
Elastic-Job原理--任務分片策略(三)
阿新 • • 發佈:2018-12-29
上一篇部落格Elastic-Job原理--伺服器初始化、節點選舉與通知(二)介紹了Elastic-Job的啟動流程,這篇部落格我們瞭解學習一下Elastic-Job的任務分片策略,目前提供了三種任務分片策略,分片策略的實現最終是在註冊中心zk中在分片的instance中寫入例項資訊。
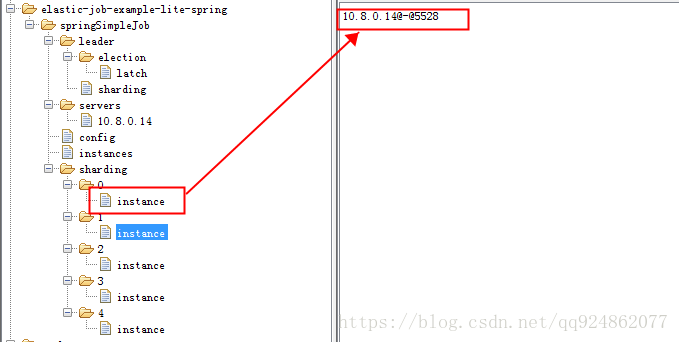
目前Elastic-Job提供分片介面JobShardingStrategy:
/** * 作業分片策略. * * @author zhangliang */ public interface JobShardingStrategy { /** * 作業分片. * * @param jobInstances 所有參與分片的單元列表 * @param jobName 作業名稱 * @param shardingTotalCount 分片總數 * @return 分片結果 */ Map<JobInstance, List<Integer>> sharding(List<JobInstance> jobInstances, String jobName, int shardingTotalCount); }
目前有如下實現類:
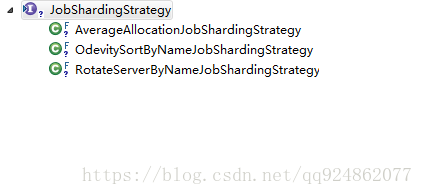
(1)AverageAllocationJobShardingStrategy:基於平均分配演算法的分片策略.
如果分片不能整除, 則不能整除的多餘分片將依次追加到序號小的伺服器.
如:
1. 如果有3臺伺服器, 分成9片, 則每臺伺服器分到的分片是: 1=[0,1,2], 2=[3,4,5], 3=[6,7,8].
2. 如果有3臺伺服器, 分成8片, 則每臺伺服器分到的分片是: 1=[0,1,6], 2=[2,3,7], 3=[4,5].
3. 如果有3臺伺服器, 分成10片, 則每臺伺服器分到的分片是: 1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8].
/** * 基於平均分配演算法的分片策略. * * <p> * 如果分片不能整除, 則不能整除的多餘分片將依次追加到序號小的伺服器. * 如: * 1. 如果有3臺伺服器, 分成9片, 則每臺伺服器分到的分片是: 1=[0,1,2], 2=[3,4,5], 3=[6,7,8]. * 2. 如果有3臺伺服器, 分成8片, 則每臺伺服器分到的分片是: 1=[0,1,6], 2=[2,3,7], 3=[4,5]. * 3. 如果有3臺伺服器, 分成10片, 則每臺伺服器分到的分片是: 1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8]. * </p> * * @author zhangliang */ public final class AverageAllocationJobShardingStrategy implements JobShardingStrategy { @Override public Map<JobInstance, List<Integer>> sharding(final List<JobInstance> jobInstances, final String jobName, final int shardingTotalCount) { if (jobInstances.isEmpty()) { return Collections.emptyMap(); } Map<JobInstance, List<Integer>> result = shardingAliquot(jobInstances, shardingTotalCount); addAliquant(jobInstances, shardingTotalCount, result); return result; } //根據整除規則,將整除後的資料進行分配 private Map<JobInstance, List<Integer>> shardingAliquot(final List<JobInstance> shardingUnits, final int shardingTotalCount) { Map<JobInstance, List<Integer>> result = new LinkedHashMap<>(shardingTotalCount, 1); int itemCountPerSharding = shardingTotalCount / shardingUnits.size(); int count = 0; for (JobInstance each : shardingUnits) { List<Integer> shardingItems = new ArrayList<>(itemCountPerSharding + 1); for (int i = count * itemCountPerSharding; i < (count + 1) * itemCountPerSharding; i++) { shardingItems.add(i); } result.put(each, shardingItems); count++; } return result; } //無法整除分片的資料,依次追加到例項中 private void addAliquant(final List<JobInstance> shardingUnits, final int shardingTotalCount, final Map<JobInstance, List<Integer>> shardingResults) { int aliquant = shardingTotalCount % shardingUnits.size(); int count = 0; for (Map.Entry<JobInstance, List<Integer>> entry : shardingResults.entrySet()) { if (count < aliquant) { entry.getValue().add(shardingTotalCount / shardingUnits.size() * shardingUnits.size() + count); } count++; } } }
(2)OdevitySortByNameJobShardingStrategy:根據作業名的雜湊值奇偶數決定IP升降序演算法的分片策略.
