
Chapter 9 : Natural Language Processing.
Chapter 9 : Natural Language Processing.
so far we have talked about machine learning and deep learning algorithms which can be used in any field. One of the main fields where ML/DL algorithms are used is Natural language processing(NLP) so from now onwards lets talk about the NLP.


NLP is a big area, probably bigger than Machine learning cause the concept of language is really intense so we are not gonna focus on it completely but we focus on the small area where it meets machine learning and deep learning.

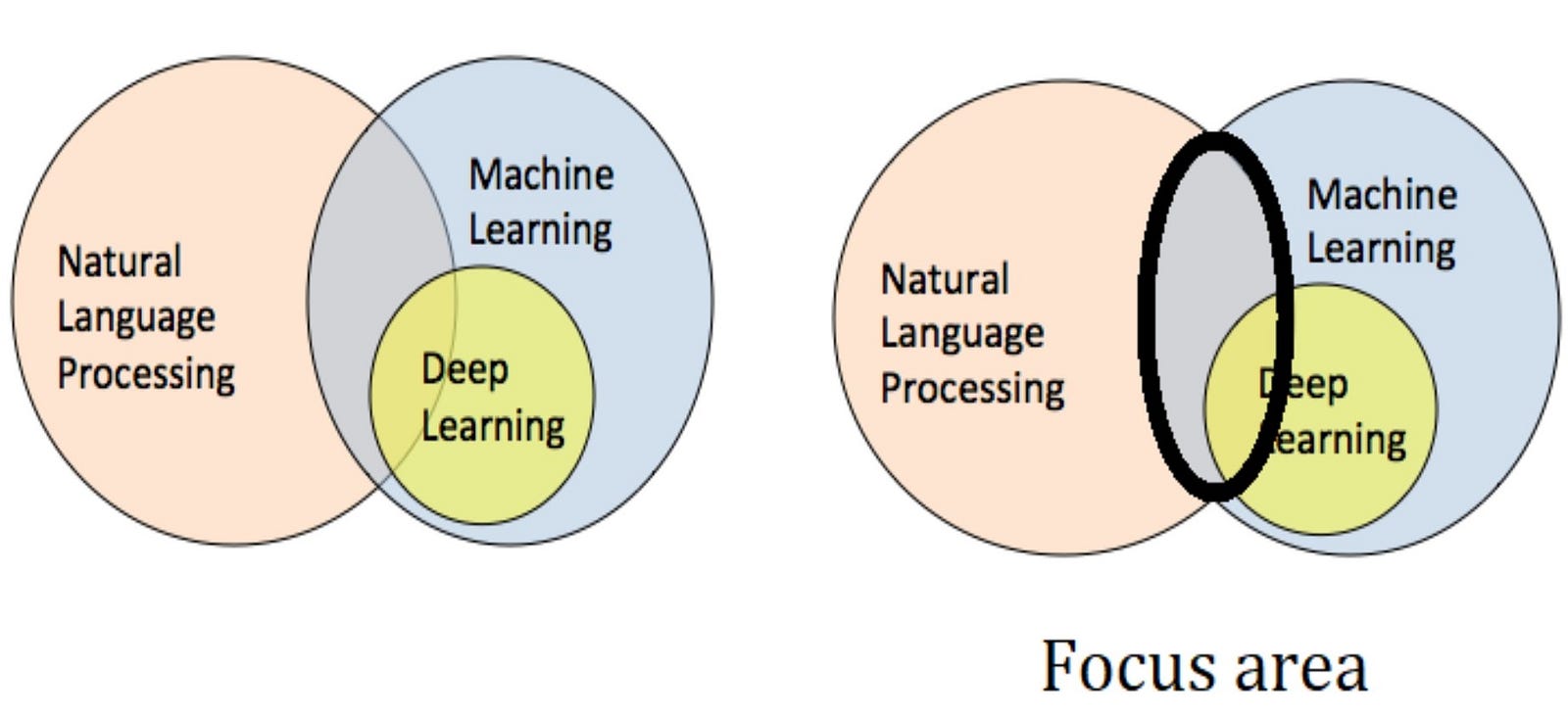
let’s understand the natural language processing in our space.
Natural language processing
The main goal here is , we wanna make the computer understand the language as we do and we wanna make the computer respond as we do.
We can break that into 2 sections
- Natural language understanding:
The system should be able to understand the language(parts of speech, context , syntax , semantics, interpretation and etc…)
This can typically be done with the help of machine learning( Although problems are there).
Not much difficult to do and gives good accuracy results.
2. Natural language generation:
The system should be able to respond / generate text (text planning, sentence planning, producing meaningful phrases and etc…)
This can be done with the help of deep learning as deep understanding is required( Although problems are there).
much difficult to do and the results may not be accurate.
so where do we use ML in NLP???
These are the couple of applications where we focus
- Text classification and clustering
- Information retrieval and extraction
- Machine translation(one language to another)
- Question and answering system
- spelling and grammar checking
- Topic modeling and sentiment analysis
- Speech recognition
I will try to explain and complete all the topics in next following stories , in this story we learn the basic fundamentals for text/document which is common for many applications.
Note: Assume now that Text , data, document,sentence and paragraph all are same.
What is a text ??
A text is a set words sequentially written.
Each word in the text has a meaning where the text may or may not have a meaning.
in machine leaning we take features right? so here each word is a feature(unique).
Ex :
Text : I love programming → I , love, programming are the features for this input.
How do we derive the features??
First apply Tokenization (a text is divided into token), we can use open source tools like NLTK to get tokens from the text.

