
Why, How and When to Scale your Features
Why, How and When to Scale your Features
Feature scaling can vary your results a lot while using certain algorithms and have a minimal or no effect in others. To understand this, let’s look why features need to be scaled, varieties of scaling methods and when we should scale our features.
Why Scaling
Most of the times, your dataset will contain features highly varying in magnitudes, units and range. But since, most of the machine learning algorithms use Eucledian distance between two data points in their computations, this is a problem.
If left alone, these algorithms only take in the magnitude of features neglecting the units. The results would vary greatly between different units, 5kg and 5000gms. The features with high magnitudes will weigh in a lot more in the distance calculations than features with low magnitudes.


To supress this effect, we need to bring all features to the same level of magnitudes. This can be acheived by scaling.
How to Scale Features
There are four common methods to perform Feature Scaling.
- Standardisation:
Standardisation replaces the values by their Z scores.
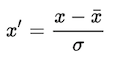
This redistributes the features with their mean μ = 0
sklearn.preprocessing.scale helps us implementing standardisation in python.2. Mean Normalisation: