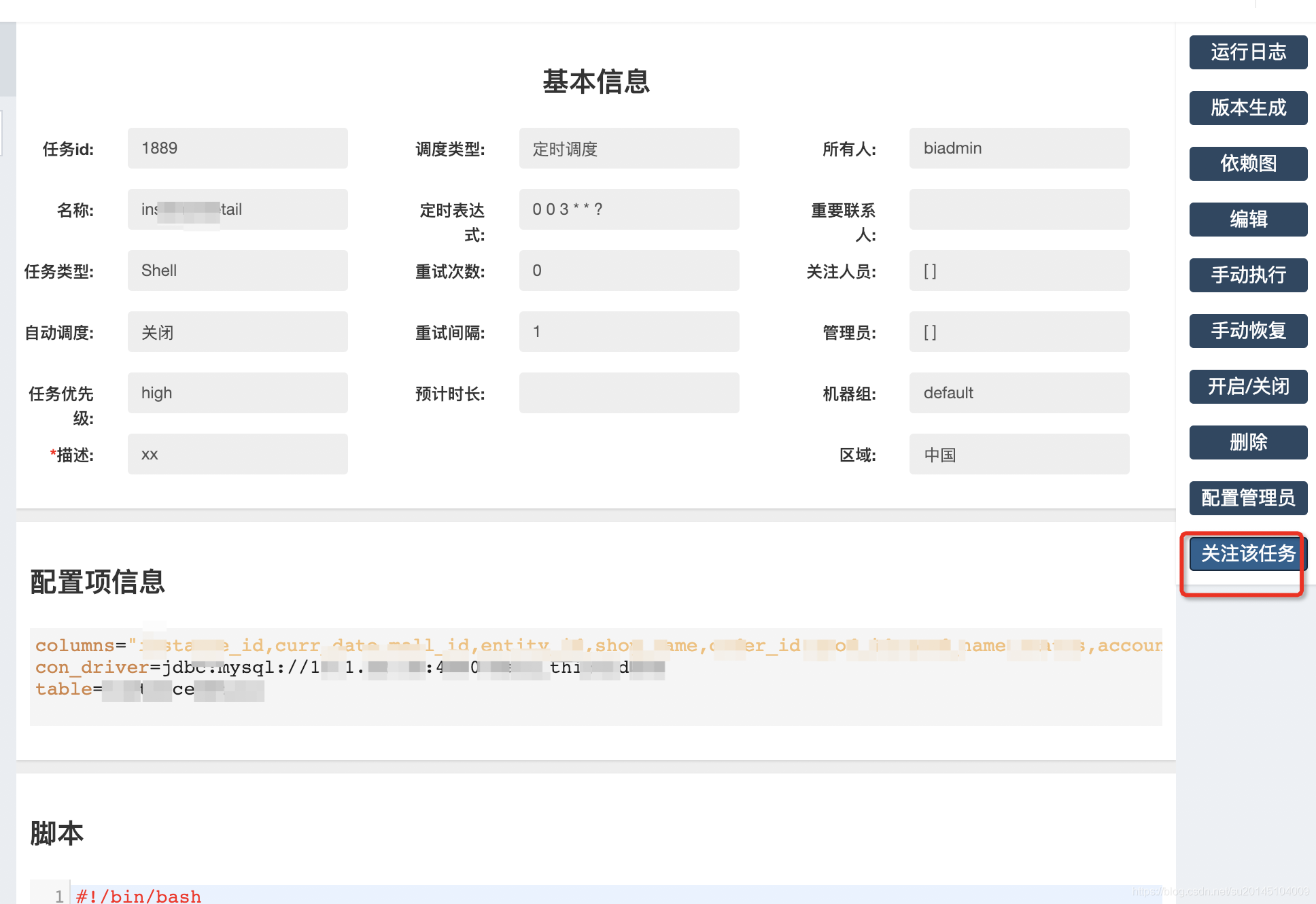
支援關注自己的任務,自動排程執行失敗時會向負責人傳送郵件
當我們需要關注某些任務時可以通過關注任務來接收任務失敗的資訊
組下任務總覽、組下任務失敗、組下任務正在執行
雖然在首頁我們看到失敗的任務,但是有時候我們並不想關注別人的任務。我們就可以通過建立屬於我們自己的組,然後在組下建立任務。這時候就可以通過組下任務預覽來檢視任務狀態
比如點了任務總覽
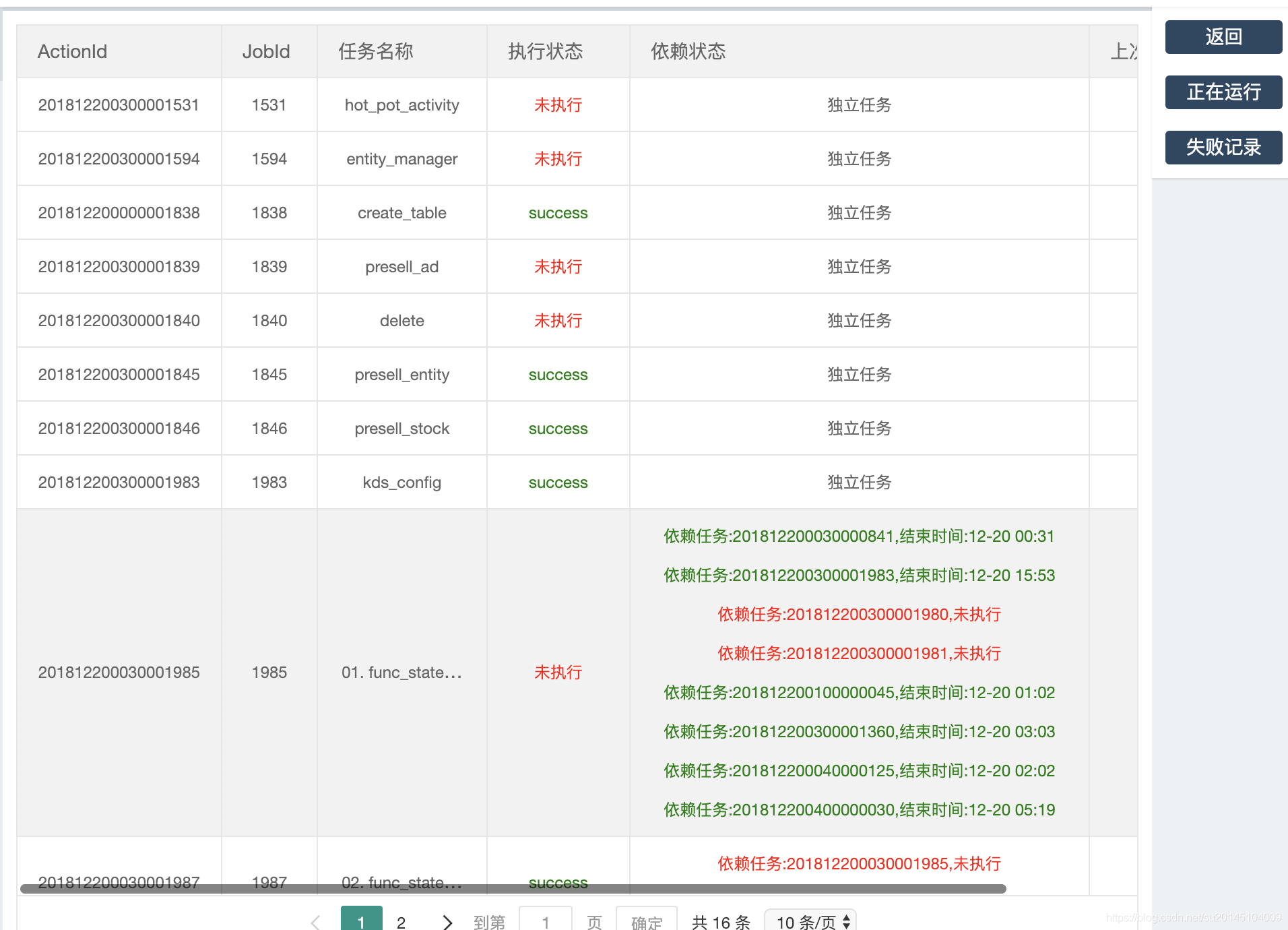
此時可以看到任務的所有資訊,無論是執行,未執行,執行失敗,執行成功還是執行中,如果任務未執行還會提示某些依賴任務未執行,如果依賴任務執行,
會展示任務的執行時間等等。右側還可以再對內容進行篩選,比如檢視失敗,執行的任務。
其它
其實我們也做了許多其它功能,刪除任務判斷是否有任務依賴,關閉任務是否有任務依賴等。之外我們也做了hive sql血緣解析,欄位解析,任務執行日誌解析等等,由於在其它專案上面,後面會考慮繼承到hera裡面。
關於hera開源
準備在12月開源吧。最近把專案整理整理。
附上凌霄的部落格地址:https://blog.csdn.net/pengjx2014/article/details/81276874
以上所有資訊均為線下測試資訊