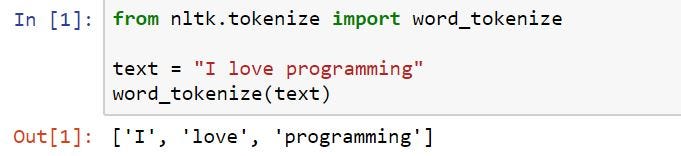
checkout this example


so here we have the programming repeated twice as tokens but we only take once so the features for this text are → I , love, programming, and, also, loves, me.
but wait the words love and loves mean same , these are called inflectional forms. we need to remove these
removing these inflectional endings is called lemmatization

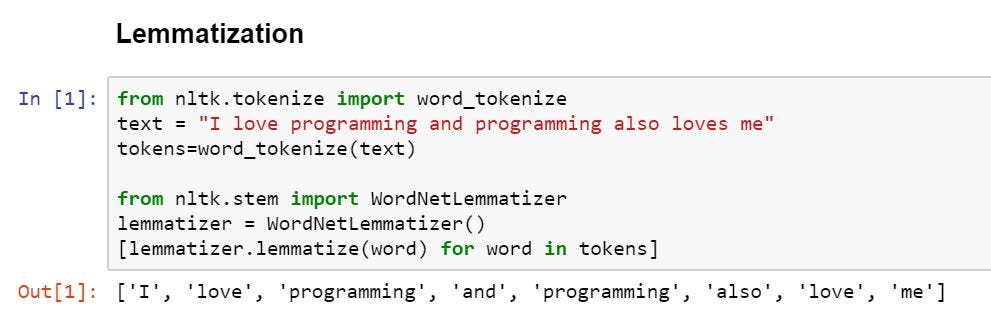
so now the features for this text are → I , love, programming, and, also,me.
we can even think deep and say the word programming is similar to the word program
there is a concept called Steeming
so if we apply steeming then

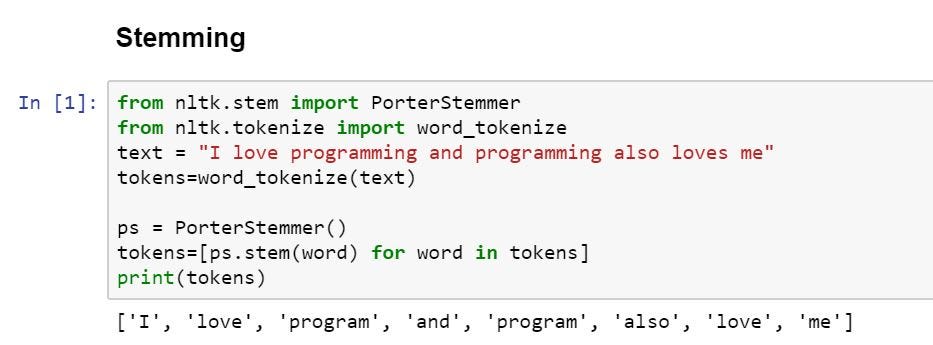
so now the features for this text are → I , love, program, and, also,me.
there are couple of words which occur very frequently in every language and don’t have much meaning , these words are called Stop words.
The stop words in English are