首先 作業名的雜湊值為奇數則IP升序. 作業名的雜湊值為偶數則IP降序.然後再呼叫AverageAllocationJobShardingStrategy的平均分片演算法進行分片。
/**
* 根據作業名的雜湊值奇偶數決定IP升降序演算法的分片策略.
*
* <p>
* 作業名的雜湊值為奇數則IP升序.
* 作業名的雜湊值為偶數則IP降序.
* 用於不同的作業平均分配負載至不同的伺服器.
* 如:
* 1. 如果有3臺伺服器, 分成2片, 作業名稱的雜湊值為奇數, 則每臺伺服器分到的分片是: 1=[0], 2=[1], 3=[].
* 2. 如果有3臺伺服器, 分成2片, 作業名稱的雜湊值為偶數, 則每臺伺服器分到的分片是: 3=[0], 2=[1], 1=[].
* </p>
*
* @author zhangliang
*/
public final class OdevitySortByNameJobShardingStrategy implements JobShardingStrategy {
private AverageAllocationJobShardingStrategy averageAllocationJobShardingStrategy = new AverageAllocationJobShardingStrategy();
@Override
public Map<JobInstance, List<Integer>> sharding(final List<JobInstance> jobInstances, final String jobName, final int shardingTotalCount) {
long jobNameHash = jobName.hashCode();
if (0 == jobNameHash % 2) {
Collections.reverse(jobInstances);
}
return averageAllocationJobShardingStrategy.sharding(jobInstances, jobName, shardingTotalCount);
}
}(3)RotateServerByNameJobShardingStrategy:根據作業名的雜湊值對伺服器列表進行輪轉的分片策略.
/**
* 根據作業名的雜湊值對伺服器列表進行輪轉的分片策略.
*
* @author weishubin
*/
public final class RotateServerByNameJobShardingStrategy implements JobShardingStrategy {
private AverageAllocationJobShardingStrategy averageAllocationJobShardingStrategy = new AverageAllocationJobShardingStrategy();
@Override
public Map<JobInstance, List<Integer>> sharding(final List<JobInstance> jobInstances, final String jobName, final int shardingTotalCount) {
return averageAllocationJobShardingStrategy.sharding(rotateServerList(jobInstances, jobName), jobName, shardingTotalCount);
}
private List<JobInstance> rotateServerList(final List<JobInstance> shardingUnits, final String jobName) {
int shardingUnitsSize = shardingUnits.size();
int offset = Math.abs(jobName.hashCode()) % shardingUnitsSize;
if (0 == offset) {
return shardingUnits;
}
List<JobInstance> result = new ArrayList<>(shardingUnitsSize);
for (int i = 0; i < shardingUnitsSize; i++) {
int index = (i + offset) % shardingUnitsSize;
result.add(shardingUnits.get(index));
}
return result;
}
}總結:總體上使用的還是平均分片演算法,不過是將例項進行了不同的排序操作。